Reverse score specific items given empirical range or specific scoring range.
Arguments
- data
an object of class
data.frame,matrix, ortablewith the response patterns- which
names of items or column integer location in
datathat should be rescored. If missing the all columns indatawill be reverse scored- range
(optional) a named
listto specify the low and high score ranges. Specified names must match the names found indata, and each element of this list should contain only two values. If items specified inwhichare omitted from this list then the empirical min/max information will be used instead- append
character vector indicating what to append to the item names that have been rescored
Value
returns the original data object with the specified
items reverse scored replacing the original scoring scheme
References
Chalmers, R. P. (2012). mirt: A Multidimensional Item Response Theory Package for the R Environment. Journal of Statistical Software, 48(6), 1-29. doi:10.18637/jss.v048.i06
Author
Phil Chalmers rphilip.chalmers@gmail.com
Examples
a <- rlnorm(20)
a[c(1,5,10)] <- -a[c(1,5,10)]
diffs <- t(apply(matrix(runif(20*4, .3, 1), 20), 1, cumsum))
diffs <- -(diffs - rowMeans(diffs))
d <- diffs + rnorm(20)
dat <- simdata(a,d,itemtype='graded', N=300)
head(dat)
#> Item_1 Item_2 Item_3 Item_4 Item_5 Item_6 Item_7 Item_8 Item_9 Item_10
#> [1,] 0 1 4 4 0 3 4 4 4 2
#> [2,] 1 1 4 4 0 3 4 2 3 2
#> [3,] 0 3 4 4 0 1 4 4 4 4
#> [4,] 4 3 4 4 0 0 4 4 3 4
#> [5,] 3 3 2 1 0 0 4 1 4 4
#> [6,] 4 3 0 4 4 0 0 4 3 4
#> Item_11 Item_12 Item_13 Item_14 Item_15 Item_16 Item_17 Item_18 Item_19
#> [1,] 1 4 4 4 4 3 4 4 4
#> [2,] 0 0 4 2 4 0 0 2 3
#> [3,] 0 4 4 4 4 4 4 2 4
#> [4,] 0 0 2 4 3 4 4 2 2
#> [5,] 1 4 0 2 0 4 3 4 3
#> [6,] 3 1 0 0 3 0 0 0 3
#> Item_20
#> [1,] 4
#> [2,] 4
#> [3,] 0
#> [4,] 3
#> [5,] 1
#> [6,] 0
# \donttest{
# fitted model has negative slopes due to flipped scoring
mod <- mirt(dat)
coef(mod, simplify=TRUE)$items
#> a1 d1 d2 d3 d4
#> Item_1 -1.7883098 2.31995288 1.4499834 1.07726421 0.4510197
#> Item_2 1.0769866 0.36191208 -0.4796053 -0.77937162 -1.9037988
#> Item_3 2.0870495 0.89367114 0.4259646 -0.35856200 -1.0589551
#> Item_4 1.0650652 2.30861621 1.6791993 1.13148980 0.4942154
#> Item_5 -11.4060505 1.73798765 1.0440471 -0.16089560 -1.0876508
#> Item_6 0.2942558 0.94241730 0.3792134 -0.10333893 -0.8226098
#> Item_7 4.1129557 0.87257493 0.1039055 -0.41943179 -1.0620040
#> Item_8 0.1449906 1.97055826 1.2737632 0.63847030 0.4085881
#> Item_9 0.4696289 1.27148178 0.3775533 0.01052184 -0.9478330
#> Item_10 -0.3739309 0.76112262 0.4617020 0.04222674 -0.2764863
#> Item_11 0.2515094 0.01994729 -0.2106310 -0.90307832 -1.5791507
#> Item_12 4.2893751 -0.01594705 -0.5478900 -0.77386779 -1.0680246
#> Item_13 2.5148791 -0.42978095 -1.0988879 -1.53643200 -2.4275679
#> Item_14 4.5781642 1.56567048 0.4968111 -0.19671080 -0.9985485
#> Item_15 0.3902411 1.83912307 1.3005456 0.66219058 -0.2833309
#> Item_16 1.4550661 -0.66105067 -1.3785125 -1.49246863 -2.2246198
#> Item_17 3.5799803 1.30852675 0.7649316 0.16509885 -0.7689310
#> Item_18 2.5408922 0.96129403 0.5650282 -0.43645974 -0.7919668
#> Item_19 1.5596373 1.30292181 0.6382722 0.03209491 -0.7689053
#> Item_20 1.1586202 0.79856397 0.1092070 -0.26714791 -0.7051084
plot(mod, type = 'itemscore')
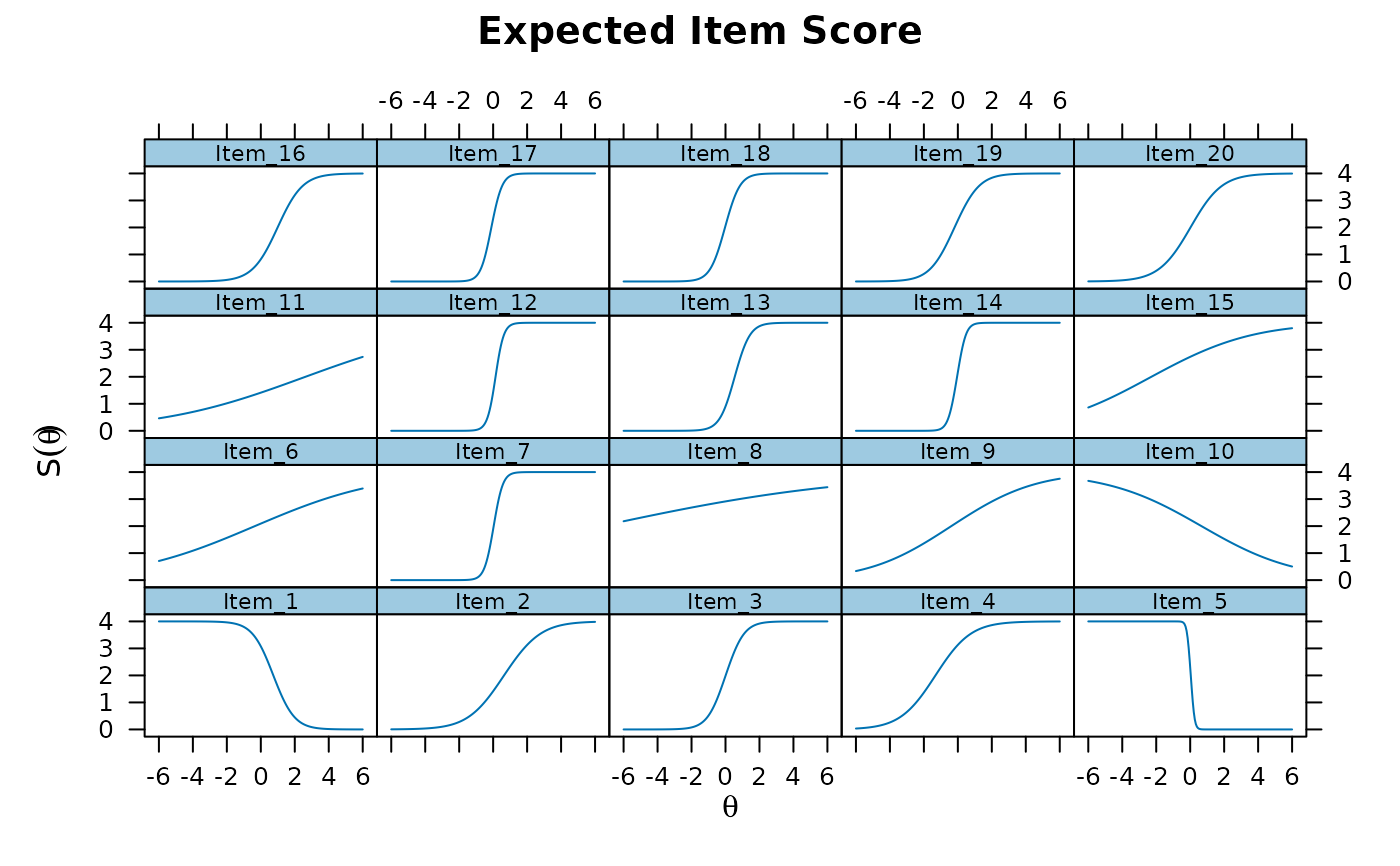 # }
# reverse the scoring for items 1, 5, and 10 only using empirical min/max
revdat <- reverse.score(dat, c('Item_1', 'Item_5', 'Item_10'))
head(revdat)
#> Item_1.RS Item_2 Item_3 Item_4 Item_5.RS Item_6 Item_7 Item_8 Item_9
#> [1,] 4 1 4 4 4 3 4 4 4
#> [2,] 3 1 4 4 4 3 4 2 3
#> [3,] 4 3 4 4 4 1 4 4 4
#> [4,] 0 3 4 4 4 0 4 4 3
#> [5,] 1 3 2 1 4 0 4 1 4
#> [6,] 0 3 0 4 0 0 0 4 3
#> Item_10.RS Item_11 Item_12 Item_13 Item_14 Item_15 Item_16 Item_17 Item_18
#> [1,] 2 1 4 4 4 4 3 4 4
#> [2,] 2 0 0 4 2 4 0 0 2
#> [3,] 0 0 4 4 4 4 4 4 2
#> [4,] 0 0 0 2 4 3 4 4 2
#> [5,] 0 1 4 0 2 0 4 3 4
#> [6,] 0 3 1 0 0 3 0 0 0
#> Item_19 Item_20
#> [1,] 4 4
#> [2,] 3 4
#> [3,] 4 0
#> [4,] 2 3
#> [5,] 3 1
#> [6,] 3 0
# compare
apply(dat[,c(1,5,10)], 2, table)
#> Item_1 Item_5 Item_10
#> 0 52 135 97
#> 1 32 8 20
#> 2 16 14 30
#> 3 29 10 23
#> 4 171 133 130
apply(revdat[,c(1,5,10)], 2, table)
#> Item_1.RS Item_5.RS Item_10.RS
#> 0 171 133 130
#> 1 29 10 23
#> 2 16 14 30
#> 3 32 8 20
#> 4 52 135 97
# \donttest{
# slopes all positive now
mod2 <- mirt(revdat)
coef(mod2, simplify=TRUE)$items
#> a1 d1 d2 d3 d4
#> Item_1.RS 1.7901718 -0.47020423 -1.09635906 -1.46895051 -2.3387232
#> Item_2 1.0776078 0.35073997 -0.49079883 -0.79052751 -1.9147922
#> Item_3 2.0884401 0.87114963 0.40337312 -0.38093467 -1.0810479
#> Item_4 1.0649146 2.29754853 1.66804690 1.12027064 0.4830812
#> Item_5.RS 11.7687575 0.97113547 0.02139226 -1.21634700 -1.9259345
#> Item_6 0.2943092 0.93944969 0.37623506 -0.10630691 -0.8255798
#> Item_7 4.1171834 0.82635722 0.05814954 -0.46467930 -1.1068153
#> Item_8 0.1451793 1.96909071 1.27229211 0.63699976 0.4071182
#> Item_9 0.4694871 1.26664759 0.37277717 0.00574058 -0.9525291
#> Item_10.RS 0.3742519 0.27270242 -0.04603928 -0.46552604 -0.7649342
#> Item_11 0.2517395 0.01742505 -0.21317429 -0.90562414 -1.5817076
#> Item_12 4.3047387 -0.06511026 -0.59784126 -0.82422241 -1.1185195
#> Item_13 2.5190756 -0.45761311 -1.12678857 -1.56424704 -2.4551758
#> Item_14 4.5744997 1.51157765 0.44372720 -0.24860516 -1.0481648
#> Item_15 0.3904429 1.83522215 1.29664120 0.65827189 -0.2872616
#> Item_16 1.4567669 -0.67657459 -1.39406916 -1.50794145 -2.2400164
#> Item_17 3.5769208 1.26677582 0.72365082 0.12492814 -0.8069567
#> Item_18 2.5421257 0.93354704 0.53733383 -0.46392718 -0.8192254
#> Item_19 1.5594394 1.28637378 0.62177933 0.01574451 -0.7849071
#> Item_20 1.1594008 0.78662321 0.09713840 -0.27921560 -0.7171663
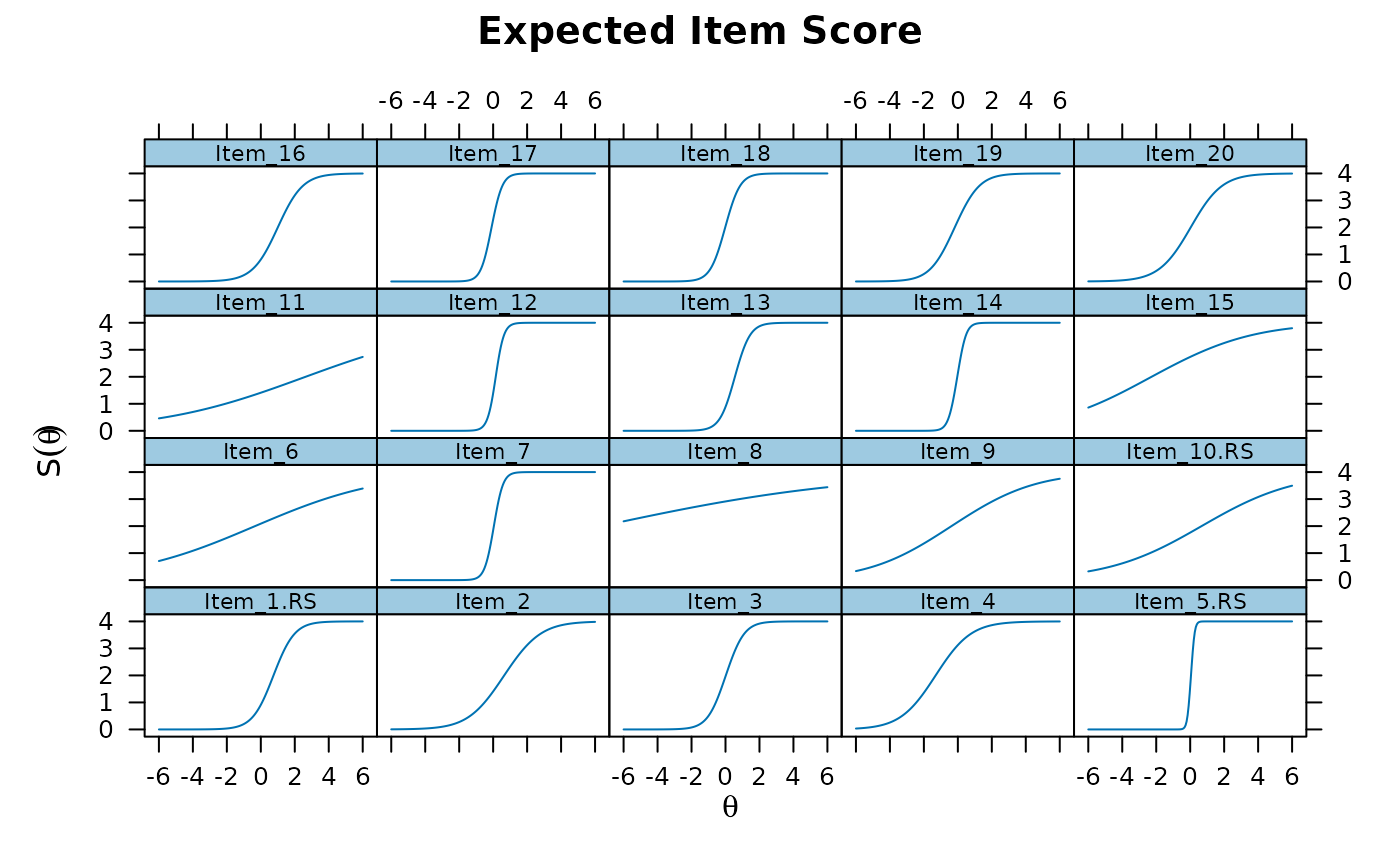
plot(mod2, type = 'itemscore')
# }
# reverse the scoring for items 1, 5, and 10 only using empirical min/max
revdat <- reverse.score(dat, c('Item_1', 'Item_5', 'Item_10'))
head(revdat)
#> Item_1.RS Item_2 Item_3 Item_4 Item_5.RS Item_6 Item_7 Item_8 Item_9
#> [1,] 4 1 4 4 4 3 4 4 4
#> [2,] 3 1 4 4 4 3 4 2 3
#> [3,] 4 3 4 4 4 1 4 4 4
#> [4,] 0 3 4 4 4 0 4 4 3
#> [5,] 1 3 2 1 4 0 4 1 4
#> [6,] 0 3 0 4 0 0 0 4 3
#> Item_10.RS Item_11 Item_12 Item_13 Item_14 Item_15 Item_16 Item_17 Item_18
#> [1,] 2 1 4 4 4 4 3 4 4
#> [2,] 2 0 0 4 2 4 0 0 2
#> [3,] 0 0 4 4 4 4 4 4 2
#> [4,] 0 0 0 2 4 3 4 4 2
#> [5,] 0 1 4 0 2 0 4 3 4
#> [6,] 0 3 1 0 0 3 0 0 0
#> Item_19 Item_20
#> [1,] 4 4
#> [2,] 3 4
#> [3,] 4 0
#> [4,] 2 3
#> [5,] 3 1
#> [6,] 3 0
# compare
apply(dat[,c(1,5,10)], 2, table)
#> Item_1 Item_5 Item_10
#> 0 52 135 97
#> 1 32 8 20
#> 2 16 14 30
#> 3 29 10 23
#> 4 171 133 130
apply(revdat[,c(1,5,10)], 2, table)
#> Item_1.RS Item_5.RS Item_10.RS
#> 0 171 133 130
#> 1 29 10 23
#> 2 16 14 30
#> 3 32 8 20
#> 4 52 135 97
# \donttest{
# slopes all positive now
mod2 <- mirt(revdat)
coef(mod2, simplify=TRUE)$items
#> a1 d1 d2 d3 d4
#> Item_1.RS 1.7901718 -0.47020423 -1.09635906 -1.46895051 -2.3387232
#> Item_2 1.0776078 0.35073997 -0.49079883 -0.79052751 -1.9147922
#> Item_3 2.0884401 0.87114963 0.40337312 -0.38093467 -1.0810479
#> Item_4 1.0649146 2.29754853 1.66804690 1.12027064 0.4830812
#> Item_5.RS 11.7687575 0.97113547 0.02139226 -1.21634700 -1.9259345
#> Item_6 0.2943092 0.93944969 0.37623506 -0.10630691 -0.8255798
#> Item_7 4.1171834 0.82635722 0.05814954 -0.46467930 -1.1068153
#> Item_8 0.1451793 1.96909071 1.27229211 0.63699976 0.4071182
#> Item_9 0.4694871 1.26664759 0.37277717 0.00574058 -0.9525291
#> Item_10.RS 0.3742519 0.27270242 -0.04603928 -0.46552604 -0.7649342
#> Item_11 0.2517395 0.01742505 -0.21317429 -0.90562414 -1.5817076
#> Item_12 4.3047387 -0.06511026 -0.59784126 -0.82422241 -1.1185195
#> Item_13 2.5190756 -0.45761311 -1.12678857 -1.56424704 -2.4551758
#> Item_14 4.5744997 1.51157765 0.44372720 -0.24860516 -1.0481648
#> Item_15 0.3904429 1.83522215 1.29664120 0.65827189 -0.2872616
#> Item_16 1.4567669 -0.67657459 -1.39406916 -1.50794145 -2.2400164
#> Item_17 3.5769208 1.26677582 0.72365082 0.12492814 -0.8069567
#> Item_18 2.5421257 0.93354704 0.53733383 -0.46392718 -0.8192254
#> Item_19 1.5594394 1.28637378 0.62177933 0.01574451 -0.7849071
#> Item_20 1.1594008 0.78662321 0.09713840 -0.27921560 -0.7171663
plot(mod2, type = 'itemscore')
 # }
# use different empirical scoring information due to options not used
# 0 score not observed for item 1, though should have been rescored to a 4
dat[dat[,1] == 0, 1] <- 1
table(dat[,1])
#>
#> 1 2 3 4
#> 84 16 29 171
# 4 score not observed for item 5, though should have been rescored to a 0
dat[dat[,5] == 4, 5] <- 3
table(dat[,5])
#>
#> 0 1 2 3
#> 135 8 14 143
# specify theoretical scoring values in the range list
revdat2 <- reverse.score(dat, c('Item_1', 'Item_5', 'Item_10'),
range = list(Item_1 = c(0,4), Item_5 = c(0,4)))
head(revdat2)
#> Item_1.RS Item_2 Item_3 Item_4 Item_5.RS Item_6 Item_7 Item_8 Item_9
#> [1,] 4 1 4 4 4 3 4 4 4
#> [2,] 4 1 4 4 4 3 4 2 3
#> [3,] 4 3 4 4 4 1 4 4 4
#> [4,] 1 3 4 4 4 0 4 4 3
#> [5,] 2 3 2 1 4 0 4 1 4
#> [6,] 1 3 0 4 1 0 0 4 3
#> Item_10.RS Item_11 Item_12 Item_13 Item_14 Item_15 Item_16 Item_17 Item_18
#> [1,] 2 1 4 4 4 4 3 4 4
#> [2,] 2 0 0 4 2 4 0 0 2
#> [3,] 0 0 4 4 4 4 4 4 2
#> [4,] 0 0 0 2 4 3 4 4 2
#> [5,] 0 1 4 0 2 0 4 3 4
#> [6,] 0 3 1 0 0 3 0 0 0
#> Item_19 Item_20
#> [1,] 4 4
#> [2,] 3 4
#> [3,] 4 0
#> [4,] 2 3
#> [5,] 3 1
#> [6,] 3 0
table(dat[,1])
#>
#> 1 2 3 4
#> 84 16 29 171
table(revdat2[,1])
#>
#> 1 2 3 4
#> 171 29 16 84
table(dat[,5])
#>
#> 0 1 2 3
#> 135 8 14 143
table(revdat2[,5])
#>
#> 1 2 3 4
#> 143 14 8 135
# }
# use different empirical scoring information due to options not used
# 0 score not observed for item 1, though should have been rescored to a 4
dat[dat[,1] == 0, 1] <- 1
table(dat[,1])
#>
#> 1 2 3 4
#> 84 16 29 171
# 4 score not observed for item 5, though should have been rescored to a 0
dat[dat[,5] == 4, 5] <- 3
table(dat[,5])
#>
#> 0 1 2 3
#> 135 8 14 143
# specify theoretical scoring values in the range list
revdat2 <- reverse.score(dat, c('Item_1', 'Item_5', 'Item_10'),
range = list(Item_1 = c(0,4), Item_5 = c(0,4)))
head(revdat2)
#> Item_1.RS Item_2 Item_3 Item_4 Item_5.RS Item_6 Item_7 Item_8 Item_9
#> [1,] 4 1 4 4 4 3 4 4 4
#> [2,] 4 1 4 4 4 3 4 2 3
#> [3,] 4 3 4 4 4 1 4 4 4
#> [4,] 1 3 4 4 4 0 4 4 3
#> [5,] 2 3 2 1 4 0 4 1 4
#> [6,] 1 3 0 4 1 0 0 4 3
#> Item_10.RS Item_11 Item_12 Item_13 Item_14 Item_15 Item_16 Item_17 Item_18
#> [1,] 2 1 4 4 4 4 3 4 4
#> [2,] 2 0 0 4 2 4 0 0 2
#> [3,] 0 0 4 4 4 4 4 4 2
#> [4,] 0 0 0 2 4 3 4 4 2
#> [5,] 0 1 4 0 2 0 4 3 4
#> [6,] 0 3 1 0 0 3 0 0 0
#> Item_19 Item_20
#> [1,] 4 4
#> [2,] 3 4
#> [3,] 4 0
#> [4,] 2 3
#> [5,] 3 1
#> [6,] 3 0
table(dat[,1])
#>
#> 1 2 3 4
#> 84 16 29 171
table(revdat2[,1])
#>
#> 1 2 3 4
#> 171 29 16 84
table(dat[,5])
#>
#> 0 1 2 3
#> 135 8 14 143
table(revdat2[,5])
#>
#> 1 2 3 4
#> 143 14 8 135