Distributing jobs for high-performance computing (HPC) clusters (e.g., via Slurm)
Phil Chalmers
2026-07-14
Source:vignettes/HPC-computing.Rmd
HPC-computing.RmdIntroduction
The purpose of this vignette is to demonstrate how to utilize
SimDesign in the context of distributing many jobs across
independent computing environments, such as high-performance computing
(HPC) clusters, in a way that allows for reproducibility of the
simulation conditions, resubmission of jobs in case of incomplete
collection of results within a specified HPC execution time budget, and
to ensure that random number generation across the entire simulation
(and subsequent resubmissions, if required) are properly manged
throughout given the batch nature of the job. The following text and
examples are primarily for managing larger simulations, often with
thousands of replications over many simulation conditions (i.e., rows in
the defined design object) which generally require
non-trivial amounts of computing resources to execute (hence, the need
for super-computing resources and job schedulers like Slurm, TORQUE,
MAUI, among others).
For information about Slurm’s Job Array support in particular, which this vignette uses as an example, see https://slurm.schedmd.com/job_array.html
Standard setup on HPC cluster
To start, the structure of the simulation code used later on to
distribute the jobs to the HPC scheduler is effectively the same as the
usual generate-analyse-summarise workflow described in
runSimulation(), with a few organizational exceptions. As
such, this is always a good place to start when designing, testing, and
debugging a simulation experiment before submitting to HPC clusters.
IMPORTANT: Only after the vast majority of the bugs and coding logic have been work out should you consider moving on to the next step involving HPC clusters. If your code is not well vetted in this step then any later jobs evaluated on the HPC cluster will be a waste of time and resources (garbage-in, garbage-out).
Example
Suppose the following simulation was to be evaluated, though for time constraint reasons would not be possible to execute on a single computer (or a smaller network of computers) and therefore should be submitted to an HPC cluster.
The following script (hypothetically written in a file called
SimDesign_simulation.R) contains a simulation experiment
whose instructions are to be submitted to the Slurm scheduler. To do so,
the sbatch utility is used along with the set of
instructions specifying the type of hardware required in the file
slurmInstructions.slurm. In the R side of the simulation,
the defined code must grab all available cores (minus 1) that are
detectable via parallelly::availableCores(), which occurs
automatically when using
runSimulation(..., parallel=TRUE).
# SimDesign::SimFunctions()
library(SimDesign)
Design <- createDesign(N = c(10, 20, 30))
Generate <- function(condition, fixed_objects) {
dat <- with(condition, rnorm(N, 10, 5)) # distributed N(10, 5)
dat
}
Analyse <- function(condition, dat, fixed_objects) {
ret <- c(mean=mean(dat), median=median(dat)) # mean/median of sample data
ret
}
Summarise <- function(condition, results, fixed_objects){
colMeans(results)
}
# standard setup (not ideal for HPC clusters as parallelization
# occurs within the design conditions, not across)
res <- runSimulation(design=Design, replications=10000, generate=Generate,
analyse=Analyse, summarise=Summarise, parallel=TRUE,
filename='mysim')In the standard runSimulation(..., parallel=TRUE) setup
the 10,000 replications would be distributed to the available computing
cores and evaluated independently across the three row conditions in the
design object. However, this process is only executed in
sequence: design[1, ] is evaluated first and, only after
the 10,000 replications are collected, design[2, ] is
evaluated until it is complete, then design[3, ], and so
on.
As well, in order for this approach to be at all optimal the HPC
cluster must assign a job containing a very large number of resources;
specifically, higher RAM and CPUs. To demonstrate, in the following
slurmInstructions.slurm file a larger number of CPUs are
requested when allocating the computational structure/cluster associated
with this job, as well as larger amounts of RAM.
#!/bin/bash
#SBATCH --job-name="My simulation (multiple CPUs)"
#SBATCH --mail-type=ALL
#SBATCH --mail-user=somewhere@out.there
#SBATCH --output=/dev/null ## (optional) delete .out files
#SBATCH --time=12:00:00 ## HH:MM:SS
#SBATCH --cpus-per-task=96 ## Build a computer with 96 cores
#SBATCH --mem-per-cpu=2G ## Build a computer with 192GB of RAM
module load r
Rscript --vanilla SimDesign_simulation.RThis job request a computing cluster be built with 192 GB of RAM with
96 CPUs (across whatever computing nodes are available; likely 2 or
more), which the SimDesign_simulation.R is evaluated in,
and is submitted to the scheduler via
sbatch slurmInstructions.slurm.
Limitations
While generally effective at distributing the computational load, there are a few limitations of the above approach:
- For simulations with varying execution times this will create a
great deal of resource waste.
- Due to the row-evaluation nature of the
designconditions, computing cores will at some point sit idle while waiting for the remaining experiments to complete their job. This occurs for each row in thedesigninput (i.e., per simulation condition) - As such, simulation experiments with many conditions to evaluate will suffer most due to the rolling overhead, resulting in wasted resource management (not kind to other users of the HPC cluster) and ultimately results in jobs that take longer to complete
- Due to the row-evaluation nature of the
- Designers must first estimate the number of total amount of
CPUs/RAM/time required, while being as conservative as possible
- Problematic because fewer resource jobs are given higher priority in the scheduler, and because you may be taking resources away from other researchers if the cores sit idle
- Parallel distribution across the allocated resources (e.g., across
two nodes, both with 48 cores) incurs some overhead that grows as a
function of the size of the defined cluster
- Using a 96 CPU cluster will not result in a 96x speedup of a 1 CPU job. In fact, the larger the allocated cluster, the worse the performance efficiency
- The scheduler must wait until all resources (e.g., RAM and CPUs)
simultaneously become available to allocate the requested
specifications, which can take a good amount of time to allocate if the
resources requested are excessively high (hence, become low
priority on the scheduler)
- If you request 96 CPUs with 192 GB of RAM then this will take considerably longer to allocate compared to requesting 96 independent computing arrays with 1 CPU and 2 GB of RAM (the latter approach is described in the next section)
- In concert with point 3), this results in jobs that a) take longer to get started as they will sit longer in the queue and b) may not distribute the load efficiently enough, thereby resulting in larger wall time then should have been necessary
- Submitting independent multiple batches to the cluster makes it more
difficult to guarantee the quality of the random numbers
- Setting the
seedfor each condition ensure that within eachdesigncondition the random numbers are high quality, however there is no guarantee that repeated use ofset.seed()will result in high-quality random numbers (see next section for example) - Hence, repeated job submissions of this type, even with unique seeds
per condition, may not generate high quality numbers if repeated too
many times (alternative is to isolate each
designrow and submit each row as a unique job, which is demonstrated near the end of this vignette) - Note that there are workarounds with more recent
runSimulation()implementations when combined withexpandDesign()(see below), however given the nature of the complete job submission these remain less ideal
- Setting the
- Finally, and perhaps most problematic in simulation experiment
applications, schedulers frequently cap the maximum number of resources
that can be requested (e.g., 256 GB of RAM, 200 CPUs), which limits the
application of large RAM and CPU jobs
- Note that to avoid wasting time by swapping/paging, schedulers will never allocate jobs whose memory requirements exceed the amount of available memory
To address these and other computational inefficiencies/wasted resources, one can instead switch from the cluster-based approach above to an array distribution approach, discussed in the next section.
Array jobs
For HPC computing it is often more optimal to distribute both
replications and conditions simultaneously to unique computing
nodes (termed arrays) to effectively break the problem
in several mini-batches (e.g., split the simulation into 1000+
independent pieces, and collect the results later). As such, the above
design object and runSimulation() structure
above does not readily lend itself to optimal distribution for the array
scheduler to manage. Nevertheless, the core components are still useful
for initial code design, testing, and debugging, and therefore serve as
a necessary first step when writing simulation experiment code prior to
submitting to an HPC cluster.
After defining and testing your simulation to ensure that it works as
expected, it now comes the time to setup the components required for
organizing the HPC cluster submission using the
runArraySimulation() function.
Converting runSimulation() workflow to one for
runArraySimulation()
The job of runArraySimulation() is to utilize the
relevant information defined in the .sh or
.slurm script. This is done by extracting information
provided by the scheduler (specifically, via an arrayID),
which is used to select specific subsets of the design
rows. However, unlike runSimulation() the function
runArraySimulation() has been designed to control important
information pertaining to .Random.seeds and other relevant
distribution information that allow for the rows in the
design object itself to contain repeated
experimental condition information. This allows both the
design rows and replication
information to be optimally distributed to the HPC cluster.
The following example presents the essential modifications required
to move from a single runSimulation() workflow to a batch
workflow suitable for runArraySimulation() and Slurm
scheduler.
Expand the standard simulation design object for each
array ID
Suppose that 300 computing cores were independently available on the
HPC cluster, though the availability of these cores only trickle in as a
function of the schedulers decided availability. In this case, the
strategy would be to split up the 3 * 10000 = 30000
condition-by-replications experiments across the gradually available
resources, where jobs are evaluated in parallel and at different
times.
Given the above specifications, you may decide that each of the 300
computing nodes requested to the scheduler should evaluate exactly 100
replications each (nrow(design) * 10000 / 300 = 100). In
this case, expandDesign() is used to repeat each row
condition 100 times, creating a new expanded
design object with 300 rows instead of 3. To accommodate
for the new rows, the associated replications should now be
defined according to how many replications should be used within each of
these to-be-distributed conditions, which need not be equal (see
below).
rc <- 100 # number of times the design row was repeated
Design300 <- expandDesign(Design, repeat_conditions = rc)
Design300## # A tibble: 300 × 1
## N
## <dbl>
## 1 10
## 2 10
## 3 10
## 4 10
## 5 10
## 6 10
## 7 10
## 8 10
## 9 10
## 10 10
## # ℹ 290 more rows
# compare the Design.IDs
print(Design, show.IDs = TRUE)## # A tibble: 3 × 2
## Design.ID N
## <int> <dbl>
## 1 1 10
## 2 2 20
## 3 3 30
print(Design300, show.IDs = TRUE)## # A tibble: 300 × 2
## Design.ID N
## <int> <dbl>
## 1 1 10
## 2 1 10
## 3 1 10
## 4 1 10
## 5 1 10
## 6 1 10
## 7 1 10
## 8 1 10
## 9 1 10
## 10 1 10
## # ℹ 290 more rows
# target replication number for each condition
rep_target <- 10000
# replications per row in Design300
replications <- expandReplications(rep_target, repeat_conditions = rc)
replications## [1] 100The above approach assumes that each design condition is
equally balanced in terms of computing time and resources, though if
this is not the case (e.g., the last condition contains notably higher
computing times than the first two conditions) then
repeat_conditions can be specified as a vector instead,
such as repeat_conditions = c(100, 100, 1000), which for
the latter portion would be associated with a 10 replications per
distributed node instead of 100.
rc <- c(100, 100, 1000)
DesignUnbalanced <- expandDesign(Design, repeat_conditions = rc)
DesignUnbalanced## # A tibble: 1,200 × 1
## N
## <dbl>
## 1 10
## 2 10
## 3 10
## 4 10
## 5 10
## 6 10
## 7 10
## 8 10
## 9 10
## 10 10
## # ℹ 1,190 more rows
rep_target <- 10000
replicationsUnbalanced <- expandReplications(rep_target, rc)
head(replicationsUnbalanced)## [1] 100 100 100 100 100 100
tail(replicationsUnbalanced)## [1] 10 10 10 10 10 10
table(replicationsUnbalanced)## replicationsUnbalanced
## 10 100
## 1000 200Regardless of whether the expanded design is balanced or unbalanced each row in the resulting expanded design object will be assigned to a unique computing array node, identified according to the Slurm assigned array ID.
Construct and record proper random seeds
In principle, the expanded Design300 object above could
be passed as
runSimulation(Design300, replications=100, ...) to evaluate
each of the repeated conditions, where each row is now replicated only
100 times. However, there is now an issue with respect to the random
seed management in that use of functions such as set.seed()
and friends are no longer viable. This is because repeated use of
set.seed() does not itself guarantee independent
high-quality random numbers between different instances. For
example,
plot(x[-1], y[-100]) ## subsets perfectly correlated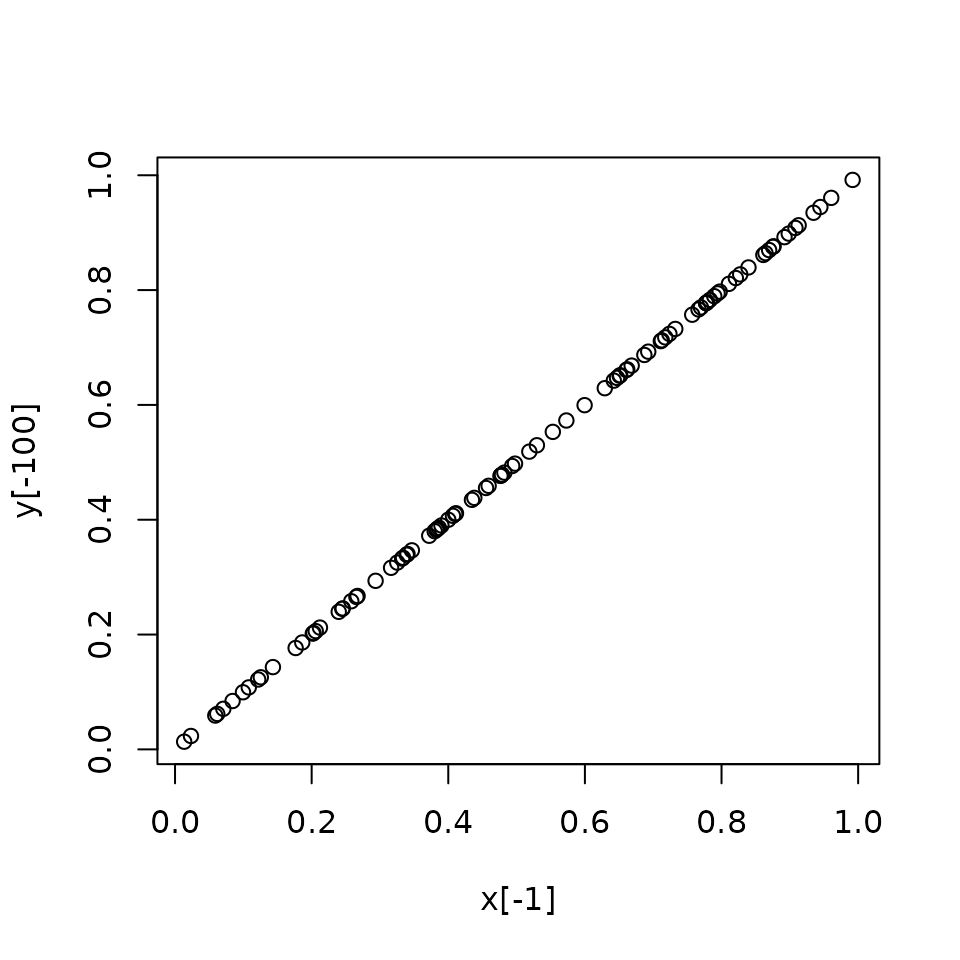
This issue is generally not problem in the standard
runSimulation() approach as within each design condition
high quality random numbers are used by default, and any potentially
repeated number sequences across the conditions are highly
unlikely to affect the quality of the overall simulation experiment (the
conditions themselves typically generate and manage random numbers in
different ways due to the varying simulation factors, such as sample
sizes, variance conditions, fitted models, number of variables, type of
probability distributions use, and so on). However, in the
expandDesign() setup the likelihood of witnessing
correlated/redundant random samples increases very quickly, which is
particularly problematic within each distributed replication set; hence,
special care must be taken to ensure that proper seeds are distributed
to each job array.
Fortunately, seeds are easy to manage with the
genSeeds() function using a two-step approach, which is
internally managed by runArraySimulation() by supplying an
initial seed (iseed) value and the associated array ID
(arrayID). Doing so will utilize L’Ecuyer’s (1999) method,
which constructs sequentially computed .Random.seed states
to ensure independence across all replications and conditions. Note that
iseed must constant across all job arrays, so make
sure to define iseed once and only once!
# genSeeds() # do this once on the main node/home computer and store the number!
iseed <- 1276149341As discussed in the FAQ section at the bottom, this associated value
will also allow for generation of new .Random.seed elements
if (or when) a second or third set of simulation jobs should be
submitted to the HPC cluster at a later time but must also generate
simulated data that is independent from the initial submission(s).
Extract array ID information from the .slurm
script
When submitting to the HPC cluster you’ll need to include information
about how the scheduler should distribute the simulation experiment to
the workers. In Slurm systems, you may have a script such as the
following, stored into a suitable .slurm file:
#!/bin/bash
#SBATCH --job-name="My simulation (array jobs, distributing conditions + replications)"
#SBATCH --mail-type=ALL
#SBATCH --mail-user=somewhere@out.there
#SBATCH --output=/dev/null ## (optional) delete .out files
#SBATCH --time=12:00:00 ## HH:MM:SS
#SBATCH --mem-per-cpu=4G ## 4GB of RAM per cpu
#SBATCH --cpus-per-task=1
#SBATCH --array=1-300 ## Slurm schedulers often allow up to 10,000 arrays
module load r
Rscript --vanilla mySimDesignScript.RFor reference later, label this file simulation.slurm as
this is the file that must be submitted to the scheduler when it’s
time.
The top part of this .slurm file provides the BASH
instructions for the Slurm scheduler via the #SBATCH
statements. In this case, how many array jobs to queue (1 through 300),
how much memory to use per job (2GB), time limits (12 hours), and more;
see here for SBATCH
details.
The most important input to focus on in this context is
#SBATCH –array=1-300 as this is what is used by the
Slurm scheduler to assign a unique ID to each array job. What the
scheduler does is take the defined mySimDesignScript.R
script and send this to 300 independent resources (each with 1 CPU and
4GB of RAM, in this case), where the independent jobs are assigned a
unique array ID number within the --array=1-300 range
(e.g., distribution to the first computing resource would be assigned
arrayID=1, the second resource arrayID=2, and
so on). In the runArraySimulation() function this is used
to subset the Design300 object by row; hence, the array
range must correspond to the row identifiers in the design
object for proper subsetting!
Collecting this single number assigned by the Slurm scheduler is also easy. Just include
# get assigned array ID (default uses type = 'slurm')
arrayID <- getArrayID()to obtain the associated array ID, which is this example will be a
single integer value between 1 and 300. This value is used
in the final execution step via
runArraySimulation(..., arrayID=arrayID), which we finally
turn to.
Organize information for runArraySimulation()
With all the prerequisite steps in place we’re finally ready to pass
all information to runArraySimulation(), which is
effectively a wrapper to runSimulation() that suppresses
verbose outputs, takes subsets of the Design300 object
given the supplied arrayID (and other objects, such as
replications, seeds, etc), forces evaluation
on a single CPU (hence, #SBATCH --cpus-per-task=1 should be
used by default, unless there is further parallelization to occur within
the replications, such as via OpenMP), manages the random
number generation seeds in a tractable way, and saves the
SimDesign results to file names based on the
filename argument with suffixes associated with the
arrayID (e.g., filename='mysim' will save the
files mysim-1.rds for array 1, mysim-2.rds for
array 2, …, mysim-300.rds for array 300).
# run the simulation on subset based on arrayID subset information
runArraySimulation(design=Design300, replications=replications,
generate=Generate, analyse=Analyse,
summarise=Summarise, iseed=iseed,
arrayID=arrayID, filename='mysim')And that’s it!
The above will store all the mysim-#.rds files in the
directory where the job was submitted, which is somewhat on the messy
side, so you may also want to specify a directory name to store the
simulation files to. Hence, on the main (i.e., landing) location
associated with your ssh account create a directory, using
something like mkdir mysimfiles (or in R,
dir.create('mysimfiles')) in the location where your
.R and .slurm files are stored. Then the
following can be used to store all 300 collected .rds
files, making use of the dirname argument.
# run the simulation on subset based on arrayID subset information
runArraySimulation(design=Design300, replications=replications,
generate=Generate, analyse=Analyse,
summarise=Summarise, iseed=iseed, arrayID=arrayID,
dirname='mysimfiles', filename='mysim')Regardless, the hard part is done here, though other information
could be included by way of the control list input if
necessary, such as including explicit time/resource limits in the R
executions within array jobs themselves (see the FAQ section for further
information).
Putting it all together
Below is the complete submission script collecting everything that was presented above. This assumes that
- The
.Rfile with the simulation code is stored in the filemySimDesignScript.R, - A suitable Slurm instruction file has been created in the file
simulation.slurm, which points tomySimDesignScript.Rand includes the relevantRmodules, and - A directory called
mysimfiles/has been created for storing the files on the computer used to submit the array job
library(SimDesign)
Design <- createDesign(N = c(10, 20, 30))
Generate <- function(condition, fixed_objects) {
dat <- with(condition, rnorm(N, 10, 5)) # distributed N(10, 5)
dat
}
Analyse <- function(condition, dat, fixed_objects) {
ret <- c(mean=mean(dat), median=median(dat)) # mean/median of sample data
ret
}
Summarise <- function(condition, results, fixed_objects){
colMeans(results)
}
# expand the design to create 300 rows with associated replications
rc <- 100
Design300 <- expandDesign(Design, repeat_conditions = rc)
rep_target <- 10000
replications <- expandReplications(rep_target, repeat_conditions = rc)
# genSeeds() # do this once on the main node/home computer, and store the number!
iseed <- 1276149341
# get assigned array ID (default uses type = 'slurm')
arrayID <- getArrayID()
# run the simulation on subset based on arrayID subset information
runArraySimulation(design=Design300, replications=replications,
generate=Generate, analyse=Analyse,
summarise=Summarise, iseed=iseed, arrayID=arrayID,
dirname='mysimfiles', filename='mysim')This file is then submitted to the job scheduler via
sbatch, pointing to the .slurm
instructions.
sbatch simulation.slurmOnce complete you can now go get a beer, coffee, or whatever else tickles your fancy to celebrate as the hard part is over.
Post-evaluation: Combine the files
After some time has elapsed, and the job evaluation is now complete,
you’ll have access to the complete set of simulation files store in the
file names mysim-#.rds. The final step in this process is
then to collect all independent results into a simulation object that
resembles what would have been returned from the canonical
runSimulation() function. Fortunately, this is easy to do
with SimCollect(). All you must do at this point is point
to the working directory containing the simulation files and use
SimCollect():
library(SimDesign)
# automatically checks whether all saved files are present via SimCheck()
Final <- SimCollect('mysimfiles/')
Final# A tibble: 3 × 8
N mean median REPLICATIONS SIM_TIME COMPLETED
<dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 10 9.9973 9.9934 10000 23.42s Thu Apr 4 11:50:11 2024
2 20 10.007 10.015 10000 24.24s Thu Apr 4 11:50:35 2024
3 30 10.003 10.007 10000 24.39s Thu Apr 4 11:51:00 2024This function detects which Design300 rows belong to the
original Design object, collapse the meta-statistic
results, and stored results information accordingly. No
fuss, no mess. Of course, you’ll want to store this object for later use
as this is the complete collection of the results from the 300 array
jobs, organized into one neat little (object) package.
# save the aggregated simulation object for subsequent analyses
saveRDS(Final, "../final_sim.rds")You should now consider moving this "final_sim.rds" off
the Slurm landing node and onto your home computer via scp
or your other favourite method (e.g., using WinSCP on
Windows). You could also move all the saved *.rds files off
your ssh landing in case there is need to inspect these files further
(e.g., for debugging purposes).
Array jobs and multicore computing simultaneously
Of course, nothing really stops you from mixing and matching the
above ideas related to multicore computing and array jobs on Slurm and
other HPC clusters. For example, if you wanted to take the original
design object and submit batches of these instead (e.g.,
submit one or more rows of the design object as an array
job), where within each array multicore processing is requested, then
something like the following would work:
#!/bin/bash
#SBATCH --job-name="My simulation (arrays + multiple CPUs)"
#SBATCH --mail-type=ALL
#SBATCH --mail-user=somewhere@out.there
#SBATCH --output=/dev/null ## (optional) delete .out files
#SBATCH --time=04:00:00 ## HH:MM:SS
#SBATCH --mem-per-cpu=4G ## Build a computing cluster with 64GB of RAM
#SBATCH --cpus-per-task=16 ## 16 CPUs per array, likely built from 1 node
#SBATCH --array=1-9 ## 9 array jobs
module load r
Rscript --vanilla mySimDesignScript.Rwith the associated .R file containing, in this case,
nine simulation conditions across the rows in Design.
library(SimDesign)
Design <- createDesign(N = c(10, 20, 30),
SD = c(1,2,3))
Generate <- function(condition, fixed_objects) {
dat <- with(condition, rnorm(N, 10, sd=SD)) # distributed N(10, 5)
dat
}
Analyse <- function(condition, dat, fixed_objects) {
ret <- c(mean=mean(dat), median=median(dat)) # mean/median of sample data
ret
}
Summarise <- function(condition, results, fixed_objects){
colMeans(results)
}
Design## # A tibble: 9 × 2
## N SD
## <dbl> <dbl>
## 1 10 1
## 2 20 1
## 3 30 1
## 4 10 2
## 5 20 2
## 6 30 2
## 7 10 3
## 8 20 3
## 9 30 3Depending on the intensity of the conditions, you may choose to
distribute more than one row of the Design object to each
array (multirow=TRUE in the following), otherwise the more
natural choice is to distribute each row in the Design
object to each assigned array.
# get array ID
arrayID <- getArrayID()
multirow <- FALSE # submit multiple rows of Design object to array?
if(multirow){
# If selecting multiple design rows per array, such as the first 3 rows,
# then next 3 rows, and so on, something like the following would work
## For arrayID=1, rows 1 through 3 are evaluated
## For arrayID=2, rows 4 through 6 are evaluated
## For arrayID=3, rows 7 through 9 are evaluated
array2row <- function(arrayID) 1:3 + 3 * (arrayID-1)
} else {
# otherwise, use one row per respective arrayID
array2row <- function(arrayID) arrayID
}
# Make sure parallel=TRUE flag is on to use all available cores!
runArraySimulation(design=Design, replications=10000,
generate=Generate, analyse=Analyse, summarise=Summarise,
iseed=iseed, dirname='mysimfiles', filename='mysim',
parallel=TRUE, arrayID=arrayID, array2row=array2row) When complete, the function SimCollect() can again be
used to put the simulation results together given the nine saved files
(nine files would also saved were multirow set to
TRUE and #SBATCH --array=1-3 were used instead
as these are stored on a per-row basis).
This type of hybrid approach is a middle ground between submitting
the complete job (top of this vignette) and the condition +
replication distributed load in the previous section,
though has similar overhead + inefficiency issues as before (though less
so, as the array jobs are evaluated independently). Note
that if the row’s take very different amounts of time to evaluate then
this strategy can prove less efficient (e.g., the first two rows may
take 2 hours to complete, while the third row may take 12 hours to
complete), in which case a more nuanced array2row()
function should be defined to help explicit balance the load on the
computing cluster.
Extra information (FAQs)
Helpful Slurm commands
In addition to using sbatch to submit jobs, the
following contains other useful Slurm commands.
sbatch <jobfile.slurm> # submit job file to Slurm scheduler
squeue -u <username> # what jobs are currently queued/running for a specific user
sshare -U <username> # check the share usage for a specific user
scancel <jobid> # cancel a specific job
scancel -u <username> # cancel all queued and running jobs for a specific userMy HPC cluster excution time is limited and terminates before the simulation is complete
This issue is important whenever the HPC cluster has mandatory time/RAM limits for the job submissions, where the array job may not complete within the assigned resources — hence, if not properly managed, will discard any valid replication information when abruptly terminated. Unfortunately, this is a very likely occurrence, and is largely a function of being unsure about how long each simulation condition/replication will take to complete when distributed across the arrays (some conditions/replications will take longer than others, and it is difficult to be perfectly knowledgeable about this information beforehand).
To avoid this time/resource waste it is strongly
recommended to add a max_time argument to the
control list (see help(runArraySimulation) for
supported specifications) which is less than the Slurm specifications.
This control flag will halt the runArraySimulation()
executions early and return only the complete simulation results up to
this point. However, this will only work if the argument is
non-trivially less than the allocated Slurm resources;
otherwise, you’ll run the risk that the job terminates before the
SimDesign functions have the chance to store the
successfully completed replications. Setting this to around 90-95% of
the respective #SBATCH --time= input should, however, be
sufficient in most cases.
# Return successful results up to the 11 hour mark
runArraySimulation(design=Design300, replications=replications,
generate=Generate, analyse=Analyse,
summarise=Summarise, iseed=iseed, arrayID=arrayID,
dirname='mysimfiles', filename='mysim',
control=list(max_time="11:00:00")) Of course, if the session does time out early then this implies that
the target replications will be missed on the first job
submission batch. Therefore, and as is covered in the next section, a
new job must be submitted to the scheduler that is mindful of the
initial simulation history (particularly, the .Random.seed
states).
Uploading array jobs related to previous array submissions
Related to early termination issue above is what to do about the missing replication information in the event that the complete set of replication information has not been collected. Obtaining the missing information clearly requires a second (or third) submission of the simulation job, though obviously only for the conditions where the collected replication results were problematic. Moreover, this has to be performed with care to avoid redundant random data generation strings, ultimately resulting in sub-optimal results.
To start, locate the simulation conditions in the aggregated result that do not meet the target replication criteria. This could be obtained via inspection of the aggregated results
Final <- SimCollect('mysimfiles/')
Final# A tibble: 3 × 8
N mean median REPLICATIONS SIM_TIME COMPLETED
<dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 10 9.9973 9.9934 9000 23.42s Thu Apr 4 11:50:11 2024
2 20 10.007 10.015 10000 24.24s Thu Apr 4 11:50:35 2024
3 30 10.003 10.007 8000 24.39s Thu Apr 4 11:51:00 2024or via the more informative (and less memory intensive)
SimCollect(..., check.only=TRUE) flag.
Missed <- SimCollect(files=dir(), check.only=TRUE)
Missed# A tibble: 4 × 3
N MISSED_REPLICATIONS TARGET_REPLICATIONS
<dbl> <int> <int>
1 10 1000 10000
2 30 2000 10000Create new conditions for missing replications, and use
rbind()
Next, build a new simulation structure containing only the missing information components.
Notice that the Design.ID terms below are associated
with the problematic conditions in the original Design
object.
print(subDesign, show.IDs = TRUE)## # A tibble: 2 × 2
## Design.ID N
## <int> <dbl>
## 1 1 10
## 2 3 30
replications_missed## [1] 1000 2000At this point, you can return to the above logic of organizing the
simulation script job, distributing the information across as many array
jobs as necessary to fill in the missing information. However, as before
you must be very careful about the random number generators per
row in subDesign and the original
submission job. The fix in this case is straightforward as well: simply
create a continuation from the previous logic, where the new elements
are treated as additional rows in the resulting object as though they
were part of the initial job submission. Note that the
subDesign component must use the original
Design object in its construction so that the internal
Design.ID attributes are properly tracked.
Finally, the new subDesign information is row-bound to
the original expanded version using rbind() with
keep.IDs = TRUE (the default), though telling the scheduler
to only evaluate these new rows in the #SBATCH --array
specification.
rc <- 50
Design_left <- expandDesign(subDesign, rc) # smaller number of reps per array
Design_left## # A tibble: 100 × 1
## N
## <dbl>
## 1 10
## 2 10
## 3 10
## 4 10
## 5 10
## 6 10
## 7 10
## 8 10
## 9 10
## 10 10
## # ℹ 90 more rows## replications_left
## 20 40
## 50 50
# new total design and replication objects
Design_total <- rbind(Design300, Design_left, keep.IDs=TRUE)
nrow(Design_total)## [1] 400
print(Design_total, show.IDs = TRUE)## # A tibble: 400 × 2
## Design.ID N
## <int> <dbl>
## 1 1 10
## 2 1 10
## 3 1 10
## 4 1 10
## 5 1 10
## 6 1 10
## 7 1 10
## 8 1 10
## 9 1 10
## 10 1 10
## # ℹ 390 more rows## replications_total
## 20 40 100
## 50 50 1
# this *must* be the same as the original submission!
iseed <- 1276149341Again, this approach simply expands the original simulation with 300 array jobs to one with 400 array jobs as though the added structure was an intended part of the initial design (which is obviously wasn’t, but is organized as such). This also ensure that the random number generation is properly accounted for as the new conditions to evaluate will be uncorrelated with the previous array evaluation jobs.
Submit the new job, evaluating only the new conditions
Finally, in your new .slurm submission file you no
longer want to evaluate the first 1-300 cases, as these
.rds files have already been evaluated, and instead want to
change the --array line from
#SBATCH --array=1-300to
#SBATCH --array=301-400Submit this job to compute all the missing replication information,
which stores these files into the same working directory but with the
new information stored as mysim-301.rds through
mysim-400.rds. In this example, there will now be a total
of 400 files that have been saved.
Once complete, run
# See if any missing still
SimCollect('mysimfiles', check.only=TRUE)
# Obtain complete simulation results
Final <- SimCollect('mysimfiles')one last time, which now reads in the complete set of 400 stored files instead of the previous 300, thereby obtaining the complete set of high-quality simulation results. Rinse and repeat if the same issue appears yet again on the second submission.