Full-Information Item Factor Analysis (Multidimensional Item Response Theory)
Source:R/mirt.R
mirt.Rdmirt fits a maximum likelihood (or maximum a posteriori) factor analysis model
to any mixture of dichotomous and polytomous data under the item response theory paradigm
using either Cai's (2010) Metropolis-Hastings Robbins-Monro (MHRM) algorithm, with
an EM algorithm approach outlined by Bock and Aitkin (1981) using rectangular or
quasi-Monte Carlo integration grids, or with the stochastic EM (i.e., the first two stages
of the MH-RM algorithm). Models containing 'explanatory' person or item level predictors
can only be included by using the mixedmirt function, though latent
regression models can be fit using the formula input in this function.
Tests that form a two-tier or bi-factor structure should be estimated with the
bfactor function, which uses a dimension reduction EM algorithm for
modeling item parcels. Multiple group analyses (useful for DIF and DTF testing) are
also available using the multipleGroup function.
Usage
mirt(
data,
model = 1,
itemtype = NULL,
guess = 0,
upper = 1,
SE = FALSE,
covdata = NULL,
formula = NULL,
itemdesign = NULL,
item.formula = NULL,
SE.type = "Oakes",
method = "EM",
optimizer = NULL,
dentype = "Gaussian",
pars = NULL,
constrain = NULL,
calcNull = FALSE,
draws = 5000,
survey.weights = NULL,
quadpts = NULL,
TOL = NULL,
gpcm_mats = list(),
grsm.block = NULL,
rsm.block = NULL,
monopoly.k = 1L,
key = NULL,
large = FALSE,
GenRandomPars = FALSE,
accelerate = "Ramsay",
verbose = TRUE,
solnp_args = list(),
nloptr_args = list(),
spline_args = list(),
control = list(),
technical = list(),
...
)Arguments
- data
a
matrixordata.framethat consists of numerically ordered data, organized in the form of integers, with missing data coded asNA(to convert from an ordered factordata.frameseedata.matrix)- model
a string to be passed (or an object returned from)
mirt.model, declaring how the IRT model is to be estimated (loadings, constraints, priors, etc). For exploratory IRT models, a single numeric value indicating the number of factors to extract is also supported. Default is 1, indicating that a unidimensional model will be fit unless otherwise specified- itemtype
type of items to be modeled, declared as either a) a single value to be recycled for each item, b) a vector for each respective item, or c) if applicable, a matrix with columns equal to the number of items and rows equal to the number of latent classes. The
NULLdefault assumes that the items follow a graded or 2PL structure, however they may be changed to the following:'Rasch'- Rasch/partial credit model by constraining slopes to 1 and freely estimating the variance parameters (alternatively, can be specified by applying equality constraints to the slope parameters in'gpcm'and'2PL'; Rasch, 1960)'1PL','2PL','3PL','3PLu', and'4PL'- 1-4 parameter logistic model, where3PLestimates the lower asymptote only while3PLuestimates the upper asymptote only (Lord and Novick, 1968; Lord, 1980). Note that specifying'1PL'will not automatically estimate the variance of the latent trait compared to the'Rasch'type'5PL'- 5 parameter logistic model to estimate asymmetric logistic response curves. Currently restricted to unidimensional models'CLL'- complementary log-log link model. Currently restricted to unidimensional models'ULL'- unipolar log-logistic model (Lucke, 2015). Note the use of this itemtype will automatically use a log-normal distribution for the latent traits'graded'- graded response model (Samejima, 1969)'grsm'- graded ratings scale model in the classical IRT parameterization (restricted to unidimensional models; Muraki, 1992)'gpcm'and'gpcmIRT'- generalized partial credit model in the slope-intercept and classical parameterization.'gpcmIRT'is restricted to unidimensional models. Note that optional scoring matrices for'gpcm'are available with thegpcm_matsinput (Muraki, 1992)'rsm'- Rasch rating scale model using the'gpcmIRT'structure (unidimensional only; Andrich, 1978)'nominal'- nominal response model (Bock, 1972)'ideal'- dichotomous ideal point model (Maydeu-Olivares, 2006)'ggum'- generalized graded unfolding model (Roberts, Donoghue, & Laughlin, 2000) and its multidimensional extension'sequential'- multidimensional sequential response model (Tutz, 1990) in slope-intercept form'Tutz'- same as the'sequential'itemtype, except the slopes are fixed to 1 and the latent variance terms are freely estimated (similar to the'Rasch'itemtype input)'PC1PL','PC2PL', and'PC3PL'- 1-3 parameter partially compensatory model. Note that constraining the slopes to be equal across items will also reduce the model to Embretson's (a.k.a. Whitely's) multicomponent model (1980), while for'PC1PL'the slopes are fixed to 1 while the latent trait variance terms are estimated'2PLNRM','3PLNRM','3PLuNRM', and'4PLNRM'- 2-4 parameter nested logistic model, where3PLNRMestimates the lower asymptote only while3PLuNRMestimates the upper asymptote only (Suh and Bolt, 2010)'spline'- spline response model with thebs(default) or thensfunction (Winsberg, Thissen, and Wainer, 1984)'monopoly'- monotonic polynomial model for unidimensional tests for dichotomous and polytomous response data (Falk and Cai, 2016)
Additionally, user defined item classes can also be defined using the
createItemfunction- guess
fixed pseudo-guessing parameters. Can be entered as a single value to assign a global guessing parameter or may be entered as a numeric vector corresponding to each item
- upper
fixed upper bound parameters for 4-PL model. Can be entered as a single value to assign a global guessing parameter or may be entered as a numeric vector corresponding to each item
- SE
logical; estimate the standard errors by computing the parameter information matrix? See
SE.typefor the type of estimates available- covdata
a data.frame of data used for latent regression models
- formula
an R formula (or list of formulas) indicating how the latent traits can be regressed using external covariates in
covdata. If a named list of formulas is supplied (where the names correspond to the latent trait names inmodel) then specific regression effects can be estimated for each factor. Supplying a single formula will estimate the regression parameters for all latent traits by default- itemdesign
a
data.framewith rows equal to the number of items and columns containing any item-design effects. If items should be included in the design structure (i.e., should be left in their canonical structure) then fewer rows can be used, however therownamesmust be defined and matched withcolnamesin thedatainput. The item design matrix is constructed with the use ofitem.formula. Providing this input will fix the associated'd'intercepts to 0, where applicable- item.formula
an R formula used to specify any intercept decomposition (e.g., the LLTM; Fischer, 1983). Note that only the right-hand side of the formula is required for compensatory models.
For non-compensatory
itemtypes (e.g.,'PC1PL') the formula must include the name of the latent trait in the left hand side of the expression to indicate which of the trait specification should have their intercepts decomposed (see MLTM; Embretson, 1984)- SE.type
type of estimation method to use for calculating the parameter information matrix for computing standard errors and
waldtests. Can be:'Richardson','forward', or'central'for the numerical Richardson, forward difference, and central difference evaluation of observed Hessian matrix'crossprod'and'Louis'for standard error computations based on the variance of the Fisher scores as well as Louis' (1982) exact computation of the observed information matrix. Note that Louis' estimates can take a long time to obtain for large sample sizes and long tests'sandwich'for the sandwich covariance estimate based on the'crossprod'and'Oakes'estimates (see Chalmers, 2018, for details)'sandwich.Louis'for the sandwich covariance estimate based on the'crossprod'and'Louis'estimates'Oakes'for Oakes' (1999) method using a central difference approximation (see Chalmers, 2018, for details)'SEM'for the supplemented EM (disables theaccelerateoption automatically; EM only)'Fisher'for the expected information,'complete'for information based on the complete-data Hessian used in EM algorithm'MHRM'and'FMHRM'for stochastic approximations of observed information matrix based on the Robbins-Monro filter or a fixed number of MHRM draws without the RM filter. These are the only options supported whenmethod = 'MHRM''numerical'to obtain the numerical estimate from a call tooptimwhenmethod = 'BL'
Note that both the
'SEM'method becomes very sensitive if the ML solution has has not been reached with sufficient precision, and may be further sensitive if the history of the EM cycles is not stable/sufficient for convergence of the respective estimates. Increasing the number of iterations (increasingNCYCLESand decreasingTOL, see below) will help to improve the accuracy, and can be run in parallel if amirtClusterobject has been defined (this will be used for Oakes' method as well). Additionally, inspecting the symmetry of the ACOV matrix for convergence issues by passingtechnical = list(symmetric = FALSE)can be helpful to determine if a sufficient solution has been reached- method
a character object specifying the estimation algorithm to be used. The default is
'EM', for the standard EM algorithm with fixed quadrature,'QMCEM'for quasi-Monte Carlo EM estimation, or'MCEM'for Monte Carlo EM estimation. The option'MHRM'may also be passed to use the MH-RM algorithm,'SEM'for the Stochastic EM algorithm (first two stages of the MH-RM stage using an optimizer other than a single Newton-Raphson iteration), and'BL'for the Bock and Lieberman approach (generally not recommended for longer tests).The
'EM'is generally effective with 1-3 factors, but methods such as the'QMCEM','MCEM','SEM', or'MHRM'should be used when the dimensions are 3 or more. Note that when the optimizer is stochastic the associatedSE.typeis automatically changed toSE.type = 'MHRM'by default to avoid the use of quadrature- optimizer
a character indicating which numerical optimizer to use. By default, the EM algorithm will use the
'BFGS'when there are no upper and lower bounds box-constraints and'nlminb'when there are.Other options include the Newton-Raphson (
'NR'), which can be more efficient than the'BFGS'but not as stable for more complex IRT models (such as the nominal or nested logit models) and the related'NR1'which is also the Newton-Raphson but consists of only 1 update that has been coupled with RM Hessian (only applicable when the MH-RM algorithm is used). The MH-RM algorithm uses the'NR1'by default, though currently the'BFGS','L-BFGS-B', and'NR'are also supported with this method (with fewer iterations by default) to emulate stochastic EM updates. As well, the'Nelder-Mead'and'SANN'estimators are available, but their routine use generally is not required or recommended.Additionally, estimation subroutines from the
Rsolnpandnloptrpackages are available by passing the arguments'solnp'and'nloptr', respectively. This should be used in conjunction with thesolnp_argsandnloptr_argsspecified below. If equality constraints were specified in the model definition only the parameter with the lowestparnumin thepars = 'values'data.frame is used in the estimation vector passed to the objective function, and group hyper-parameters are omitted. Equality an inequality functions should be of the formfunction(p, optim_args), whereoptim_argsis a list of internally parameters that largely can be ignored when defining constraints (though use ofbrowser()here may be helpful)- dentype
type of density form to use for the latent trait parameters. Current options include
'Gaussian'(default) assumes a multivariate Gaussian distribution with an associated mean vector and variance-covariance matrix'empiricalhist'or'EH'estimates latent distribution using an empirical histogram described by Bock and Aitkin (1981). Only applicable for unidimensional models estimated with the EM algorithm. For this option, the number of cycles, TOL, and quadpts are adjusted accommodate for less precision during estimation (namely:TOL = 3e-5,NCYCLES = 2000,quadpts = 121)'empiricalhist_Woods'or'EHW'estimates latent distribution using an empirical histogram described by Bock and Aitkin (1981), with the same specifications as indentype = 'empiricalhist', but with the extrapolation-interpolation method described by Woods (2007). NOTE: to improve stability in the presence of extreme response styles (i.e., all highest or lowest in each item) thetechnicaloptionzeroExtreme = TRUEmay be required to down-weight the contribution of these problematic patterns'Davidian-#'estimates semi-parametric Davidian curves described by Woods and Lin (2009), where the#placeholder represents the number of Davidian parameters to estimate (e.g.,'Davidian-6'will estimate 6 smoothing parameters). By default, the number ofquadptsis increased to 121, and this method is only applicable for unidimensional models estimated with the EM algorithm
Note that when
itemtype = 'ULL'then a log-normal(0,1) density is used to support the unipolar scaling- pars
a data.frame with the structure of how the starting values, parameter numbers, estimation logical values, etc, are defined. The user may observe how the model defines the values by using
pars = 'values', and this object can in turn be modified and input back into the estimation withpars = mymodifiedpars- constrain
a list of user declared equality constraints. To see how to define the parameters correctly use
pars = 'values'initially to see how the parameters are labeled. To constrain parameters to be equal create a list with separate concatenated vectors signifying which parameters to constrain. For example, to set parameters 1 and 5 equal, and also set parameters 2, 6, and 10 equal useconstrain = list(c(1,5), c(2,6,10)). Constraints can also be specified using themirt.modelsyntax (recommended)- calcNull
logical; calculate the Null model for additional fit statistics (e.g., TLI)? Only applicable if the data contains no NA's and the data is not overly sparse
- draws
the number of Monte Carlo draws to estimate the log-likelihood for the MH-RM algorithm. Default is 5000
- survey.weights
a optional numeric vector of survey weights to apply for each case in the data (EM estimation only). If not specified, all cases are weighted equally (the standard IRT approach). The sum of the
survey.weightsmust equal the total sample size for proper weighting to be applied- quadpts
number of quadrature points per dimension (must be larger than 2). By default the number of quadrature uses the following scheme:
switch(as.character(nfact), '1'=61, '2'=31, '3'=15, '4'=9, '5'=7, 3). However, if the method input is set to'QMCEM'and this argument is left blank then the default number of quasi-Monte Carlo integration nodes will be set to 5000 in total- TOL
convergence threshold for EM or MH-RM; defaults are .0001 and .001. If
SE.type = 'SEM'and this value is not specified, the default is set to1e-5. To evaluate the model using only the starting values passTOL = NaN, and to evaluate the starting values without the log-likelihood passTOL = NA- gpcm_mats
a list of matrices specifying how the scoring coefficients in the (generalized) partial credit model should be constructed. If omitted, the standard gpcm format will be used (i.e.,
seq(0, k, by = 1)for each trait). This input should be used if traits should be scored different for each category (e.g.,matrix(c(0:3, 1,0,0,0), 4, 2)for a two-dimensional model where the first trait is scored like a gpcm, but the second trait is only positively indicated when the first category is selected). Can be used whenitemtypes are'gpcm'or'Rasch', but only when the respective element ingpcm_matsis notNULL- grsm.block
an optional numeric vector indicating where the blocking should occur when using the grsm, NA represents items that do not belong to the grsm block (other items that may be estimated in the test data). For example, to specify two blocks of 3 with a 2PL item for the last item:
grsm.block = c(rep(1,3), rep(2,3), NA). If NULL the all items are assumed to be within the same group and therefore have the same number of item categories- rsm.block
same as
grsm.block, but for'rsm'blocks- monopoly.k
a vector of values (or a single value to repeated for each item) which indicate the degree of the monotone polynomial fitted, where the monotone polynomial corresponds to
monopoly.k * 2 + 1(e.g.,monopoly.k = 2fits a 5th degree polynomial). Default ismonopoly.k = 1, which fits a 3rd degree polynomial- key
a numeric vector of the response scoring key. Required when using nested logit item types, and must be the same length as the number of items used. Items that are not nested logit will ignore this vector, so use
NAin item locations that are not applicable- large
a
logicalindicating whether unique response patterns should be obtained prior to performing the estimation so as to avoid repeating computations on identical patterns. The defaultTRUEprovides the correct degrees of freedom for the model since all unique patterns are tallied (typically only affects goodness of fit statistics such as G2, but also will influence nested model comparison methods such asanova(mod1, mod2)), whileFALSEwill use the number of rows indataas a placeholder for the total degrees of freedom. As such, model objects should only be compared if all flags were set toTRUEor all were set toFALSEAlternatively, if the collapse table of frequencies is desired for the purpose of saving computations (i.e., only computing the collapsed frequencies for the data onte-time) then a character vector can be passed with the arguement
large = 'return'to return a list of all the desired table information used bymirt. This list object can then be reused by passing it back into thelargeargument to avoid re-tallying the data again (again, useful when the dataset are very large and computing the tabulated data is computationally burdensome). This strategy is shown below:- Compute organized data
e.g.,
internaldat <- mirt(Science, 1, large = 'return')- Pass the organized data to all estimation functions
e.g.,
mod <- mirt(Science, 1, large = internaldat)
- GenRandomPars
logical; generate random starting values prior to optimization instead of using the fixed internal starting values?
- accelerate
a character vector indicating the type of acceleration to use. Default is
'Ramsay', but may also be'squarem'for the SQUAREM procedure (specifically, the gSqS3 approach) described in Varadhan and Roldand (2008). To disable the acceleration, pass'none'- verbose
logical; print observed- (EM) or complete-data (MHRM) log-likelihood after each iteration cycle? Default is TRUE
- solnp_args
a list of arguments to be passed to the
solnp::solnp()function for equality constraints, inequality constraints, etc- nloptr_args
a list of arguments to be passed to the
nloptr::nloptr()function for equality constraints, inequality constraints, etc- spline_args
a named list of lists containing information to be passed to the
bs(default) andnsfor each spline itemtype. Each element must refer to the name of the itemtype with the spline, while the internal list names refer to the arguments which are passed. For example, if item 2 were called 'read2', and item 5 were called 'read5', both of which were of itemtype 'spline' but item 5 should use thensform, then a modified list for each input might be of the form:spline_args = list(read2 = list(degree = 4), read5 = list(fun = 'ns', knots = c(-2, 2)))This code input changes the
bs()splines function to have adegree = 4input, while the second element changes to thens()function with knots set ac(-2, 2)- control
a list passed to the respective optimizers (i.e.,
optim(),nlminb(), etc). Additional arguments have been included for the'NR'optimizer:'tol'for the convergence tolerance in the M-step (default isTOL/1000), while the default number of iterations for the Newton-Raphson optimizer is 50 (modified with the'maxit'control input)- technical
a list containing lower level technical parameters for estimation. May be:
- NCYCLES
maximum number of EM or MH-RM cycles; defaults are 500 and 2000
- MAXQUAD
maximum number of quadratures, which you can increase if you have more than 4GB or RAM on your PC; default 20000
- theta_lim
range of integration grid for each dimension; default is
c(-6, 6). Note that whenitemtype = 'ULL'a log-normal distribution is used and the range is change toc(.01, and 6^2), where the second term is the square of thetheta_liminput instead- set.seed
seed number used during estimation. Default is 12345
- SEtol
standard error tolerance criteria for the S-EM and MHRM computation of the information matrix. Default is 1e-3
- symmetric
logical; force S-EM/Oakes information matrix estimates to be symmetric? Default is TRUE so that computation of standard errors are more stable. Setting this to FALSE can help to detect solutions that have not reached the ML estimate
- SEM_window
ratio of values used to define the S-EM window based on the observed likelihood differences across EM iterations. The default is
c(0, 1 - SEtol), which provides nearly the very full S-EM window (i.e., nearly all EM cycles used). To use the a smaller SEM window change the window to to something likec(.9, .999)to start at a point farther into the EM history- warn
logical; include warning messages during estimation? Default is TRUE
- message
logical; include general messages during estimation? Default is TRUE
- customK
a numeric vector used to explicitly declare the number of response categories for each item. This should only be used when constructing mirt model for reasons other than parameter estimation (such as to obtain factor scores), and requires that the input data all have 0 as the lowest category. The format is the same as the
extract.mirt(mod, 'K')slot in all converged models- customPriorFun
a custom function used to determine the normalized density for integration in the EM algorithm. Must be of the form
function(Theta, Etable){...}, and return a numeric vector with the same length as number of rows inTheta. TheEtableinput contains the aggregated table generated from the current E-step computations. For proper integration, the returned vector should sum to 1 (i.e., normalized). Note that if using theEtableit will be NULL on the first call, therefore the prior will have to deal with this issue accordingly- zeroExtreme
logical; assign extreme response patterns a
survey.weightof 0 (formally equivalent to removing these data vectors during estimation)? Whendentype = 'EHW', where Woods' extrapolation is utilized, this option may be required if the extrapolation causes expected densities to tend towards positive or negative infinity. The default isFALSE- customTheta
a custom
Thetagrid, in matrix form, used for integration. If not defined, the grid is determined internally based on the number ofquadpts- nconstrain
same specification as the
constrainlist argument, however imposes a negative equality constraint instead (e.g., \(a12 = -a21\), which is specified asnconstrain = list(c(12, 21))). Note that each specification in the list must be of length 2, where the second element is taken to be -1 times the first element- delta
the deviation term used in numerical estimates when computing the ACOV matrix with the 'forward' or 'central' numerical approaches, as well as Oakes' method with the Richardson extrapolation. Default is 1e-5
- parallel
logical; use the parallel cluster defined by
mirtCluster? Default is TRUE- storeEMhistory
logical; store the iteration history when using the EM algorithm? Default is FALSE. When TRUE, use
extract.mirtto extract- internal_constraints
logical; include the internal constraints when using certain IRT models (e.g., 'grsm' itemtype). Disable this if you want to use special optimizers such as the solnp. Default is
TRUE- gain
a vector of two values specifying the numerator and exponent values for the RM gain function \((val1 / cycle)^val2\). Default is
c(0.10, 0.75)- BURNIN
number of burn in cycles (stage 1) in MH-RM; default is 150
- SEMCYCLES
number of SEM cycles (stage 2) in MH-RM; default is 100
- MHDRAWS
number of Metropolis-Hasting draws to use in the MH-RM at each iteration; default is 5
- MHcand
a vector of values used to tune the MH sampler. Larger values will cause the acceptance ratio to decrease. One value is required for each group in unconditional item factor analysis (
mixedmirt()requires additional values for random effect). If null, these values are determined internally, attempting to tune the acceptance of the draws to be between .1 and .4- MHRM_SE_draws
number of fixed draws to use when
SE=TRUEandSE.type = 'FMHRM'and the maximum number of draws whenSE.type = 'MHRM'. Default is 2000- MCEM_draws
a function used to determine the number of quadrature points to draw for the
'MCEM'method. Must include one argument which indicates the iteration number of the EM cycle. Default isfunction(cycles) 500 + (cycles - 1)*2, which starts the number of draws at 500 and increases by 2 after each full EM iteration- info_if_converged
logical; compute the information matrix when using the MH-RM algorithm only if the model converged within a suitable number of iterations? Default is
TRUE- logLik_if_converged
logical; compute the observed log-likelihood when using the MH-RM algorithm only if the model converged within a suitable number of iterations? Default is
TRUE- keep_vcov_PD
logical; attempt to keep the variance-covariance matrix of the latent traits positive definite during estimation in the EM algorithm? This generally improves the convergence properties when the traits are highly correlated. Default is
TRUE
- ...
additional arguments to be passed
Value
function returns an object of class SingleGroupClass
(SingleGroupClass-class)
Confirmatory and Exploratory IRT
Specification of the confirmatory item factor analysis model follows many of
the rules in the structural equation modeling framework for confirmatory factor analysis. The
variances of the latent factors are automatically fixed to 1 to help
facilitate model identification. All parameters may be fixed to constant
values or set equal to other parameters using the appropriate declarations.
Confirmatory models may also contain 'explanatory' person or item level predictors, though
including predictors is currently limited to the mixedmirt function.
When specifying a single number greater than 1 as the model input to mirt
an exploratory IRT model will be estimated. Rotation and target matrix options are available
if they are passed to generic functions such as summary-method and
fscores. Factor means and variances are fixed to ensure proper identification.
If the model is an exploratory item factor analysis estimation will begin
by computing a matrix of quasi-polychoric correlations. A
factor analysis with nfact is then extracted and item parameters are
estimated by \(a_{ij} = f_{ij}/u_j\), where \(f_{ij}\) is the factor
loading for the jth item on the ith factor, and \(u_j\) is
the square root of the factor uniqueness, \(\sqrt{1 - h_j^2}\). The
initial intercept parameters are determined by calculating the inverse
normal of the item facility (i.e., item easiness), \(q_j\), to obtain
\(d_j = q_j / u_j\). A similar implementation is also used for obtaining
initial values for polytomous items.
A note on upper and lower bound parameters
Internally the \(g\) and \(u\) parameters are transformed using a logit
transformation (\(log(x/(1-x))\)), and can be reversed by using \(1 / (1 + exp(-x))\)
following convergence. This also applies when computing confidence intervals for these
parameters, and is done so automatically if coef(mod, rawug = FALSE).
As such, when applying prior distributions to these parameters it is recommended to use a prior
that ranges from negative infinity to positive infinity, such as the normally distributed
prior via the 'norm' input (see mirt.model).
Convergence for quadrature methods
Unrestricted full-information factor analysis is known to have problems with convergence, and some items may need to be constrained or removed entirely to allow for an acceptable solution. As a general rule dichotomous items with means greater than .95, or items that are only .05 greater than the guessing parameter, should be considered for removal from the analysis or treated with prior parameter distributions. The same type of reasoning is applicable when including upper bound parameters as well. For polytomous items, if categories are rarely endorsed then this will cause similar issues. Also, increasing the number of quadrature points per dimension, or using the quasi-Monte Carlo integration method, may help to stabilize the estimation process in higher dimensions. Finally, solutions that are not well defined also will have difficulty converging, and can indicate that the model has been misspecified (e.g., extracting too many dimensions).
Convergence for MH-RM method
For the MH-RM algorithm, when the number of iterations grows very high (e.g., greater than 1500)
or when Max Change = .2500 values are repeatedly printed
to the console too often (indicating that the parameters were being constrained since they are
naturally moving in steps greater than 0.25) then the model may either be ill defined or have a
very flat likelihood surface, and genuine maximum-likelihood parameter estimates may be difficult
to find. Standard errors are computed following the model convergence by passing
SE = TRUE, to perform an addition MH-RM stage but treating the maximum-likelihood
estimates as fixed points.
Additional helper functions
Additional functions are available in the package which can be useful pre- and post-estimation. These are:
mirt.modelDefine the IRT model specification use special syntax. Useful for defining between and within group parameter constraints, prior parameter distributions, and specifying the slope coefficients for each factor
coef-methodExtract raw coefficients from the model, along with their standard errors and confidence intervals
summary-methodExtract standardized loadings from model. Accepts a
rotateargument for exploratory item response modelanova-methodCompare nested models using likelihood ratio statistics as well as information criteria such as the AIC and BIC
residuals-methodCompute pairwise residuals between each item using methods such as the LD statistic (Chen & Thissen, 1997), as well as response pattern residuals
plot-methodPlot various types of test level plots including the test score and information functions and more
itemplotPlot various types of item level plots, including the score, standard error, and information functions, and more
createItemCreate a customized
itemtypethat does not currently exist in the packageimputeMissingImpute missing data given some computed Theta matrix
fscoresFind predicted scores for the latent traits using estimation methods such as EAP, MAP, ML, WLE, and EAPsum
waldCompute Wald statistics follow the convergence of a model with a suitable information matrix
M2Limited information goodness of fit test statistic based to determine how well the model fits the data
itemfitandpersonfitGoodness of fit statistics at the item and person levels, such as the S-X2, infit, outfit, and more
boot.mirtCompute estimated parameter confidence intervals via the bootstrap methods
mirtClusterDefine a cluster for the package functions to use for capitalizing on multi-core architecture to utilize available CPUs when possible. Will help to decrease estimation times for tasks that can be run in parallel
IRT Models
The parameter labels use the follow convention, here using two factors and \(K\) as the total number of categories (using \(k\) for specific category instances).
- Rasch
Only one intercept estimated, and the latent variance of \(\theta\) is freely estimated. If the data have more than two categories then a partial credit model is used instead (see 'gpcm' below). $$P(x = 1|\theta, d) = \frac{1}{1 + exp(-(\theta + d))}$$
- 1-4PL
Depending on the model \(u\) may be equal to 1 (e.g., 3PL), \(g\) may be equal to 0 (e.g., 2PL), or the
as may be fixed to 1 (e.g., 1PL). $$P(x = 1|\theta, \psi) = g + \frac{(u - g)}{ 1 + exp(-(a_1 * \theta_1 + a_2 * \theta_2 + d))}$$- 5PL
Currently restricted to unidimensional models $$P(x = 1|\theta, \psi) = g + \frac{(u - g)}{ 1 + exp(-(a_1 * \theta_1 + d))^S}$$ where \(S\) allows for asymmetry in the response function and is transformation constrained to be greater than 0 (i.e.,
log(S)is estimated rather thanS)- CLL
Complementary log-log model (see Shim, Bonifay, and Wiedermann, 2022) $$P(x = 1|\theta, b) = 1 - exp(-exp(\theta - b))$$ Currently restricted to unidimensional dichotomous data.
- graded
The graded model consists of sequential 2PL models, $$P(x = k | \theta, \psi) = P(x \ge k | \theta, \phi) - P(x \ge k + 1 | \theta, \phi)$$ Note that \(P(x \ge 1 | \theta, \phi) = 1\) while \(P(x \ge K + 1 | \theta, \phi) = 0\)
- ULL
The unipolar log-logistic model (ULL; Lucke, 2015) is defined the same as the graded response model, however $$P(x \le k | \theta, \psi) = \frac{\lambda_k\theta^\eta}{1 + \lambda_k\theta^\eta}$$. Internally the \(\lambda\) parameters are exponentiated to keep them positive, and should therefore the reported estimates should be interpreted in log units
- grsm
A more constrained version of the graded model where graded spacing is equal across item blocks and only adjusted by a single 'difficulty' parameter (c) while the latent variance of \(\theta\) is freely estimated (see Muraki, 1990 for this exact form). This is restricted to unidimensional models only.
- gpcm/nominal
For the gpcm the \(d\) values are treated as fixed and ordered values from \(0:(K-1)\) (in the nominal model \(d_0\) is also set to 0). Additionally, for identification in the nominal model \(ak_0 = 0\), \(ak_{(K-1)} = (K - 1)\). $$P(x = k | \theta, \psi) = \frac{exp(ak_{k-1} * (a_1 * \theta_1 + a_2 * \theta_2) + d_{k-1})} {\sum_{k=1}^K exp(ak_{k-1} * (a_1 * \theta_1 + a_2 * \theta_2) + d_{k-1})}$$
For the partial credit model (when
itemtype = 'Rasch'; unidimensional only) the above model is further constrained so that \(ak = (0,1,\ldots, K-1)\), \(a_1 = 1\), and the latent variance of \(\theta_1\) is freely estimated. Alternatively, the partial credit model can be obtained by containing all the slope parameters in the gpcms to be equal. More specific scoring function may be included by passing a suitable list or matrices to thegpcm_matsinput argument.In the nominal model this parametrization helps to identify the empirical ordering of the categories by inspecting the \(ak\) values. Larger values indicate that the item category is more positively related to the latent trait(s) being measured. For instance, if an item was truly ordinal (such as a Likert scale), and had 4 response categories, we would expect to see \(ak_0 < ak_1 < ak_2 < ak_3\) following estimation. If on the other hand \(ak_0 > ak_1\) then it would appear that the second category is less related to to the trait than the first, and therefore the second category should be understood as the 'lowest score'.
NOTE: The nominal model can become numerical unstable if poor choices for the high and low values are chosen, resulting in
akvalues greater thanabs(10)or more. It is recommended to choose high and low anchors that cause the estimated parameters to fall between 0 and \(K - 1\) either by theoretical means or by re-estimating the model with better values following convergence.- gpcmIRT and rsm
The gpcmIRT model is the classical generalized partial credit model for unidimensional response data. It will obtain the same fit as the
gpcmpresented above, however the parameterization allows for the Rasch/generalized rating scale model as a special case.E.g., for a K = 4 category response model,
$$P(x = 0 | \theta, \psi) = exp(0) / G$$ $$P(x = 1 | \theta, \psi) = exp(a(\theta - b1) + c) / G$$ $$P(x = 2 | \theta, \psi) = exp(a(2\theta - b1 - b2) + 2c) / G$$ $$P(x = 3 | \theta, \psi) = exp(a(3\theta - b1 - b2 - b3) + 3c) / G$$ where $$G = exp(0) + exp(a(\theta - b1) + c) + exp(a(2\theta - b1 - b2) + 2c) + exp(a(3\theta - b1 - b2 - b3) + 3c)$$ Here \(a\) is the slope parameter, the \(b\) parameters are the threshold values for each adjacent category, and \(c\) is the so-called difficulty parameter when a rating scale model is fitted (otherwise, \(c = 0\) and it drops out of the computations).
The gpcmIRT can be constrained to the partial credit IRT model by either constraining all the slopes to be equal, or setting the slopes to 1 and freeing the latent variance parameter.
Finally, the rsm is a more constrained version of the (generalized) partial credit model where the spacing is equal across item blocks and only adjusted by a single 'difficulty' parameter (c). Note that this is analogous to the relationship between the graded model and the grsm (with an additional constraint regarding the fixed discrimination parameters).
- sequential/Tutz
The multidimensional sequential response model has the form $$P(x = k | \theta, \psi) = \prod (1 - F(a_1 \theta_1 + a_2 \theta_2 + d_{sk})) F(a_1 \theta_1 + a_2 \theta_2 + d_{jk})$$ where \(F(\cdot)\) is the cumulative logistic function. The Tutz variant of this model (Tutz, 1990) (via
itemtype = 'Tutz') assumes that the slope terms are all equal to 1 and the latent variance terms are estimated (i.e., is a Rasch variant).- ideal
The ideal point model has the form, with the upper bound constraint on \(d\) set to 0: $$P(x = 1 | \theta, \psi) = exp(-0.5 * (a_1 * \theta_1 + a_2 * \theta_2 + d)^2)$$
- partcomp
Partially compensatory models consist of the product of 2PL probability curves. $$P(x = 1 | \theta, \psi) = g + (1 - g) (\frac{1}{1 + exp(-(a_1 * \theta_1 + d_1))}^c_1 * \frac{1}{1 + exp(-(a_2 * \theta_2 + d_2))}^c_2)$$
where $c_1$ and $c_2$ are binary indicator variables reflecting whether the item should include the select compensatory component (1) or not (0). Note that constraining the slopes to be equal across items will reduce the model to Embretson's (Whitely's) multicomponent model (1980).
- 2-4PLNRM
Nested logistic curves for modeling distractor items. Requires a scoring key. The model is broken into two components for the probability of endorsement. For successful endorsement the probability trace is the 1-4PL model, while for unsuccessful endorsement: $$P(x = 0 | \theta, \psi) = (1 - P_{1-4PL}(x = 1 | \theta, \psi)) * P_{nominal}(x = k | \theta, \psi)$$ which is the product of the complement of the dichotomous trace line with the nominal response model. In the nominal model, the slope parameters defined above are constrained to be 1's, while the last value of the \(ak\) is freely estimated.
- ggum
The (multidimensional) generalized graded unfolding model is a class of ideal point models useful for ordinal response data. The form is $$P(z=k|\theta,\psi)=\frac{exp\left[\left(z\sqrt{\sum_{d=1}^{D} a_{id}^{2}(\theta_{jd}-b_{id})^{2}}\right)+\sum_{k=0}^{z}\psi_{ik}\right]+ exp\left[\left((M-z)\sqrt{\sum_{d=1}^{D}a_{id}^{2}(\theta_{jd}-b_{id})^{2}}\right)+ \sum_{k=0}^{z}\psi_{ik}\right]}{\sum_{w=0}^{C}\left(exp\left[\left(w \sqrt{\sum_{d=1}^{D}a_{id}^{2}(\theta_{jd}-b_{id})^{2}}\right)+ \sum_{k=0}^{z}\psi_{ik}\right]+exp\left[\left((M-w) \sqrt{\sum_{d=1}^{D}a_{id}^{2}(\theta_{jd}-b_{id})^{2}}\right)+ \sum_{k=0}^{z}\psi_{ik}\right]\right)}$$ where \(\theta_{jd}\) is the location of the \(j\)th individual on the \(d\)th dimension, \(b_{id}\) is the difficulty location of the \(i\)th item on the \(d\)th dimension, \(a_{id}\) is the discrimination of the \(j\)th individual on the \(d\)th dimension (where the discrimination values are constrained to be positive), \(\psi_{ik}\) is the \(k\)th subjective response category threshold for the \(i\)th item, assumed to be symmetric about the item and constant across dimensions, where \(\psi_{ik} = \sum_{d=1}^D a_{id} t_{ik}\) \(z = 1,2,\ldots, C\) (where \(C\) is the number of categories minus 1), and \(M = 2C + 1\).
- spline
Spline response models attempt to model the response curves uses non-linear and potentially non-monotonic patterns. The form is $$P(x = 1|\theta, \eta) = \frac{1}{1 + exp(-(\eta_1 * X_1 + \eta_2 * X_2 + \cdots + \eta_n * X_n))}$$ where the \(X_n\) are from the spline design matrix \(X\) organized from the grid of \(\theta\) values. B-splines with a natural or polynomial basis are supported, and the
interceptinput is set toTRUEby default.- monopoly
Monotone polynomial model for polytomous response data of the form $$P(x = k | \theta, \psi) = \frac{exp(\sum_1^k (m^*(\psi) + \xi_{c-1})} {\sum_1^C exp(\sum_1^K (m^*(\psi) + \xi_{c-1}))}$$ where \(m^*(\psi)\) is the monotone polynomial function without the intercept.
HTML help files, exercises, and examples
To access examples, vignettes, and exercise files that have been generated with knitr please visit https://github.com/philchalmers/mirt/wiki.
References
Andrich, D. (1978). A rating scale formulation for ordered response categories. Psychometrika, 43, 561-573.
Bock, R. D., & Aitkin, M. (1981). Marginal maximum likelihood estimation of item parameters: Application of an EM algorithm. Psychometrika, 46(4), 443-459.
Bock, R. D., Gibbons, R., & Muraki, E. (1988). Full-Information Item Factor Analysis. Applied Psychological Measurement, 12(3), 261-280.
Bock, R. D. & Lieberman, M. (1970). Fitting a response model for n dichotomously scored items. Psychometrika, 35, 179-197.
Cai, L. (2010a). High-Dimensional exploratory item factor analysis by a Metropolis-Hastings Robbins-Monro algorithm. Psychometrika, 75, 33-57.
Cai, L. (2010b). Metropolis-Hastings Robbins-Monro algorithm for confirmatory item factor analysis. Journal of Educational and Behavioral Statistics, 35, 307-335.
Chalmers, R., P. (2012). mirt: A Multidimensional Item Response Theory Package for the R Environment. Journal of Statistical Software, 48(6), 1-29. doi:10.18637/jss.v048.i06
Chalmers, R. P. (2015). Extended Mixed-Effects Item Response Models with the MH-RM Algorithm. Journal of Educational Measurement, 52, 200-222. doi:10.1111/jedm.12072
Chalmers, R. P. (2018). Numerical Approximation of the Observed Information Matrix with Oakes' Identity. British Journal of Mathematical and Statistical Psychology DOI: 10.1111/bmsp.12127
Chalmers, R., P. & Flora, D. (2014). Maximum-likelihood Estimation of Noncompensatory IRT Models with the MH-RM Algorithm. Applied Psychological Measurement, 38, 339-358. doi:10.1177/0146621614520958
Chen, W. H. & Thissen, D. (1997). Local dependence indices for item pairs using item response theory. Journal of Educational and Behavioral Statistics, 22, 265-289.
Embretson, S. E. (1984). A general latent trait model for response processes. Psychometrika, 49, 175-186.
Falk, C. F. & Cai, L. (2016). Maximum Marginal Likelihood Estimation of a Monotonic Polynomial Generalized Partial Credit Model with Applications to Multiple Group Analysis. Psychometrika, 81, 434-460.
Fischer, G. H. (1983). Logistic latent trait models with linear constraints. Psychometrika, 48, 3-26.
Lord, F. M. & Novick, M. R. (1968). Statistical theory of mental test scores. Addison-Wesley.
Lucke, J. F. (2015). Unipolar item response models. In S. P. Reise & D. A. Revicki (Eds.), Handbook of item response theory modeling: Applications to typical performance assessment (pp. 272-284). New York, NY: Routledge/Taylor & Francis Group.
Ramsay, J. O. (1975). Solving implicit equations in psychometric data analysis. Psychometrika, 40, 337-360.
Rasch, G. (1960). Probabilistic models for some intelligence and attainment tests. Danish Institute for Educational Research.
Roberts, J. S., Donoghue, J. R., & Laughlin, J. E. (2000). A General Item Response Theory Model for Unfolding Unidimensional Polytomous Responses. Applied Psychological Measurement, 24, 3-32.
Shim, H., Bonifay, W., & Wiedermann, W. (2022). Parsimonious asymmetric item response theory modeling with the complementary log-log link. Behavior Research Methods, 55, 200-219.
Maydeu-Olivares, A., Hernandez, A. & McDonald, R. P. (2006). A Multidimensional Ideal Point Item Response Theory Model for Binary Data. Multivariate Behavioral Research, 41, 445-471.
Muraki, E. (1990). Fitting a polytomous item response model to Likert-type data. Applied Psychological Measurement, 14, 59-71.
Muraki, E. (1992). A generalized partial credit model: Application of an EM algorithm. Applied Psychological Measurement, 16, 159-176.
Muraki, E. & Carlson, E. B. (1995). Full-information factor analysis for polytomous item responses. Applied Psychological Measurement, 19, 73-90.
Samejima, F. (1969). Estimation of latent ability using a response pattern of graded scores. Psychometrika Monographs, 34.
Suh, Y. & Bolt, D. (2010). Nested logit models for multiple-choice item response data. Psychometrika, 75, 454-473.
Sympson, J. B. (1977). A model for testing with multidimensional items. Proceedings of the 1977 Computerized Adaptive Testing Conference.
Thissen, D. (1982). Marginal maximum likelihood estimation for the one-parameter logistic model. Psychometrika, 47, 175-186.
Tutz, G. (1990). Sequential item response models with ordered response. British Journal of Mathematical and Statistical Psychology, 43, 39-55.
Varadhan, R. & Roland, C. (2008). Simple and Globally Convergent Methods for Accelerating the Convergence of Any EM Algorithm. Scandinavian Journal of Statistics, 35, 335-353.
Whitely, S. E. (1980). Multicomponent latent trait models for ability tests. Psychometrika, 45(4), 470-494.
Wood, R., Wilson, D. T., Gibbons, R. D., Schilling, S. G., Muraki, E., & Bock, R. D. (2003). TESTFACT 4 for Windows: Test Scoring, Item Statistics, and Full-information Item Factor Analysis [Computer software]. Lincolnwood, IL: Scientific Software International.
Woods, C. M., and Lin, N. (2009). Item Response Theory With Estimation of the Latent Density Using Davidian Curves. Applied Psychological Measurement,33(2), 102-117.
Author
Phil Chalmers rphilip.chalmers@gmail.com
Examples
# load LSAT section 7 data and compute 1 and 2 factor models
data <- expand.table(LSAT7)
itemstats(data)
#> $overall
#> N mean_total.score sd_total.score ave.r sd.r alpha SEM.alpha
#> 1000 3.707 1.199 0.143 0.052 0.453 0.886
#>
#> $itemstats
#> N mean sd total.r total.r_if_rm alpha_if_rm
#> Item.1 1000 0.828 0.378 0.530 0.246 0.396
#> Item.2 1000 0.658 0.475 0.600 0.247 0.394
#> Item.3 1000 0.772 0.420 0.611 0.313 0.345
#> Item.4 1000 0.606 0.489 0.592 0.223 0.415
#> Item.5 1000 0.843 0.364 0.461 0.175 0.438
#>
#> $proportions
#> 0 1
#> Item.1 0.172 0.828
#> Item.2 0.342 0.658
#> Item.3 0.228 0.772
#> Item.4 0.394 0.606
#> Item.5 0.157 0.843
#>
(mod1 <- mirt(data, 1))
#>
#> Call:
#> mirt(data = data, model = 1)
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 28 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -2658.805
#> Estimated parameters: 10
#> AIC = 5337.61
#> BIC = 5386.688; SABIC = 5354.927
#> G2 (21) = 31.7, p = 0.0628
#> RMSEA = 0.023, CFI = NaN, TLI = NaN
coef(mod1)
#> $Item.1
#> a1 d g u
#> par 0.988 1.856 0 1
#>
#> $Item.2
#> a1 d g u
#> par 1.081 0.808 0 1
#>
#> $Item.3
#> a1 d g u
#> par 1.706 1.804 0 1
#>
#> $Item.4
#> a1 d g u
#> par 0.765 0.486 0 1
#>
#> $Item.5
#> a1 d g u
#> par 0.736 1.855 0 1
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
summary(mod1)
#> F1 h2
#> Item.1 0.502 0.252
#> Item.2 0.536 0.287
#> Item.3 0.708 0.501
#> Item.4 0.410 0.168
#> Item.5 0.397 0.157
#>
#> SS loadings: 1.366
#> Proportion Var: 0.273
#>
#> Factor correlations:
#>
#> F1
#> F1 1
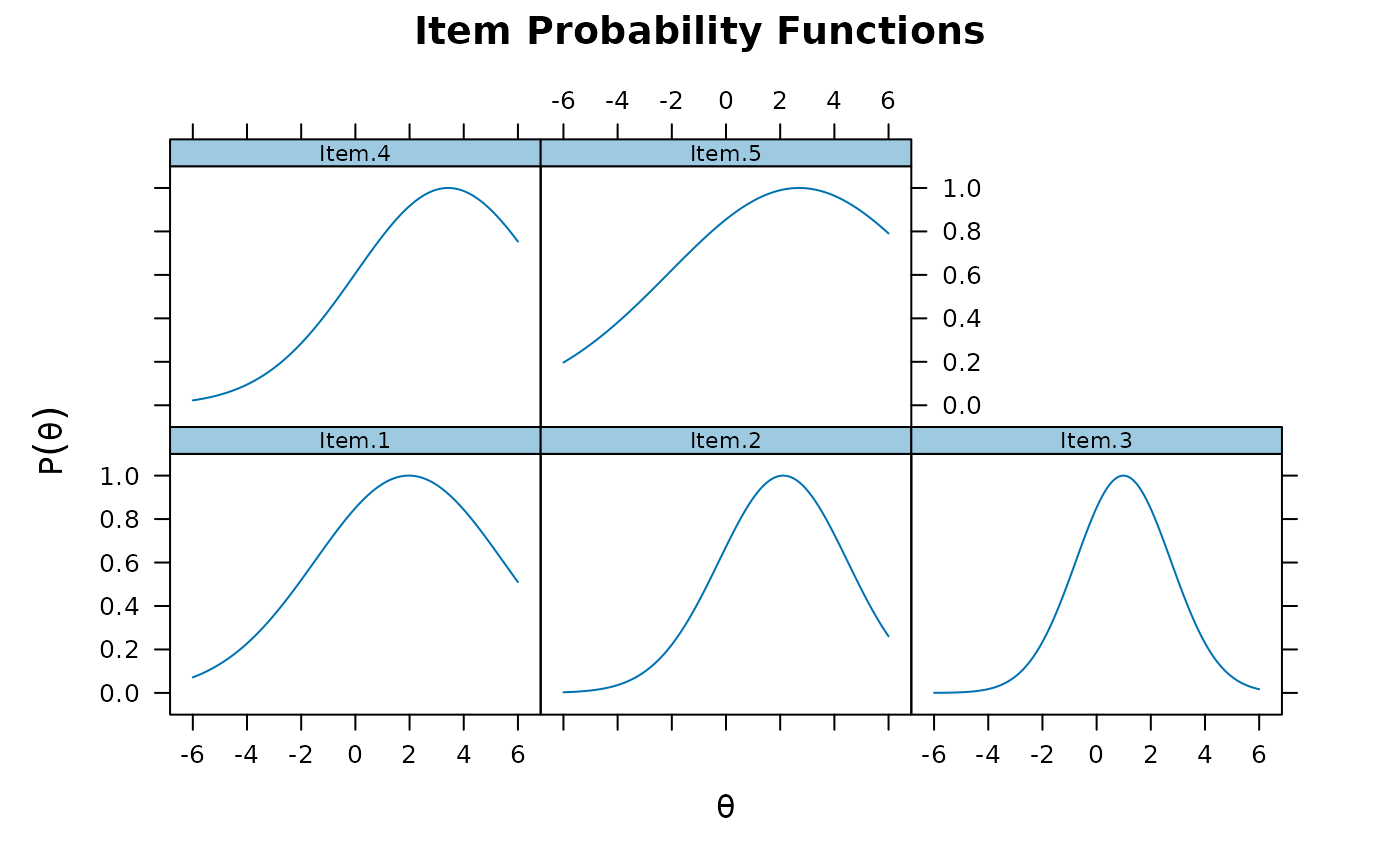
plot(mod1)
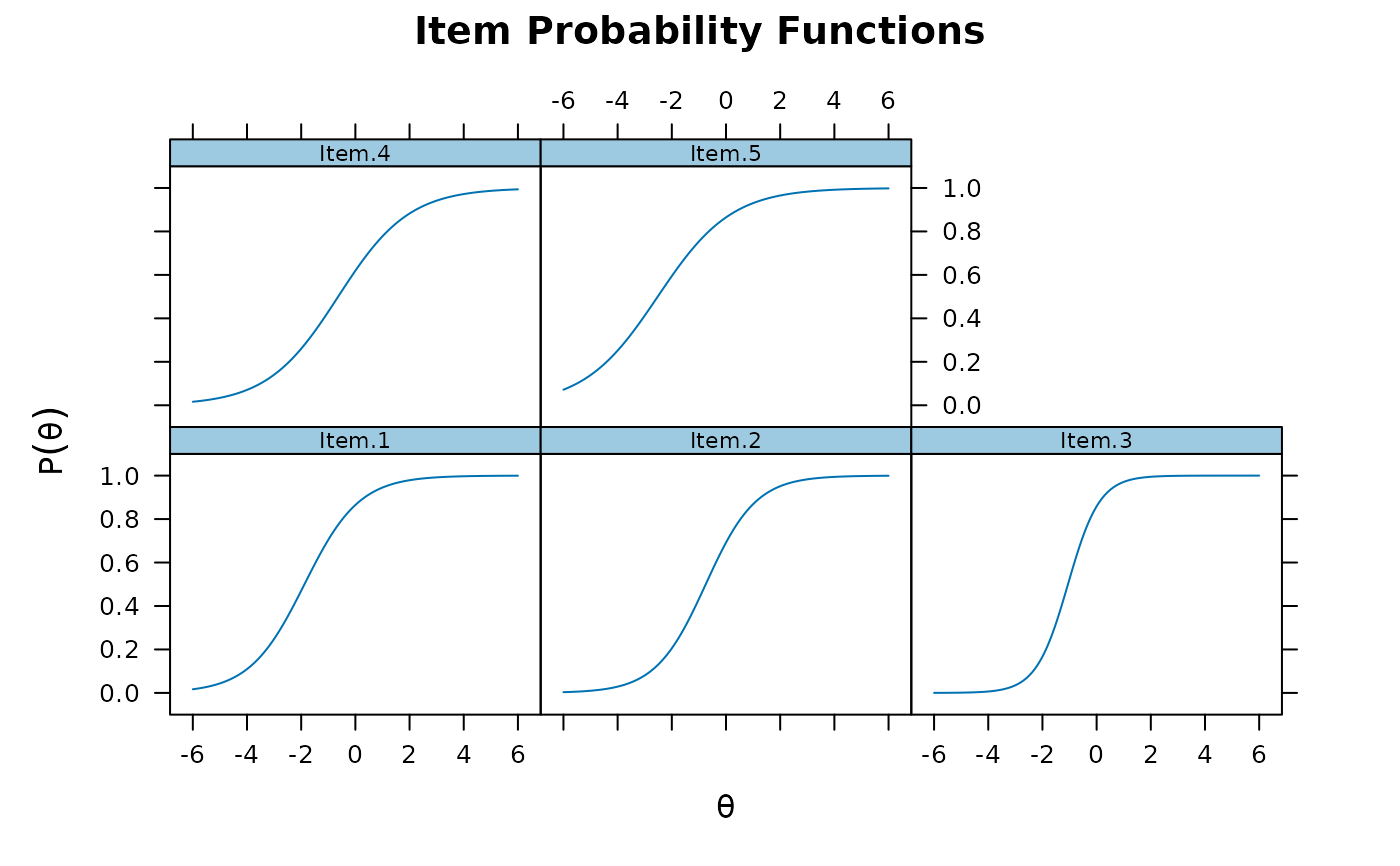
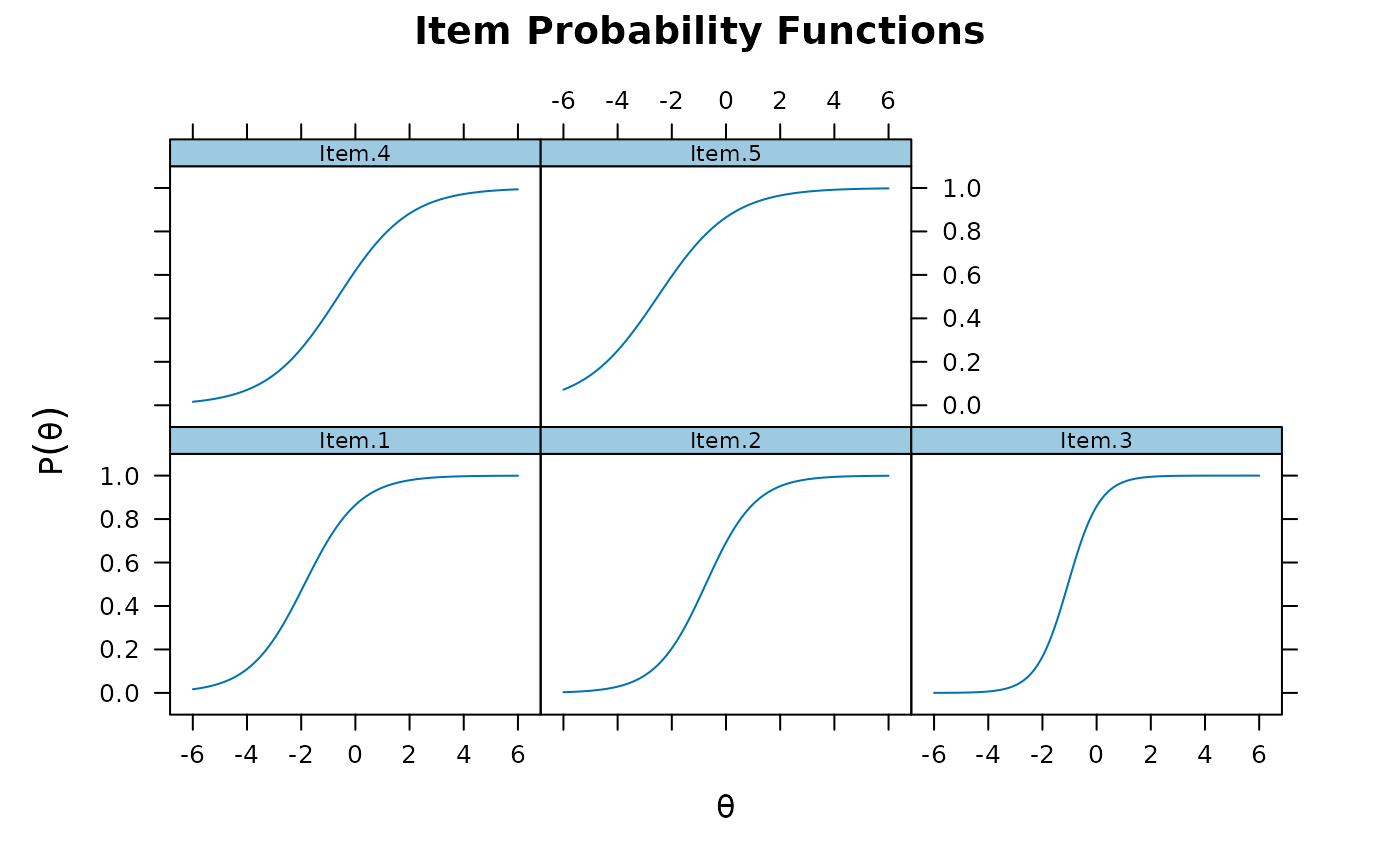
 plot(mod1, type = 'trace')
plot(mod1, type = 'trace')
 # \donttest{
(mod2 <- mirt(data, 1, SE = TRUE)) #standard errors via the Oakes method
#>
#> Call:
#> mirt(data = data, model = 1, SE = TRUE)
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 28 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Information matrix estimated with method: Oakes
#> Second-order test: model is a possible local maximum
#> Condition number of information matrix = 30.23088
#>
#> Log-likelihood = -2658.805
#> Estimated parameters: 10
#> AIC = 5337.61
#> BIC = 5386.688; SABIC = 5354.927
#> G2 (21) = 31.7, p = 0.0628
#> RMSEA = 0.023, CFI = NaN, TLI = NaN
(mod2 <- mirt(data, 1, SE = TRUE, SE.type = 'SEM')) #standard errors with SEM method
#>
#> Call:
#> mirt(data = data, model = 1, SE = TRUE, SE.type = "SEM")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-05 tolerance after 74 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: none
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Information matrix estimated with method: SEM
#> Second-order test: model is a possible local maximum
#> Condition number of information matrix = 30.12751
#>
#> Log-likelihood = -2658.805
#> Estimated parameters: 10
#> AIC = 5337.61
#> BIC = 5386.688; SABIC = 5354.927
#> G2 (21) = 31.7, p = 0.0628
#> RMSEA = 0.023, CFI = NaN, TLI = NaN
coef(mod2)
#> $Item.1
#> a1 d g u
#> par 0.988 1.856 0 1
#> CI_2.5 0.639 1.599 NA NA
#> CI_97.5 1.336 2.112 NA NA
#>
#> $Item.2
#> a1 d g u
#> par 1.081 0.808 0 1
#> CI_2.5 0.755 0.629 NA NA
#> CI_97.5 1.407 0.987 NA NA
#>
#> $Item.3
#> a1 d g u
#> par 1.707 1.805 0 1
#> CI_2.5 1.086 1.395 NA NA
#> CI_97.5 2.329 2.215 NA NA
#>
#> $Item.4
#> a1 d g u
#> par 0.765 0.486 0 1
#> CI_2.5 0.500 0.339 NA NA
#> CI_97.5 1.030 0.633 NA NA
#>
#> $Item.5
#> a1 d g u
#> par 0.736 1.854 0 1
#> CI_2.5 0.437 1.630 NA NA
#> CI_97.5 1.034 2.079 NA NA
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#> CI_2.5 NA NA
#> CI_97.5 NA NA
#>
(mod3 <- mirt(data, 1, SE = TRUE, SE.type = 'Richardson')) #with numerical Richardson method
#>
#> Call:
#> mirt(data = data, model = 1, SE = TRUE, SE.type = "Richardson")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 28 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Information matrix estimated with method: Richardson
#> Second-order test: model is a possible local maximum
#> Condition number of information matrix = 30.23102
#>
#> Log-likelihood = -2658.805
#> Estimated parameters: 10
#> AIC = 5337.61
#> BIC = 5386.688; SABIC = 5354.927
#> G2 (21) = 31.7, p = 0.0628
#> RMSEA = 0.023, CFI = NaN, TLI = NaN
residuals(mod1)
#> LD matrix (lower triangle) and standardized residual correlations (upper triangle)
#>
#> Upper triangle summary:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> -0.037 -0.020 -0.007 0.001 0.024 0.051
#>
#> Item.1 Item.2 Item.3 Item.4 Item.5
#> Item.1 -0.021 -0.029 0.051 0.049
#> Item.2 0.453 0.033 -0.016 -0.037
#> Item.3 0.854 1.060 -0.012 -0.002
#> Item.4 2.572 0.267 0.153 0.000
#> Item.5 2.389 1.384 0.003 0.000
plot(mod1) #test score function
# \donttest{
(mod2 <- mirt(data, 1, SE = TRUE)) #standard errors via the Oakes method
#>
#> Call:
#> mirt(data = data, model = 1, SE = TRUE)
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 28 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Information matrix estimated with method: Oakes
#> Second-order test: model is a possible local maximum
#> Condition number of information matrix = 30.23088
#>
#> Log-likelihood = -2658.805
#> Estimated parameters: 10
#> AIC = 5337.61
#> BIC = 5386.688; SABIC = 5354.927
#> G2 (21) = 31.7, p = 0.0628
#> RMSEA = 0.023, CFI = NaN, TLI = NaN
(mod2 <- mirt(data, 1, SE = TRUE, SE.type = 'SEM')) #standard errors with SEM method
#>
#> Call:
#> mirt(data = data, model = 1, SE = TRUE, SE.type = "SEM")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-05 tolerance after 74 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: none
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Information matrix estimated with method: SEM
#> Second-order test: model is a possible local maximum
#> Condition number of information matrix = 30.12751
#>
#> Log-likelihood = -2658.805
#> Estimated parameters: 10
#> AIC = 5337.61
#> BIC = 5386.688; SABIC = 5354.927
#> G2 (21) = 31.7, p = 0.0628
#> RMSEA = 0.023, CFI = NaN, TLI = NaN
coef(mod2)
#> $Item.1
#> a1 d g u
#> par 0.988 1.856 0 1
#> CI_2.5 0.639 1.599 NA NA
#> CI_97.5 1.336 2.112 NA NA
#>
#> $Item.2
#> a1 d g u
#> par 1.081 0.808 0 1
#> CI_2.5 0.755 0.629 NA NA
#> CI_97.5 1.407 0.987 NA NA
#>
#> $Item.3
#> a1 d g u
#> par 1.707 1.805 0 1
#> CI_2.5 1.086 1.395 NA NA
#> CI_97.5 2.329 2.215 NA NA
#>
#> $Item.4
#> a1 d g u
#> par 0.765 0.486 0 1
#> CI_2.5 0.500 0.339 NA NA
#> CI_97.5 1.030 0.633 NA NA
#>
#> $Item.5
#> a1 d g u
#> par 0.736 1.854 0 1
#> CI_2.5 0.437 1.630 NA NA
#> CI_97.5 1.034 2.079 NA NA
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#> CI_2.5 NA NA
#> CI_97.5 NA NA
#>
(mod3 <- mirt(data, 1, SE = TRUE, SE.type = 'Richardson')) #with numerical Richardson method
#>
#> Call:
#> mirt(data = data, model = 1, SE = TRUE, SE.type = "Richardson")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 28 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Information matrix estimated with method: Richardson
#> Second-order test: model is a possible local maximum
#> Condition number of information matrix = 30.23102
#>
#> Log-likelihood = -2658.805
#> Estimated parameters: 10
#> AIC = 5337.61
#> BIC = 5386.688; SABIC = 5354.927
#> G2 (21) = 31.7, p = 0.0628
#> RMSEA = 0.023, CFI = NaN, TLI = NaN
residuals(mod1)
#> LD matrix (lower triangle) and standardized residual correlations (upper triangle)
#>
#> Upper triangle summary:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> -0.037 -0.020 -0.007 0.001 0.024 0.051
#>
#> Item.1 Item.2 Item.3 Item.4 Item.5
#> Item.1 -0.021 -0.029 0.051 0.049
#> Item.2 0.453 0.033 -0.016 -0.037
#> Item.3 0.854 1.060 -0.012 -0.002
#> Item.4 2.572 0.267 0.153 0.000
#> Item.5 2.389 1.384 0.003 0.000
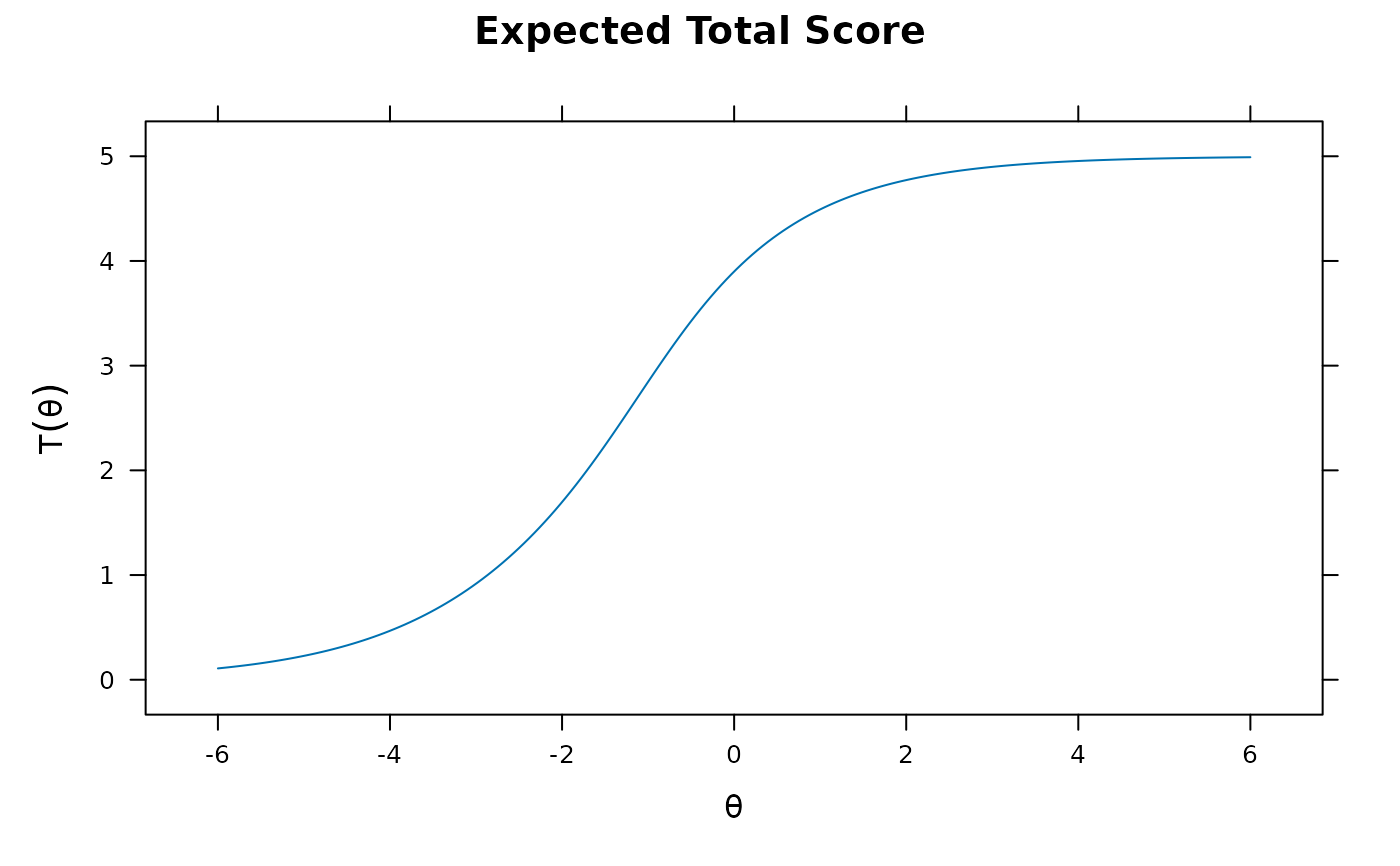
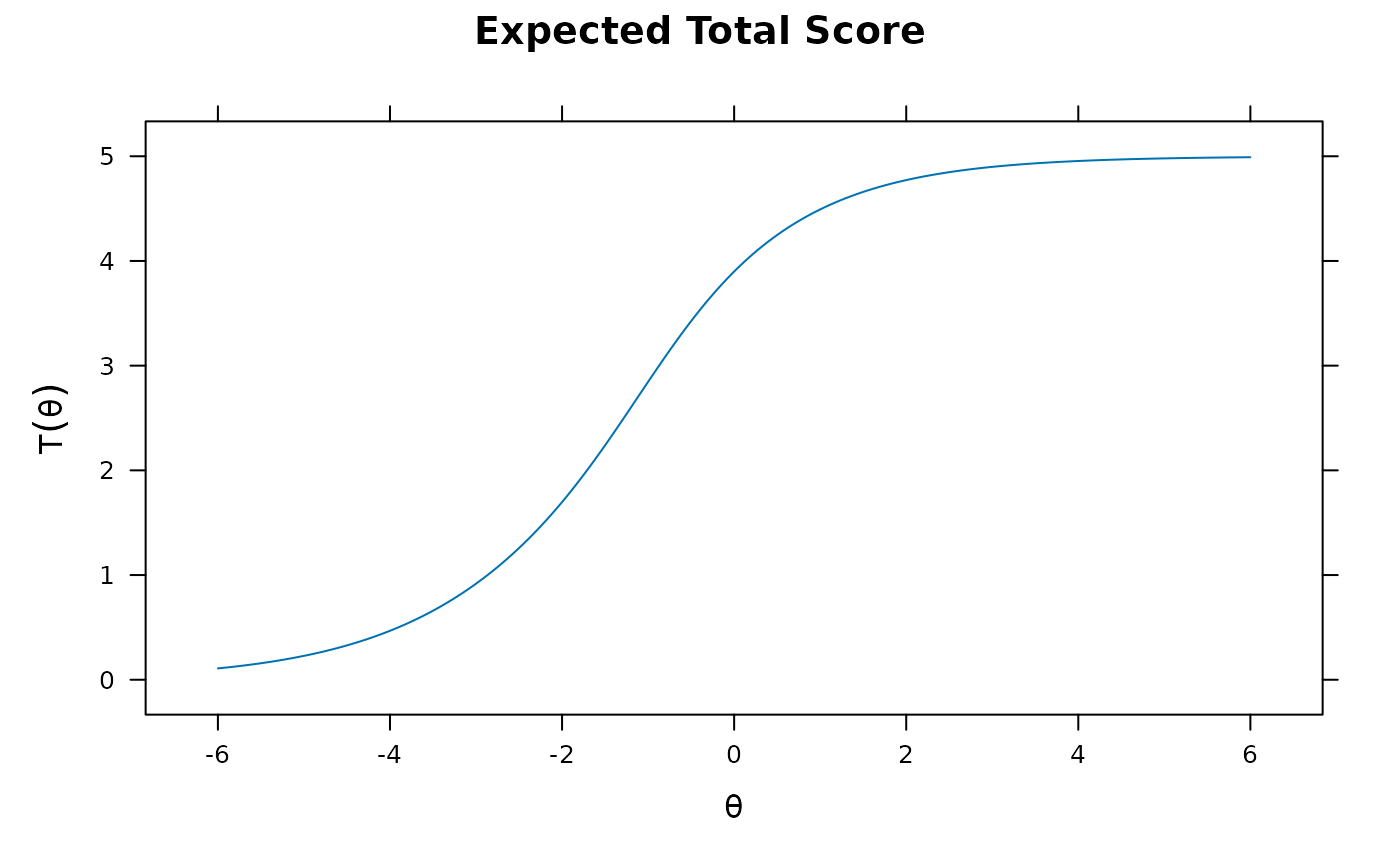
plot(mod1) #test score function
 plot(mod1, type = 'trace') #trace lines
plot(mod1, type = 'trace') #trace lines
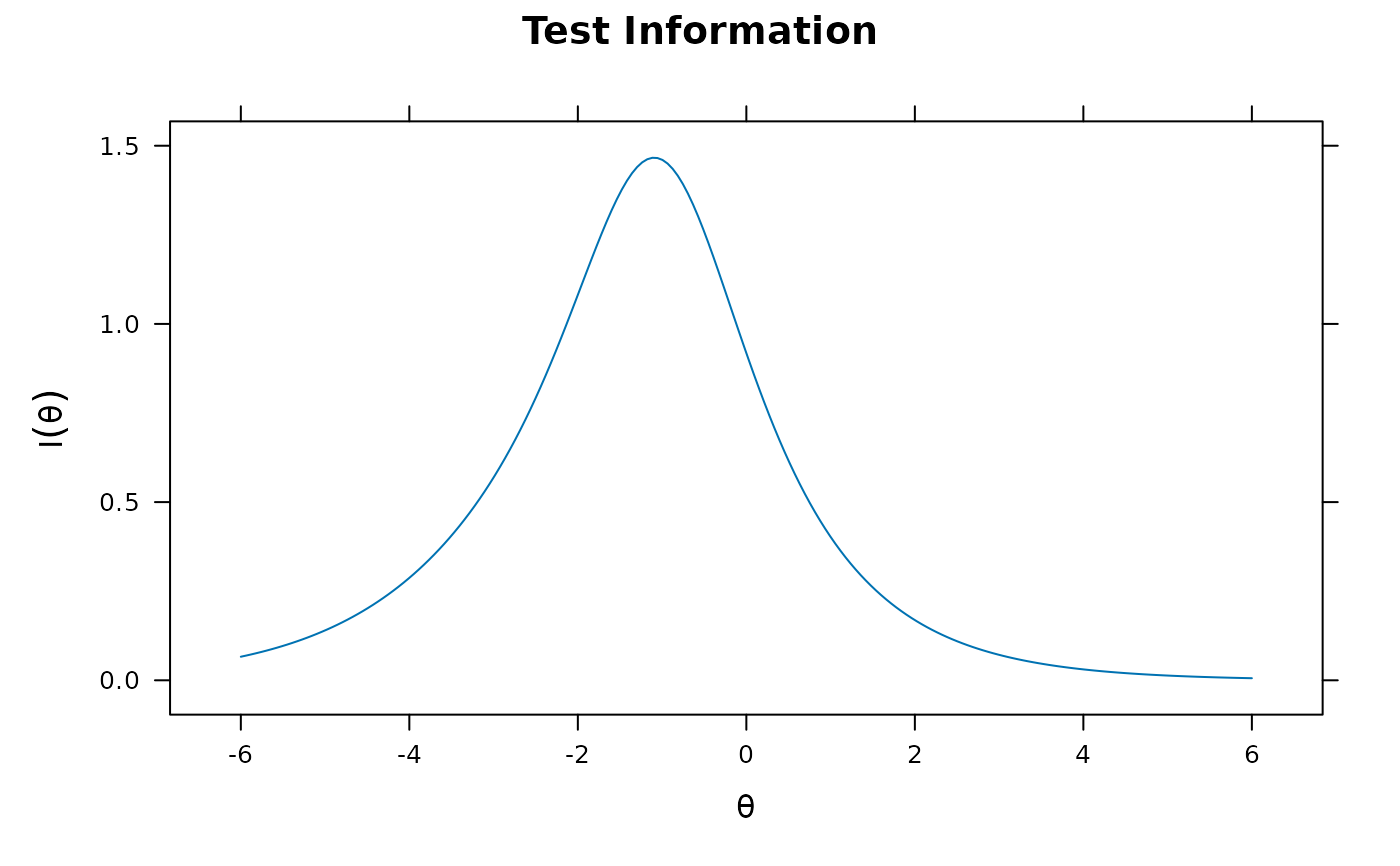
 plot(mod2, type = 'info') #test information
plot(mod2, type = 'info') #test information
 plot(mod2, MI=200) #expected total score with 95% confidence intervals
plot(mod2, MI=200) #expected total score with 95% confidence intervals
 # estimated 3PL model for item 5 only
(mod1.3PL <- mirt(data, 1, itemtype = c('2PL', '2PL', '2PL', '2PL', '3PL')))
#>
#> Call:
#> mirt(data = data, model = 1, itemtype = c("2PL", "2PL", "2PL",
#> "2PL", "3PL"))
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 43 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -2658.794
#> Estimated parameters: 11
#> AIC = 5339.587
#> BIC = 5393.573; SABIC = 5358.636
#> G2 (20) = 31.68, p = 0.0469
#> RMSEA = 0.024, CFI = NaN, TLI = NaN
coef(mod1.3PL)
#> $Item.1
#> a1 d g u
#> par 0.987 1.855 0 1
#>
#> $Item.2
#> a1 d g u
#> par 1.082 0.808 0 1
#>
#> $Item.3
#> a1 d g u
#> par 1.706 1.805 0 1
#>
#> $Item.4
#> a1 d g u
#> par 0.764 0.486 0 1
#>
#> $Item.5
#> a1 d g u
#> par 0.778 1.643 0.161 1
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
# internally g and u pars are stored as logits, so usually a good idea to include normal prior
# to help stabilize the parameters. For a value around .182 use a mean
# of -1.5 (since 1 / (1 + exp(-(-1.5))) == .182)
model <- 'F = 1-5
PRIOR = (5, g, norm, -1.5, 3)'
mod1.3PL.norm <- mirt(data, model, itemtype = c('2PL', '2PL', '2PL', '2PL', '3PL'))
coef(mod1.3PL.norm)
#> $Item.1
#> a1 d g u
#> par 0.987 1.855 0 1
#>
#> $Item.2
#> a1 d g u
#> par 1.083 0.808 0 1
#>
#> $Item.3
#> a1 d g u
#> par 1.706 1.804 0 1
#>
#> $Item.4
#> a1 d g u
#> par 0.764 0.486 0 1
#>
#> $Item.5
#> a1 d g u
#> par 0.788 1.6 0.19 1
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
#limited information fit statistics
M2(mod1.3PL.norm)
#> M2 df p RMSEA RMSEA_5 RMSEA_95 SRMSR TLI
#> stats 8.800082 4 0.06629543 0.03465864 0 0.06610847 0.03207363 0.9454563
#> CFI
#> stats 0.9781825
# unidimensional ideal point model
idealpt <- mirt(data, 1, itemtype = 'ideal')
plot(idealpt, type = 'trace', facet_items = TRUE)
# estimated 3PL model for item 5 only
(mod1.3PL <- mirt(data, 1, itemtype = c('2PL', '2PL', '2PL', '2PL', '3PL')))
#>
#> Call:
#> mirt(data = data, model = 1, itemtype = c("2PL", "2PL", "2PL",
#> "2PL", "3PL"))
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 43 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -2658.794
#> Estimated parameters: 11
#> AIC = 5339.587
#> BIC = 5393.573; SABIC = 5358.636
#> G2 (20) = 31.68, p = 0.0469
#> RMSEA = 0.024, CFI = NaN, TLI = NaN
coef(mod1.3PL)
#> $Item.1
#> a1 d g u
#> par 0.987 1.855 0 1
#>
#> $Item.2
#> a1 d g u
#> par 1.082 0.808 0 1
#>
#> $Item.3
#> a1 d g u
#> par 1.706 1.805 0 1
#>
#> $Item.4
#> a1 d g u
#> par 0.764 0.486 0 1
#>
#> $Item.5
#> a1 d g u
#> par 0.778 1.643 0.161 1
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
# internally g and u pars are stored as logits, so usually a good idea to include normal prior
# to help stabilize the parameters. For a value around .182 use a mean
# of -1.5 (since 1 / (1 + exp(-(-1.5))) == .182)
model <- 'F = 1-5
PRIOR = (5, g, norm, -1.5, 3)'
mod1.3PL.norm <- mirt(data, model, itemtype = c('2PL', '2PL', '2PL', '2PL', '3PL'))
coef(mod1.3PL.norm)
#> $Item.1
#> a1 d g u
#> par 0.987 1.855 0 1
#>
#> $Item.2
#> a1 d g u
#> par 1.083 0.808 0 1
#>
#> $Item.3
#> a1 d g u
#> par 1.706 1.804 0 1
#>
#> $Item.4
#> a1 d g u
#> par 0.764 0.486 0 1
#>
#> $Item.5
#> a1 d g u
#> par 0.788 1.6 0.19 1
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
#limited information fit statistics
M2(mod1.3PL.norm)
#> M2 df p RMSEA RMSEA_5 RMSEA_95 SRMSR TLI
#> stats 8.800082 4 0.06629543 0.03465864 0 0.06610847 0.03207363 0.9454563
#> CFI
#> stats 0.9781825
# unidimensional ideal point model
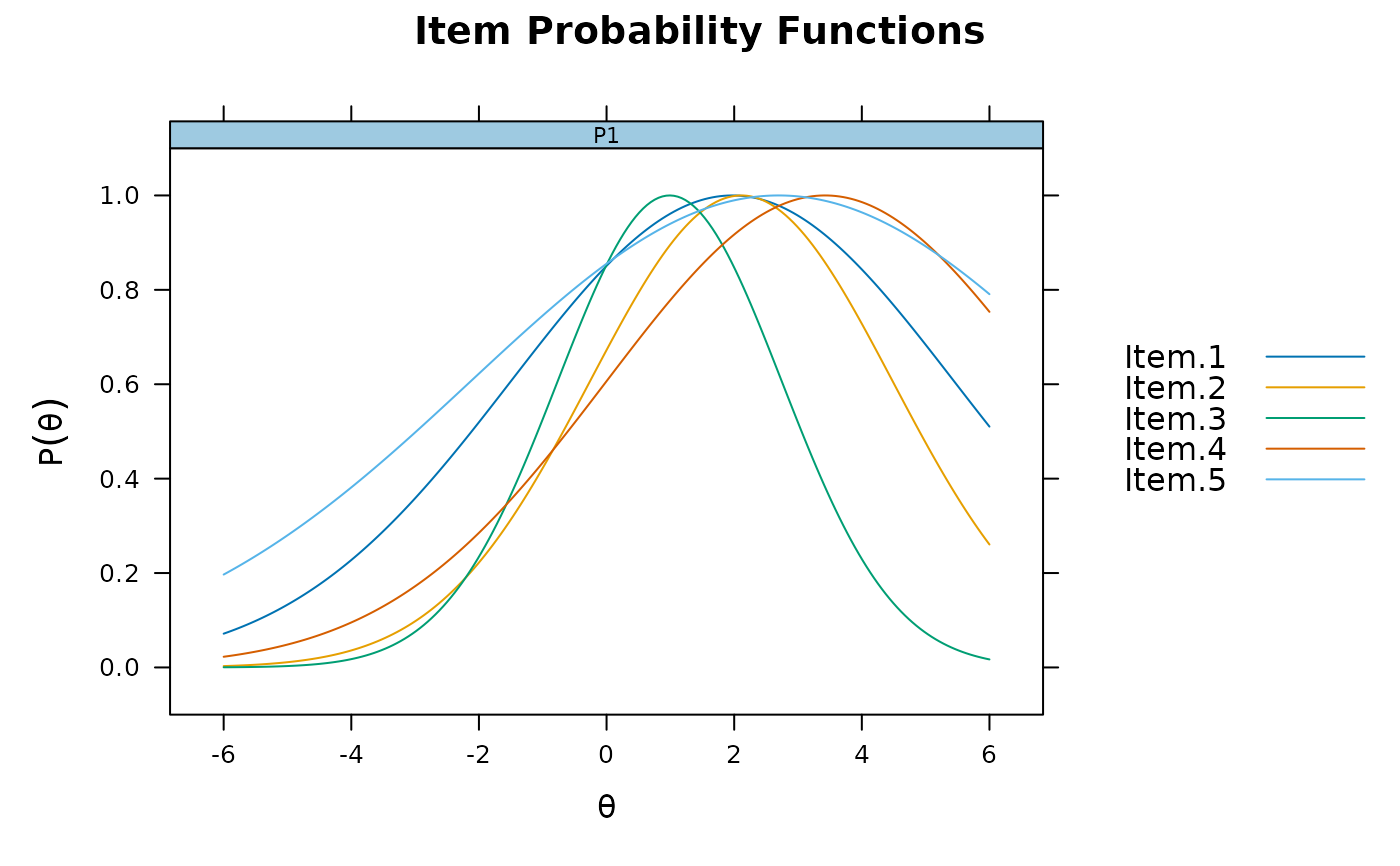
idealpt <- mirt(data, 1, itemtype = 'ideal')
plot(idealpt, type = 'trace', facet_items = TRUE)
 plot(idealpt, type = 'trace', facet_items = FALSE)
plot(idealpt, type = 'trace', facet_items = FALSE)
 # two factors (exploratory)
mod2 <- mirt(data, 2)
coef(mod2)
#> $Item.1
#> a1 a2 d g u
#> par -2.007 0.87 2.648 0 1
#>
#> $Item.2
#> a1 a2 d g u
#> par -0.849 -0.522 0.788 0 1
#>
#> $Item.3
#> a1 a2 d g u
#> par -2.153 -1.837 2.483 0 1
#>
#> $Item.4
#> a1 a2 d g u
#> par -0.756 -0.028 0.485 0 1
#>
#> $Item.5
#> a1 a2 d g u
#> par -0.757 0 1.864 0 1
#>
#> $GroupPars
#> MEAN_1 MEAN_2 COV_11 COV_21 COV_22
#> par 0 0 1 0 1
#>
summary(mod2, rotate = 'oblimin') #oblimin rotation
#>
#> Rotation: oblimin
#>
#> Rotated factor loadings:
#>
#> F1 F2 h2
#> Item.1 0.7944 -0.0111 0.623
#> Item.2 0.0804 0.4630 0.255
#> Item.3 -0.0129 0.8628 0.734
#> Item.4 0.2794 0.1925 0.165
#> Item.5 0.2929 0.1772 0.165
#>
#> Rotated SS loadings: 0.802 1.027
#>
#> Factor correlations:
#>
#> F1 F2
#> F1 1.000
#> F2 0.463 1
residuals(mod2)
#> LD matrix (lower triangle) and standardized residual correlations (upper triangle)
#>
#> Upper triangle summary:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> -0.018 -0.001 0.000 0.000 0.002 0.011
#>
#> Item.1 Item.2 Item.3 Item.4 Item.5
#> Item.1 -0.001 0.001 0.002 0.003
#> Item.2 0.001 0.000 0.011 -0.018
#> Item.3 0.001 0.000 -0.002 0.006
#> Item.4 0.002 0.111 0.004 -0.001
#> Item.5 0.008 0.325 0.041 0.001
plot(mod2)
# two factors (exploratory)
mod2 <- mirt(data, 2)
coef(mod2)
#> $Item.1
#> a1 a2 d g u
#> par -2.007 0.87 2.648 0 1
#>
#> $Item.2
#> a1 a2 d g u
#> par -0.849 -0.522 0.788 0 1
#>
#> $Item.3
#> a1 a2 d g u
#> par -2.153 -1.837 2.483 0 1
#>
#> $Item.4
#> a1 a2 d g u
#> par -0.756 -0.028 0.485 0 1
#>
#> $Item.5
#> a1 a2 d g u
#> par -0.757 0 1.864 0 1
#>
#> $GroupPars
#> MEAN_1 MEAN_2 COV_11 COV_21 COV_22
#> par 0 0 1 0 1
#>
summary(mod2, rotate = 'oblimin') #oblimin rotation
#>
#> Rotation: oblimin
#>
#> Rotated factor loadings:
#>
#> F1 F2 h2
#> Item.1 0.7944 -0.0111 0.623
#> Item.2 0.0804 0.4630 0.255
#> Item.3 -0.0129 0.8628 0.734
#> Item.4 0.2794 0.1925 0.165
#> Item.5 0.2929 0.1772 0.165
#>
#> Rotated SS loadings: 0.802 1.027
#>
#> Factor correlations:
#>
#> F1 F2
#> F1 1.000
#> F2 0.463 1
residuals(mod2)
#> LD matrix (lower triangle) and standardized residual correlations (upper triangle)
#>
#> Upper triangle summary:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> -0.018 -0.001 0.000 0.000 0.002 0.011
#>
#> Item.1 Item.2 Item.3 Item.4 Item.5
#> Item.1 -0.001 0.001 0.002 0.003
#> Item.2 0.001 0.000 0.011 -0.018
#> Item.3 0.001 0.000 -0.002 0.006
#> Item.4 0.002 0.111 0.004 -0.001
#> Item.5 0.008 0.325 0.041 0.001
plot(mod2)
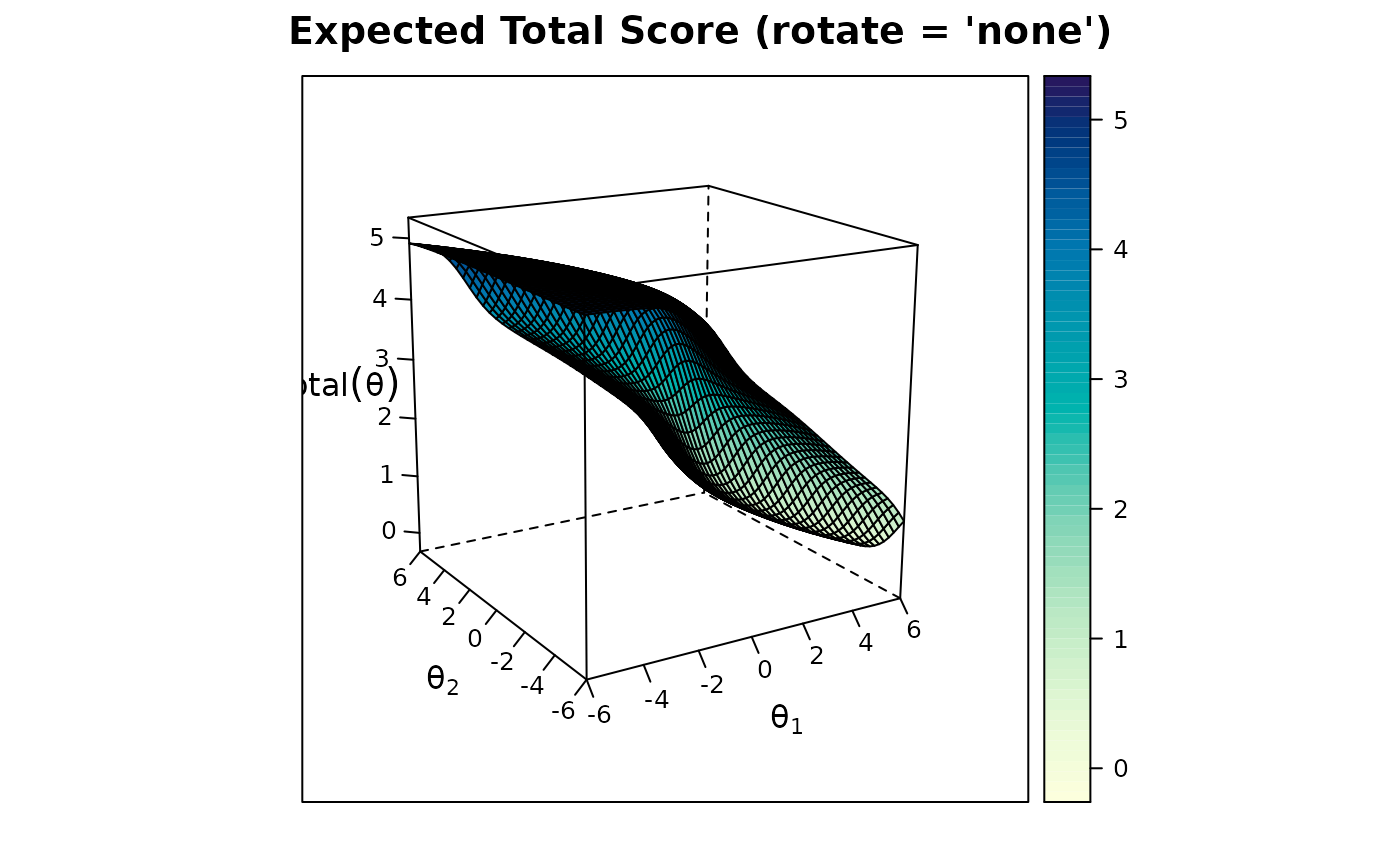 plot(mod2, rotate = 'oblimin')
plot(mod2, rotate = 'oblimin')
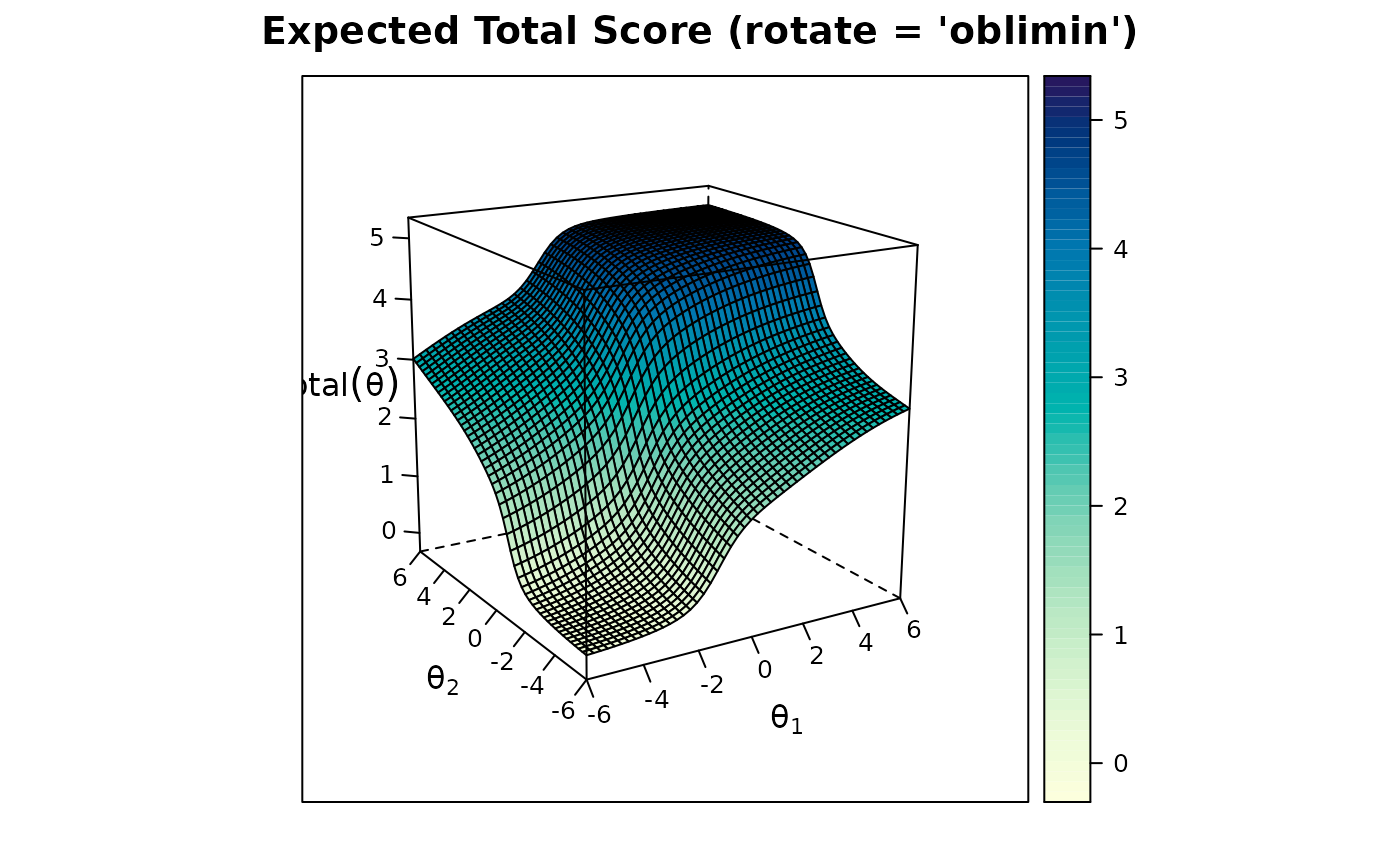 anova(mod1, mod2) #compare the two models
#> AIC SABIC HQ BIC logLik X2 df p
#> mod1 5337.610 5354.927 5356.263 5386.688 -2658.805
#> mod2 5335.039 5359.283 5361.153 5403.748 -2653.520 10.571 4 0.032
scoresfull <- fscores(mod2) #factor scores for each response pattern
head(scoresfull)
#> F1 F2
#> [1,] -1.700518 -1.711769
#> [2,] -1.700518 -1.711769
#> [3,] -1.700518 -1.711769
#> [4,] -1.700518 -1.711769
#> [5,] -1.700518 -1.711769
#> [6,] -1.700518 -1.711769
scorestable <- fscores(mod2, full.scores = FALSE) #save factor score table
#>
#> Method: EAP
#> Rotate: oblimin
#>
#> Empirical Reliability:
#>
#> F1 F2
#> 0.2717 0.3565
head(scorestable)
#> Item.1 Item.2 Item.3 Item.4 Item.5 F1 F2 SE_F1
#> [1,] 0 0 0 0 0 -1.700518 -1.7117695 0.8233469
#> [2,] 0 0 0 0 1 -1.442222 -1.5315376 0.8291567
#> [3,] 0 0 0 1 0 -1.449006 -1.5246585 0.8289641
#> [4,] 0 0 0 1 1 -1.186299 -1.3432791 0.8376106
#> [5,] 0 0 1 0 0 -1.369488 -0.7080810 0.8344641
#> [6,] 0 0 1 0 1 -1.099377 -0.5102857 0.8455261
#> SE_F2
#> [1,] 0.7705757
#> [2,] 0.7691490
#> [3,] 0.7691109
#> [4,] 0.7711287
#> [5,] 0.7962932
#> [6,] 0.8101314
# confirmatory (as an example, model is not identified since you need 3 items per factor)
# Two ways to define a confirmatory model: with mirt.model, or with a string
# these model definitions are equivalent
cmodel <- mirt.model('
F1 = 1,4,5
F2 = 2,3')
cmodel2 <- 'F1 = 1,4,5
F2 = 2,3'
cmod <- mirt(data, cmodel)
# cmod <- mirt(data, cmodel2) # same as above
coef(cmod)
#> $Item.1
#> a1 a2 d g u
#> par 1.792 0 2.358 0 1
#>
#> $Item.2
#> a1 a2 d g u
#> par 0 1.427 0.9 0 1
#>
#> $Item.3
#> a1 a2 d g u
#> par 0 1.559 1.725 0 1
#>
#> $Item.4
#> a1 a2 d g u
#> par 0.743 0 0.483 0 1
#>
#> $Item.5
#> a1 a2 d g u
#> par 0.763 0 1.867 0 1
#>
#> $GroupPars
#> MEAN_1 MEAN_2 COV_11 COV_21 COV_22
#> par 0 0 1 0 1
#>
anova(cmod, mod2)
#> AIC SABIC HQ BIC logLik X2 df p
#> cmod 5392.596 5409.913 5411.249 5441.674 -2686.298
#> mod2 5335.039 5359.283 5361.153 5403.748 -2653.520 65.557 4 0
# check if identified by computing information matrix
(cmod <- mirt(data, cmodel, SE = TRUE))
#> Warning: Could not invert information matrix; model may not be (empirically) identified.
#>
#> Call:
#> mirt(data = data, model = cmodel, SE = TRUE)
#>
#> Full-information item factor analysis with 2 factor(s).
#> Converged within 1e-04 tolerance after 125 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 31
#> Latent density type: Gaussian
#>
#> Information matrix estimated with method: Oakes
#> Second-order test: model is not a maximum or the information matrix is too inaccurate
#>
#> Log-likelihood = -2686.298
#> Estimated parameters: 10
#> AIC = 5392.596
#> BIC = 5441.674; SABIC = 5409.913
#> G2 (21) = 86.69, p = 0
#> RMSEA = 0.056, CFI = NaN, TLI = NaN
###########
# data from the 'ltm' package in numeric format
itemstats(Science)
#> $overall
#> N mean_total.score sd_total.score ave.r sd.r alpha SEM.alpha
#> 392 11.668 2.003 0.275 0.098 0.598 1.27
#>
#> $itemstats
#> N mean sd total.r total.r_if_rm alpha_if_rm
#> Comfort 392 3.120 0.588 0.596 0.352 0.552
#> Work 392 2.722 0.807 0.666 0.332 0.567
#> Future 392 2.990 0.757 0.748 0.488 0.437
#> Benefit 392 2.837 0.802 0.684 0.363 0.541
#>
#> $proportions
#> 1 2 3 4
#> Comfort 0.013 0.082 0.679 0.227
#> Work 0.084 0.250 0.526 0.140
#> Future 0.036 0.184 0.536 0.245
#> Benefit 0.054 0.255 0.492 0.199
#>
pmod1 <- mirt(Science, 1)
plot(pmod1)
anova(mod1, mod2) #compare the two models
#> AIC SABIC HQ BIC logLik X2 df p
#> mod1 5337.610 5354.927 5356.263 5386.688 -2658.805
#> mod2 5335.039 5359.283 5361.153 5403.748 -2653.520 10.571 4 0.032
scoresfull <- fscores(mod2) #factor scores for each response pattern
head(scoresfull)
#> F1 F2
#> [1,] -1.700518 -1.711769
#> [2,] -1.700518 -1.711769
#> [3,] -1.700518 -1.711769
#> [4,] -1.700518 -1.711769
#> [5,] -1.700518 -1.711769
#> [6,] -1.700518 -1.711769
scorestable <- fscores(mod2, full.scores = FALSE) #save factor score table
#>
#> Method: EAP
#> Rotate: oblimin
#>
#> Empirical Reliability:
#>
#> F1 F2
#> 0.2717 0.3565
head(scorestable)
#> Item.1 Item.2 Item.3 Item.4 Item.5 F1 F2 SE_F1
#> [1,] 0 0 0 0 0 -1.700518 -1.7117695 0.8233469
#> [2,] 0 0 0 0 1 -1.442222 -1.5315376 0.8291567
#> [3,] 0 0 0 1 0 -1.449006 -1.5246585 0.8289641
#> [4,] 0 0 0 1 1 -1.186299 -1.3432791 0.8376106
#> [5,] 0 0 1 0 0 -1.369488 -0.7080810 0.8344641
#> [6,] 0 0 1 0 1 -1.099377 -0.5102857 0.8455261
#> SE_F2
#> [1,] 0.7705757
#> [2,] 0.7691490
#> [3,] 0.7691109
#> [4,] 0.7711287
#> [5,] 0.7962932
#> [6,] 0.8101314
# confirmatory (as an example, model is not identified since you need 3 items per factor)
# Two ways to define a confirmatory model: with mirt.model, or with a string
# these model definitions are equivalent
cmodel <- mirt.model('
F1 = 1,4,5
F2 = 2,3')
cmodel2 <- 'F1 = 1,4,5
F2 = 2,3'
cmod <- mirt(data, cmodel)
# cmod <- mirt(data, cmodel2) # same as above
coef(cmod)
#> $Item.1
#> a1 a2 d g u
#> par 1.792 0 2.358 0 1
#>
#> $Item.2
#> a1 a2 d g u
#> par 0 1.427 0.9 0 1
#>
#> $Item.3
#> a1 a2 d g u
#> par 0 1.559 1.725 0 1
#>
#> $Item.4
#> a1 a2 d g u
#> par 0.743 0 0.483 0 1
#>
#> $Item.5
#> a1 a2 d g u
#> par 0.763 0 1.867 0 1
#>
#> $GroupPars
#> MEAN_1 MEAN_2 COV_11 COV_21 COV_22
#> par 0 0 1 0 1
#>
anova(cmod, mod2)
#> AIC SABIC HQ BIC logLik X2 df p
#> cmod 5392.596 5409.913 5411.249 5441.674 -2686.298
#> mod2 5335.039 5359.283 5361.153 5403.748 -2653.520 65.557 4 0
# check if identified by computing information matrix
(cmod <- mirt(data, cmodel, SE = TRUE))
#> Warning: Could not invert information matrix; model may not be (empirically) identified.
#>
#> Call:
#> mirt(data = data, model = cmodel, SE = TRUE)
#>
#> Full-information item factor analysis with 2 factor(s).
#> Converged within 1e-04 tolerance after 125 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 31
#> Latent density type: Gaussian
#>
#> Information matrix estimated with method: Oakes
#> Second-order test: model is not a maximum or the information matrix is too inaccurate
#>
#> Log-likelihood = -2686.298
#> Estimated parameters: 10
#> AIC = 5392.596
#> BIC = 5441.674; SABIC = 5409.913
#> G2 (21) = 86.69, p = 0
#> RMSEA = 0.056, CFI = NaN, TLI = NaN
###########
# data from the 'ltm' package in numeric format
itemstats(Science)
#> $overall
#> N mean_total.score sd_total.score ave.r sd.r alpha SEM.alpha
#> 392 11.668 2.003 0.275 0.098 0.598 1.27
#>
#> $itemstats
#> N mean sd total.r total.r_if_rm alpha_if_rm
#> Comfort 392 3.120 0.588 0.596 0.352 0.552
#> Work 392 2.722 0.807 0.666 0.332 0.567
#> Future 392 2.990 0.757 0.748 0.488 0.437
#> Benefit 392 2.837 0.802 0.684 0.363 0.541
#>
#> $proportions
#> 1 2 3 4
#> Comfort 0.013 0.082 0.679 0.227
#> Work 0.084 0.250 0.526 0.140
#> Future 0.036 0.184 0.536 0.245
#> Benefit 0.054 0.255 0.492 0.199
#>
pmod1 <- mirt(Science, 1)
plot(pmod1)
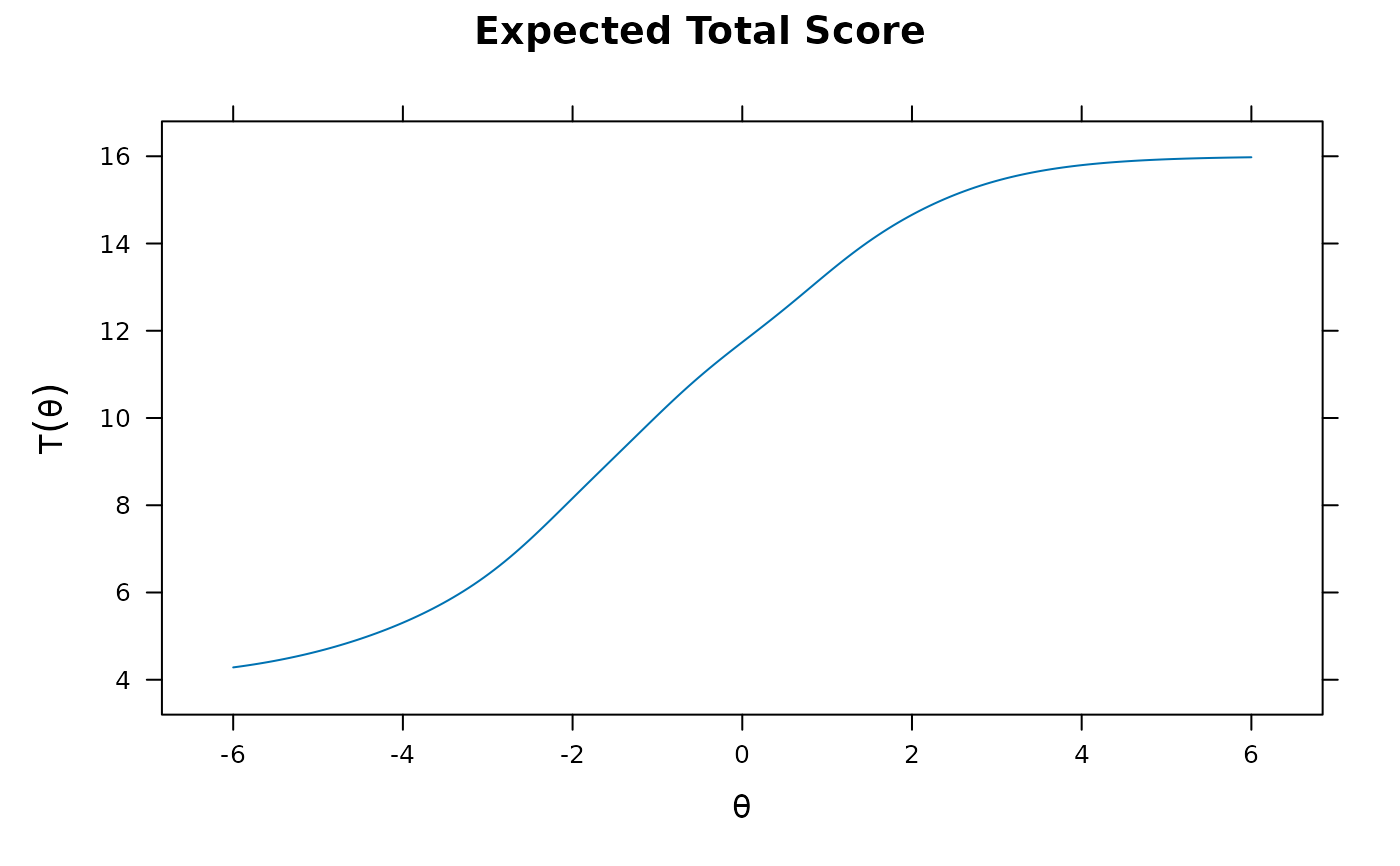 plot(pmod1, type = 'trace')
plot(pmod1, type = 'trace')
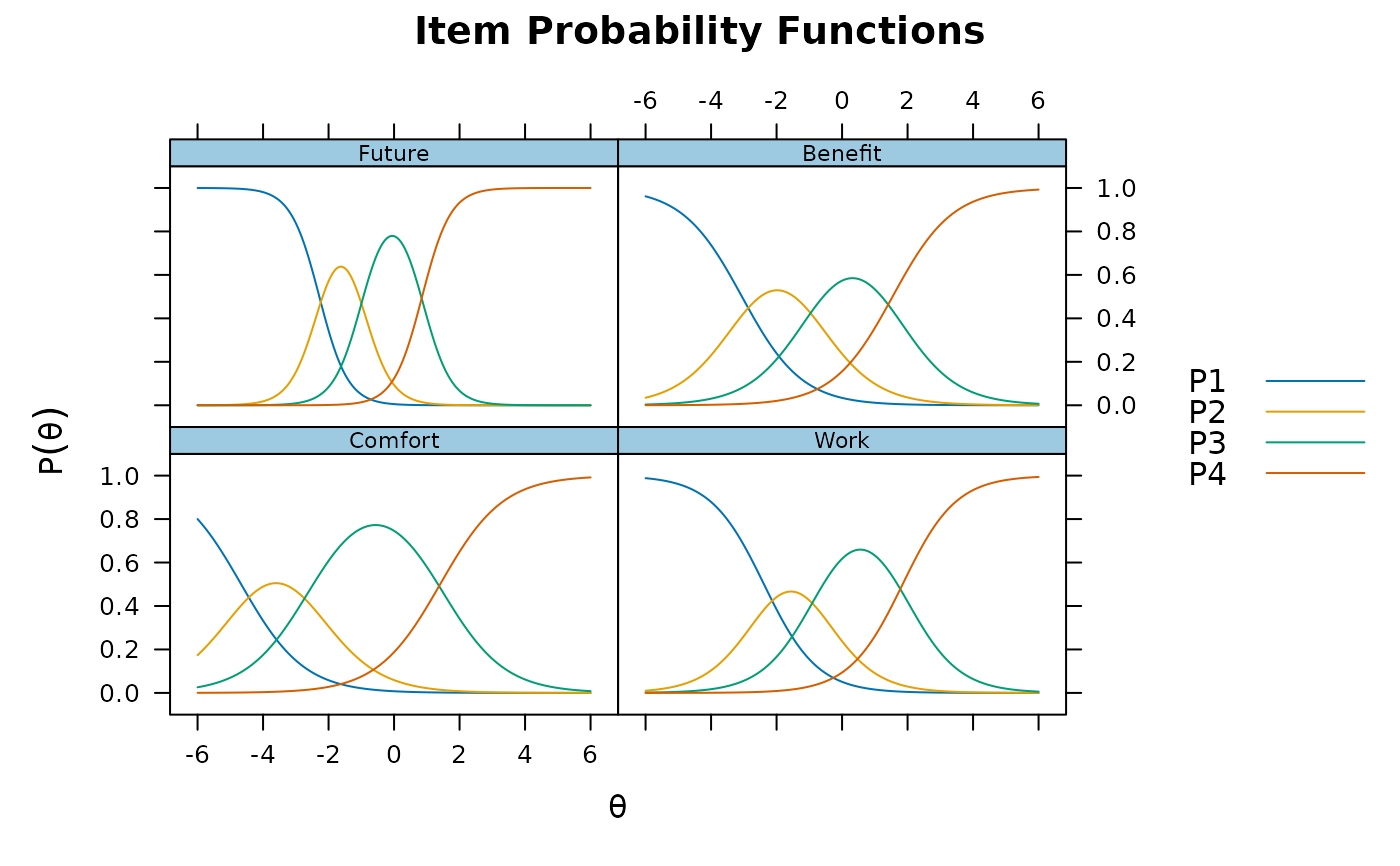 plot(pmod1, type = 'itemscore')
plot(pmod1, type = 'itemscore')
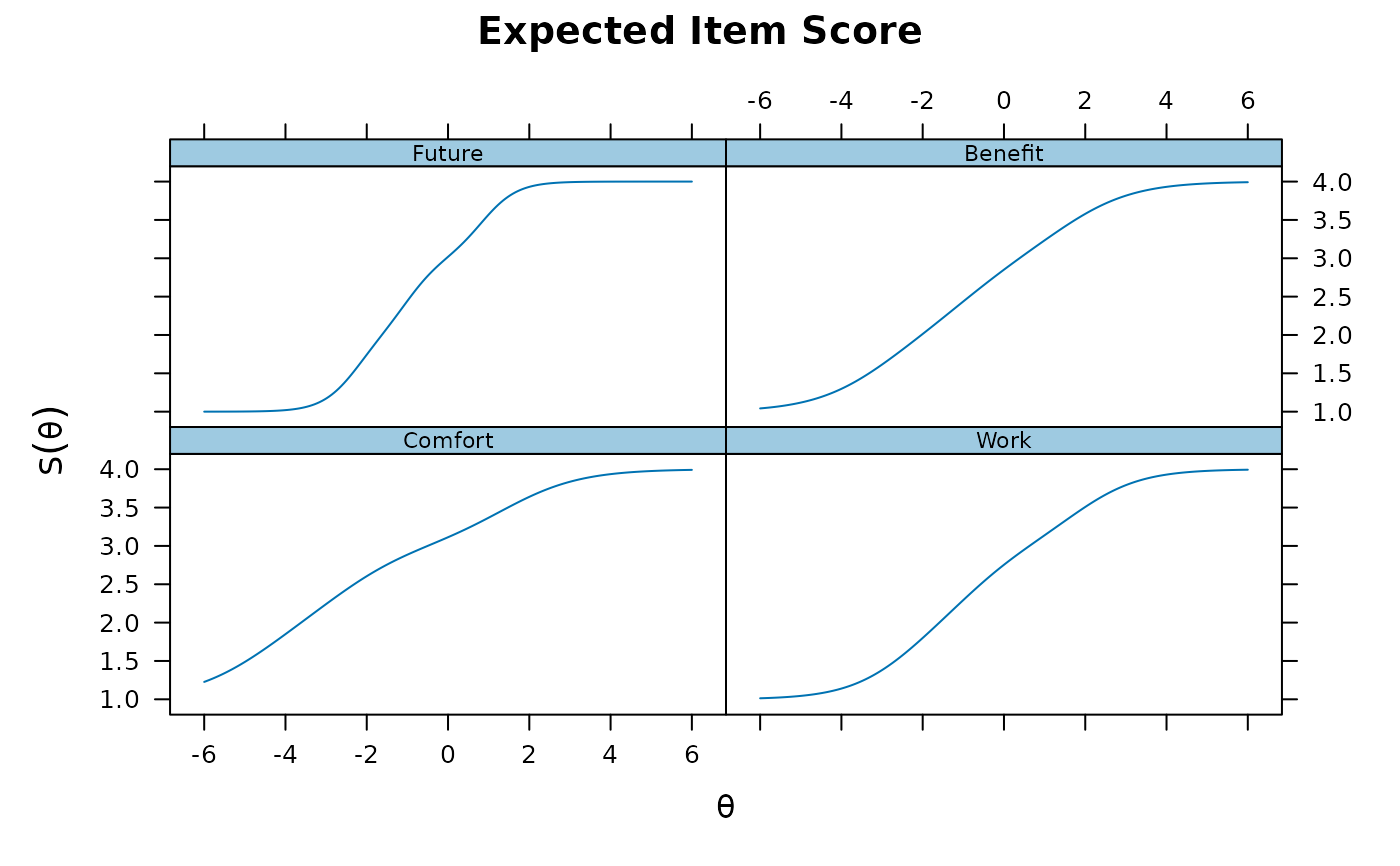 summary(pmod1)
#> F1 h2
#> Comfort 0.522 0.273
#> Work 0.584 0.342
#> Future 0.803 0.645
#> Benefit 0.541 0.293
#>
#> SS loadings: 1.552
#> Proportion Var: 0.388
#>
#> Factor correlations:
#>
#> F1
#> F1 1
# Constrain all slopes to be equal with the constrain = list() input or mirt.model() syntax
# first obtain parameter index
values <- mirt(Science,1, pars = 'values')
values #note that slopes are numbered 1,5,9,13, or index with values$parnum[values$name == 'a1']
#> group item class name parnum value lbound ubound est const
#> 1 all Comfort graded a1 1 0.851 -Inf Inf TRUE none
#> 2 all Comfort graded d1 2 4.390 -Inf Inf TRUE none
#> 3 all Comfort graded d2 3 2.583 -Inf Inf TRUE none
#> 4 all Comfort graded d3 4 -1.471 -Inf Inf TRUE none
#> 5 all Work graded a1 5 0.851 -Inf Inf TRUE none
#> 6 all Work graded d1 6 2.707 -Inf Inf TRUE none
#> 7 all Work graded d2 7 0.842 -Inf Inf TRUE none
#> 8 all Work graded d3 8 -2.120 -Inf Inf TRUE none
#> 9 all Future graded a1 9 0.851 -Inf Inf TRUE none
#> 10 all Future graded d1 10 3.543 -Inf Inf TRUE none
#> 11 all Future graded d2 11 1.522 -Inf Inf TRUE none
#> 12 all Future graded d3 12 -1.357 -Inf Inf TRUE none
#> 13 all Benefit graded a1 13 0.851 -Inf Inf TRUE none
#> 14 all Benefit graded d1 14 3.166 -Inf Inf TRUE none
#> 15 all Benefit graded d2 15 0.982 -Inf Inf TRUE none
#> 16 all Benefit graded d3 16 -1.661 -Inf Inf TRUE none
#> 17 all GROUP GroupPars MEAN_1 17 0.000 -Inf Inf FALSE none
#> 18 all GROUP GroupPars COV_11 18 1.000 0 Inf FALSE none
#> nconst prior.type prior_1 prior_2
#> 1 none none NaN NaN
#> 2 none none NaN NaN
#> 3 none none NaN NaN
#> 4 none none NaN NaN
#> 5 none none NaN NaN
#> 6 none none NaN NaN
#> 7 none none NaN NaN
#> 8 none none NaN NaN
#> 9 none none NaN NaN
#> 10 none none NaN NaN
#> 11 none none NaN NaN
#> 12 none none NaN NaN
#> 13 none none NaN NaN
#> 14 none none NaN NaN
#> 15 none none NaN NaN
#> 16 none none NaN NaN
#> 17 none none NaN NaN
#> 18 none none NaN NaN
(pmod1_equalslopes <- mirt(Science, 1, constrain = list(c(1,5,9,13))))
#>
#> Call:
#> mirt(data = Science, model = 1, constrain = list(c(1, 5, 9, 13)))
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 15 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -1613.899
#> Estimated parameters: 16
#> AIC = 3253.798
#> BIC = 3305.425; SABIC = 3264.176
#> G2 (242) = 223.62, p = 0.7959
#> RMSEA = 0, CFI = NaN, TLI = NaN
coef(pmod1_equalslopes)
#> $Comfort
#> a1 d1 d2 d3
#> par 1.321 5.165 2.844 -1.587
#>
#> $Work
#> a1 d1 d2 d3
#> par 1.321 2.992 0.934 -2.319
#>
#> $Future
#> a1 d1 d2 d3
#> par 1.321 4.067 1.662 -1.488
#>
#> $Benefit
#> a1 d1 d2 d3
#> par 1.321 3.55 1.057 -1.806
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
# using mirt.model syntax, constrain all item slopes to be equal
model <- 'F = 1-4
CONSTRAIN = (1-4, a1)'
(pmod1_equalslopes <- mirt(Science, model))
#>
#> Call:
#> mirt(data = Science, model = model)
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 15 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -1613.899
#> Estimated parameters: 16
#> AIC = 3253.798
#> BIC = 3305.425; SABIC = 3264.176
#> G2 (242) = 223.62, p = 0.7959
#> RMSEA = 0, CFI = NaN, TLI = NaN
coef(pmod1_equalslopes)
#> $Comfort
#> a1 d1 d2 d3
#> par 1.321 5.165 2.844 -1.587
#>
#> $Work
#> a1 d1 d2 d3
#> par 1.321 2.992 0.934 -2.319
#>
#> $Future
#> a1 d1 d2 d3
#> par 1.321 4.067 1.662 -1.488
#>
#> $Benefit
#> a1 d1 d2 d3
#> par 1.321 3.55 1.057 -1.806
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
coef(pmod1_equalslopes)
#> $Comfort
#> a1 d1 d2 d3
#> par 1.321 5.165 2.844 -1.587
#>
#> $Work
#> a1 d1 d2 d3
#> par 1.321 2.992 0.934 -2.319
#>
#> $Future
#> a1 d1 d2 d3
#> par 1.321 4.067 1.662 -1.488
#>
#> $Benefit
#> a1 d1 d2 d3
#> par 1.321 3.55 1.057 -1.806
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
anova(pmod1_equalslopes, pmod1) #significantly worse fit with almost all criteria
#> AIC SABIC HQ BIC logLik X2 df p
#> pmod1_equalslopes 3253.798 3264.176 3274.259 3305.425 -1613.899
#> pmod1 3249.739 3262.512 3274.922 3313.279 -1608.870 10.059 3 0.018
pmod2 <- mirt(Science, 2)
summary(pmod2)
#>
#> Rotation: oblimin
#>
#> Rotated factor loadings:
#>
#> F1 F2 h2
#> Comfort 0.6016 0.0312 0.382
#> Work -0.0573 0.7971 0.592
#> Future 0.3302 0.5153 0.548
#> Benefit 0.7231 -0.0239 0.506
#>
#> Rotated SS loadings: 0.997 0.902
#>
#> Factor correlations:
#>
#> F1 F2
#> F1 1.000
#> F2 0.511 1
plot(pmod2, rotate = 'oblimin')
summary(pmod1)
#> F1 h2
#> Comfort 0.522 0.273
#> Work 0.584 0.342
#> Future 0.803 0.645
#> Benefit 0.541 0.293
#>
#> SS loadings: 1.552
#> Proportion Var: 0.388
#>
#> Factor correlations:
#>
#> F1
#> F1 1
# Constrain all slopes to be equal with the constrain = list() input or mirt.model() syntax
# first obtain parameter index
values <- mirt(Science,1, pars = 'values')
values #note that slopes are numbered 1,5,9,13, or index with values$parnum[values$name == 'a1']
#> group item class name parnum value lbound ubound est const
#> 1 all Comfort graded a1 1 0.851 -Inf Inf TRUE none
#> 2 all Comfort graded d1 2 4.390 -Inf Inf TRUE none
#> 3 all Comfort graded d2 3 2.583 -Inf Inf TRUE none
#> 4 all Comfort graded d3 4 -1.471 -Inf Inf TRUE none
#> 5 all Work graded a1 5 0.851 -Inf Inf TRUE none
#> 6 all Work graded d1 6 2.707 -Inf Inf TRUE none
#> 7 all Work graded d2 7 0.842 -Inf Inf TRUE none
#> 8 all Work graded d3 8 -2.120 -Inf Inf TRUE none
#> 9 all Future graded a1 9 0.851 -Inf Inf TRUE none
#> 10 all Future graded d1 10 3.543 -Inf Inf TRUE none
#> 11 all Future graded d2 11 1.522 -Inf Inf TRUE none
#> 12 all Future graded d3 12 -1.357 -Inf Inf TRUE none
#> 13 all Benefit graded a1 13 0.851 -Inf Inf TRUE none
#> 14 all Benefit graded d1 14 3.166 -Inf Inf TRUE none
#> 15 all Benefit graded d2 15 0.982 -Inf Inf TRUE none
#> 16 all Benefit graded d3 16 -1.661 -Inf Inf TRUE none
#> 17 all GROUP GroupPars MEAN_1 17 0.000 -Inf Inf FALSE none
#> 18 all GROUP GroupPars COV_11 18 1.000 0 Inf FALSE none
#> nconst prior.type prior_1 prior_2
#> 1 none none NaN NaN
#> 2 none none NaN NaN
#> 3 none none NaN NaN
#> 4 none none NaN NaN
#> 5 none none NaN NaN
#> 6 none none NaN NaN
#> 7 none none NaN NaN
#> 8 none none NaN NaN
#> 9 none none NaN NaN
#> 10 none none NaN NaN
#> 11 none none NaN NaN
#> 12 none none NaN NaN
#> 13 none none NaN NaN
#> 14 none none NaN NaN
#> 15 none none NaN NaN
#> 16 none none NaN NaN
#> 17 none none NaN NaN
#> 18 none none NaN NaN
(pmod1_equalslopes <- mirt(Science, 1, constrain = list(c(1,5,9,13))))
#>
#> Call:
#> mirt(data = Science, model = 1, constrain = list(c(1, 5, 9, 13)))
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 15 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -1613.899
#> Estimated parameters: 16
#> AIC = 3253.798
#> BIC = 3305.425; SABIC = 3264.176
#> G2 (242) = 223.62, p = 0.7959
#> RMSEA = 0, CFI = NaN, TLI = NaN
coef(pmod1_equalslopes)
#> $Comfort
#> a1 d1 d2 d3
#> par 1.321 5.165 2.844 -1.587
#>
#> $Work
#> a1 d1 d2 d3
#> par 1.321 2.992 0.934 -2.319
#>
#> $Future
#> a1 d1 d2 d3
#> par 1.321 4.067 1.662 -1.488
#>
#> $Benefit
#> a1 d1 d2 d3
#> par 1.321 3.55 1.057 -1.806
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
# using mirt.model syntax, constrain all item slopes to be equal
model <- 'F = 1-4
CONSTRAIN = (1-4, a1)'
(pmod1_equalslopes <- mirt(Science, model))
#>
#> Call:
#> mirt(data = Science, model = model)
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 15 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -1613.899
#> Estimated parameters: 16
#> AIC = 3253.798
#> BIC = 3305.425; SABIC = 3264.176
#> G2 (242) = 223.62, p = 0.7959
#> RMSEA = 0, CFI = NaN, TLI = NaN
coef(pmod1_equalslopes)
#> $Comfort
#> a1 d1 d2 d3
#> par 1.321 5.165 2.844 -1.587
#>
#> $Work
#> a1 d1 d2 d3
#> par 1.321 2.992 0.934 -2.319
#>
#> $Future
#> a1 d1 d2 d3
#> par 1.321 4.067 1.662 -1.488
#>
#> $Benefit
#> a1 d1 d2 d3
#> par 1.321 3.55 1.057 -1.806
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
coef(pmod1_equalslopes)
#> $Comfort
#> a1 d1 d2 d3
#> par 1.321 5.165 2.844 -1.587
#>
#> $Work
#> a1 d1 d2 d3
#> par 1.321 2.992 0.934 -2.319
#>
#> $Future
#> a1 d1 d2 d3
#> par 1.321 4.067 1.662 -1.488
#>
#> $Benefit
#> a1 d1 d2 d3
#> par 1.321 3.55 1.057 -1.806
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
anova(pmod1_equalslopes, pmod1) #significantly worse fit with almost all criteria
#> AIC SABIC HQ BIC logLik X2 df p
#> pmod1_equalslopes 3253.798 3264.176 3274.259 3305.425 -1613.899
#> pmod1 3249.739 3262.512 3274.922 3313.279 -1608.870 10.059 3 0.018
pmod2 <- mirt(Science, 2)
summary(pmod2)
#>
#> Rotation: oblimin
#>
#> Rotated factor loadings:
#>
#> F1 F2 h2
#> Comfort 0.6016 0.0312 0.382
#> Work -0.0573 0.7971 0.592
#> Future 0.3302 0.5153 0.548
#> Benefit 0.7231 -0.0239 0.506
#>
#> Rotated SS loadings: 0.997 0.902
#>
#> Factor correlations:
#>
#> F1 F2
#> F1 1.000
#> F2 0.511 1
plot(pmod2, rotate = 'oblimin')
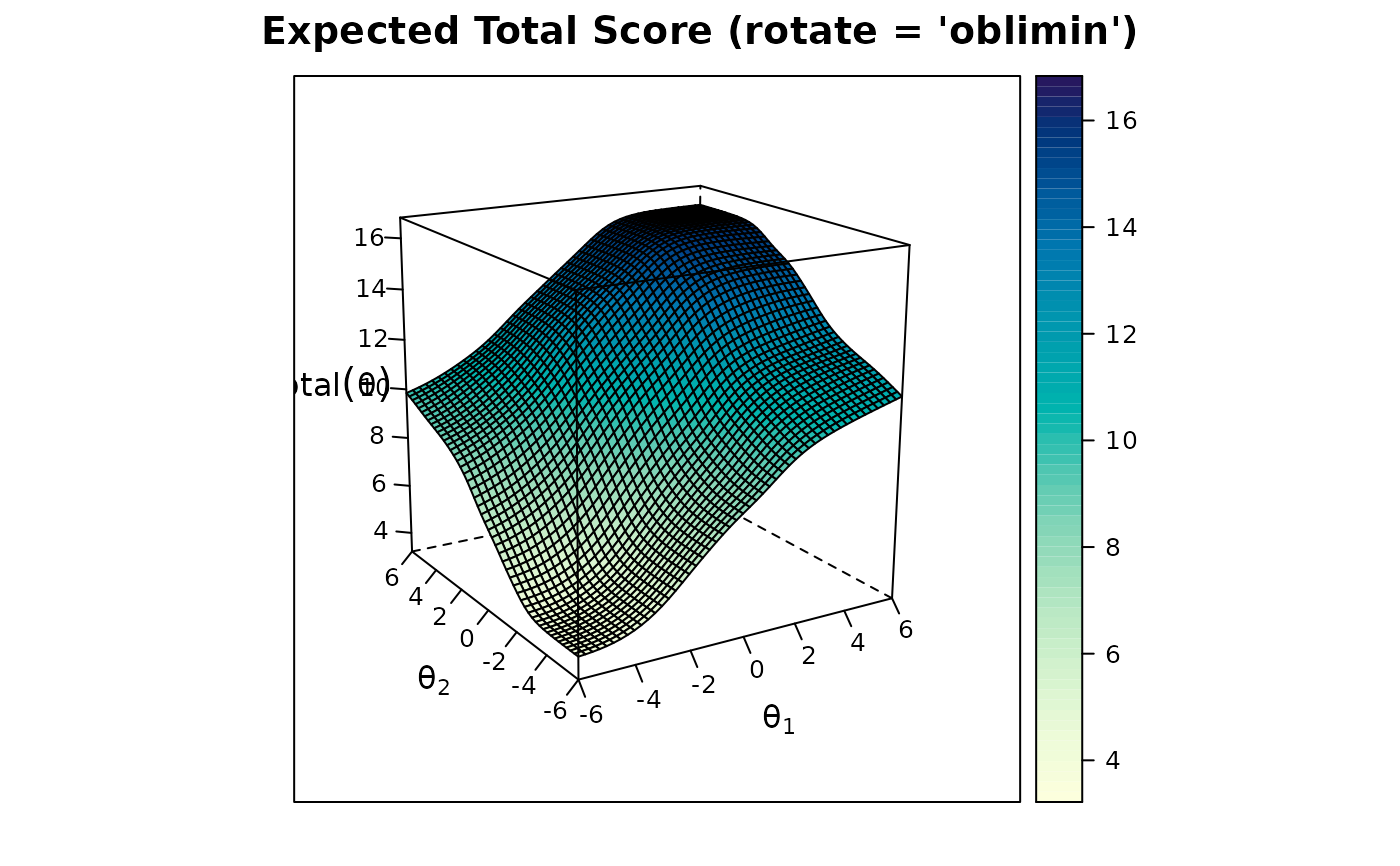 itemplot(pmod2, 1, rotate = 'oblimin')
itemplot(pmod2, 1, rotate = 'oblimin')
 anova(pmod1, pmod2)
#> AIC SABIC HQ BIC logLik X2 df p
#> pmod1 3249.739 3262.512 3274.922 3313.279 -1608.870
#> pmod2 3241.938 3257.106 3271.843 3317.392 -1601.969 13.801 3 0.003
# unidimensional fit with a generalized partial credit and nominal model
(gpcmod <- mirt(Science, 1, 'gpcm'))
#>
#> Call:
#> mirt(data = Science, model = 1, itemtype = "gpcm")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 50 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -1612.683
#> Estimated parameters: 16
#> AIC = 3257.366
#> BIC = 3320.906; SABIC = 3270.139
#> G2 (239) = 221.19, p = 0.7896
#> RMSEA = 0, CFI = NaN, TLI = NaN
coef(gpcmod)
#> $Comfort
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 0.865 0 1 2 3 0 2.831 5.324 3.998
#>
#> $Work
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 0.841 0 1 2 3 0 1.711 2.578 0.848
#>
#> $Future
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 2.204 0 1 2 3 0 4.601 6.759 4.918
#>
#> $Benefit
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 0.724 0 1 2 3 0 2.099 2.899 1.721
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
# for the nominal model the lowest and highest categories are assumed to be the
# theoretically lowest and highest categories that related to the latent trait(s)
(nomod <- mirt(Science, 1, 'nominal'))
#>
#> Call:
#> mirt(data = Science, model = 1, itemtype = "nominal")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 71 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -1608.455
#> Estimated parameters: 24
#> AIC = 3264.91
#> BIC = 3360.22; SABIC = 3284.069
#> G2 (231) = 212.73, p = 0.8002
#> RMSEA = 0, CFI = NaN, TLI = NaN
coef(nomod) #ordering of ak values suggest that the items are indeed ordinal
#> $Comfort
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 1.008 0 1.541 1.999 3 0 3.639 5.905 4.533
#>
#> $Work
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 0.841 0 0.689 1.5 3 0 1.464 2.326 0.325
#>
#> $Future
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 2.041 0 0.762 1.861 3 0 3.668 5.867 3.949
#>
#> $Benefit
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 0.779 0 1.036 1.742 3 0 2.144 2.911 1.621
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
anova(gpcmod, nomod)
#> AIC SABIC HQ BIC logLik X2 df p
#> gpcmod 3257.366 3270.139 3282.549 3320.906 -1612.683
#> nomod 3264.910 3284.069 3302.684 3360.220 -1608.455 8.456 8 0.39
itemplot(nomod, 3)
anova(pmod1, pmod2)
#> AIC SABIC HQ BIC logLik X2 df p
#> pmod1 3249.739 3262.512 3274.922 3313.279 -1608.870
#> pmod2 3241.938 3257.106 3271.843 3317.392 -1601.969 13.801 3 0.003
# unidimensional fit with a generalized partial credit and nominal model
(gpcmod <- mirt(Science, 1, 'gpcm'))
#>
#> Call:
#> mirt(data = Science, model = 1, itemtype = "gpcm")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 50 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -1612.683
#> Estimated parameters: 16
#> AIC = 3257.366
#> BIC = 3320.906; SABIC = 3270.139
#> G2 (239) = 221.19, p = 0.7896
#> RMSEA = 0, CFI = NaN, TLI = NaN
coef(gpcmod)
#> $Comfort
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 0.865 0 1 2 3 0 2.831 5.324 3.998
#>
#> $Work
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 0.841 0 1 2 3 0 1.711 2.578 0.848
#>
#> $Future
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 2.204 0 1 2 3 0 4.601 6.759 4.918
#>
#> $Benefit
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 0.724 0 1 2 3 0 2.099 2.899 1.721
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
# for the nominal model the lowest and highest categories are assumed to be the
# theoretically lowest and highest categories that related to the latent trait(s)
(nomod <- mirt(Science, 1, 'nominal'))
#>
#> Call:
#> mirt(data = Science, model = 1, itemtype = "nominal")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 71 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -1608.455
#> Estimated parameters: 24
#> AIC = 3264.91
#> BIC = 3360.22; SABIC = 3284.069
#> G2 (231) = 212.73, p = 0.8002
#> RMSEA = 0, CFI = NaN, TLI = NaN
coef(nomod) #ordering of ak values suggest that the items are indeed ordinal
#> $Comfort
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 1.008 0 1.541 1.999 3 0 3.639 5.905 4.533
#>
#> $Work
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 0.841 0 0.689 1.5 3 0 1.464 2.326 0.325
#>
#> $Future
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 2.041 0 0.762 1.861 3 0 3.668 5.867 3.949
#>
#> $Benefit
#> a1 ak0 ak1 ak2 ak3 d0 d1 d2 d3
#> par 0.779 0 1.036 1.742 3 0 2.144 2.911 1.621
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
anova(gpcmod, nomod)
#> AIC SABIC HQ BIC logLik X2 df p
#> gpcmod 3257.366 3270.139 3282.549 3320.906 -1612.683
#> nomod 3264.910 3284.069 3302.684 3360.220 -1608.455 8.456 8 0.39
itemplot(nomod, 3)
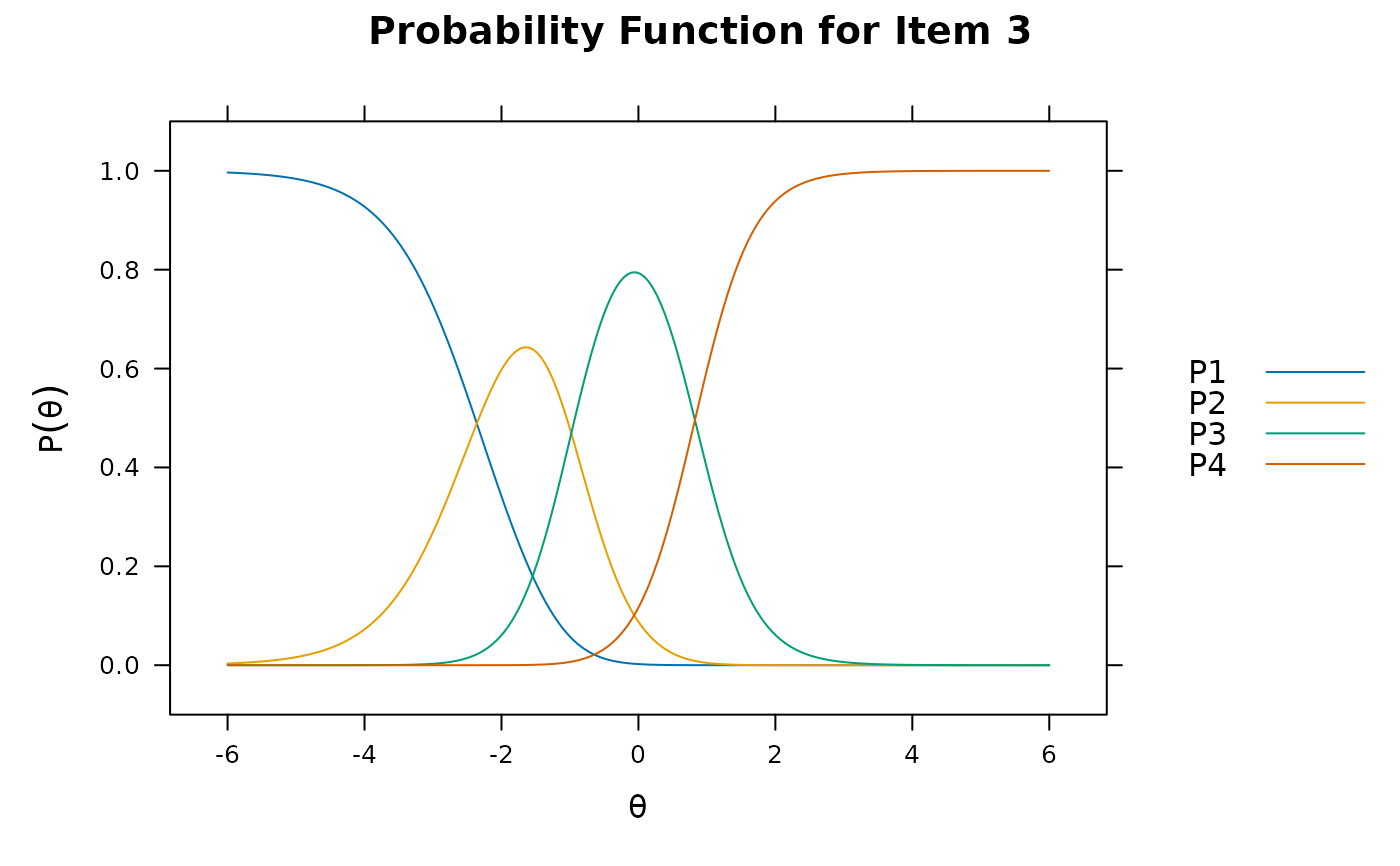 # generalized graded unfolding model
(ggum <- mirt(Science, 1, 'ggum'))
#> Warning: EM cycles terminated after 500 iterations.
#>
#> Call:
#> mirt(data = Science, model = 1, itemtype = "ggum")
#>
#> Full-information item factor analysis with 1 factor(s).
#> FAILED TO CONVERGE within 1e-04 tolerance after 500 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: nlminb
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -1624.053
#> Estimated parameters: 20
#> AIC = 3288.107
#> BIC = 3367.532; SABIC = 3304.072
#> G2 (235) = 243.93, p = 0.3309
#> RMSEA = 0.01, CFI = NaN, TLI = NaN
coef(ggum, simplify=TRUE)
#> $items
#> a1 b1 t1 t2 t3
#> Comfort 1.488 -0.485 3.191 2.635 -0.167
#> Work 1.190 0.041 2.171 1.427 -0.720
#> Future 4.165 -0.042 2.167 1.346 0.261
#> Benefit 1.227 -0.476 2.776 1.497 -0.274
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1
#>
plot(ggum)
# generalized graded unfolding model
(ggum <- mirt(Science, 1, 'ggum'))
#> Warning: EM cycles terminated after 500 iterations.
#>
#> Call:
#> mirt(data = Science, model = 1, itemtype = "ggum")
#>
#> Full-information item factor analysis with 1 factor(s).
#> FAILED TO CONVERGE within 1e-04 tolerance after 500 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: nlminb
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -1624.053
#> Estimated parameters: 20
#> AIC = 3288.107
#> BIC = 3367.532; SABIC = 3304.072
#> G2 (235) = 243.93, p = 0.3309
#> RMSEA = 0.01, CFI = NaN, TLI = NaN
coef(ggum, simplify=TRUE)
#> $items
#> a1 b1 t1 t2 t3
#> Comfort 1.488 -0.485 3.191 2.635 -0.167
#> Work 1.190 0.041 2.171 1.427 -0.720
#> Future 4.165 -0.042 2.167 1.346 0.261
#> Benefit 1.227 -0.476 2.776 1.497 -0.274
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1
#>
plot(ggum)
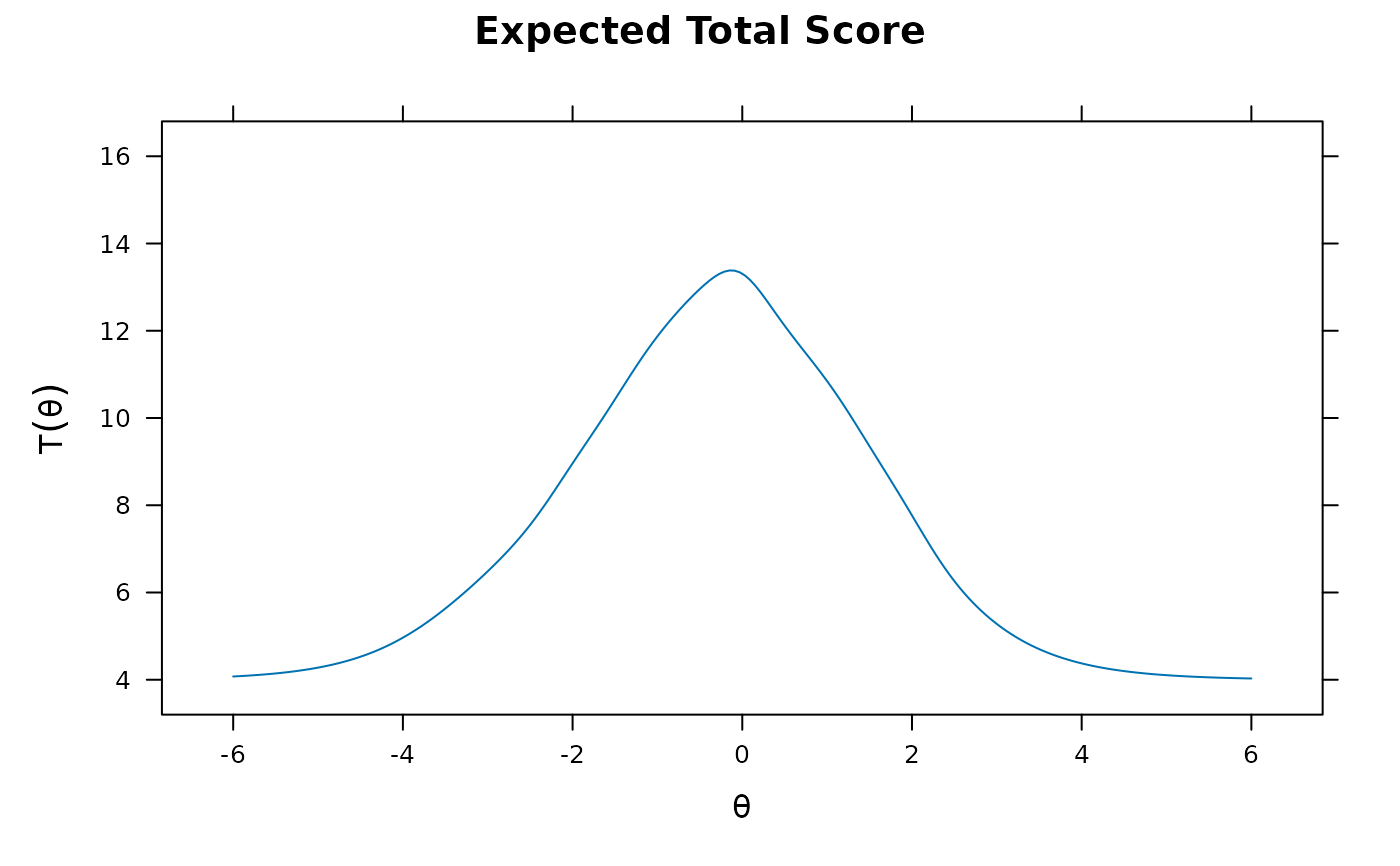 plot(ggum, type = 'trace')
plot(ggum, type = 'trace')
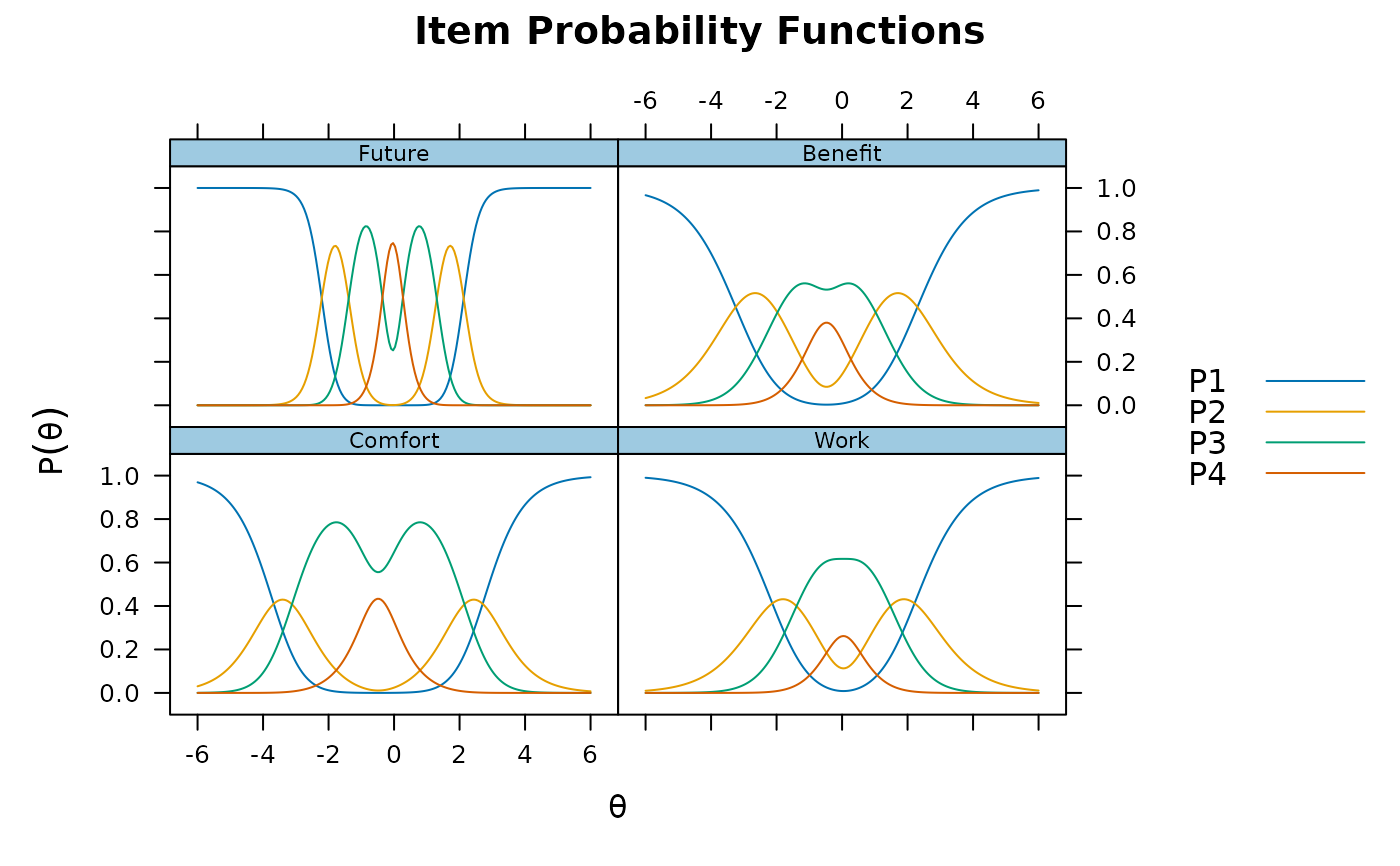 plot(ggum, type = 'itemscore')
plot(ggum, type = 'itemscore')
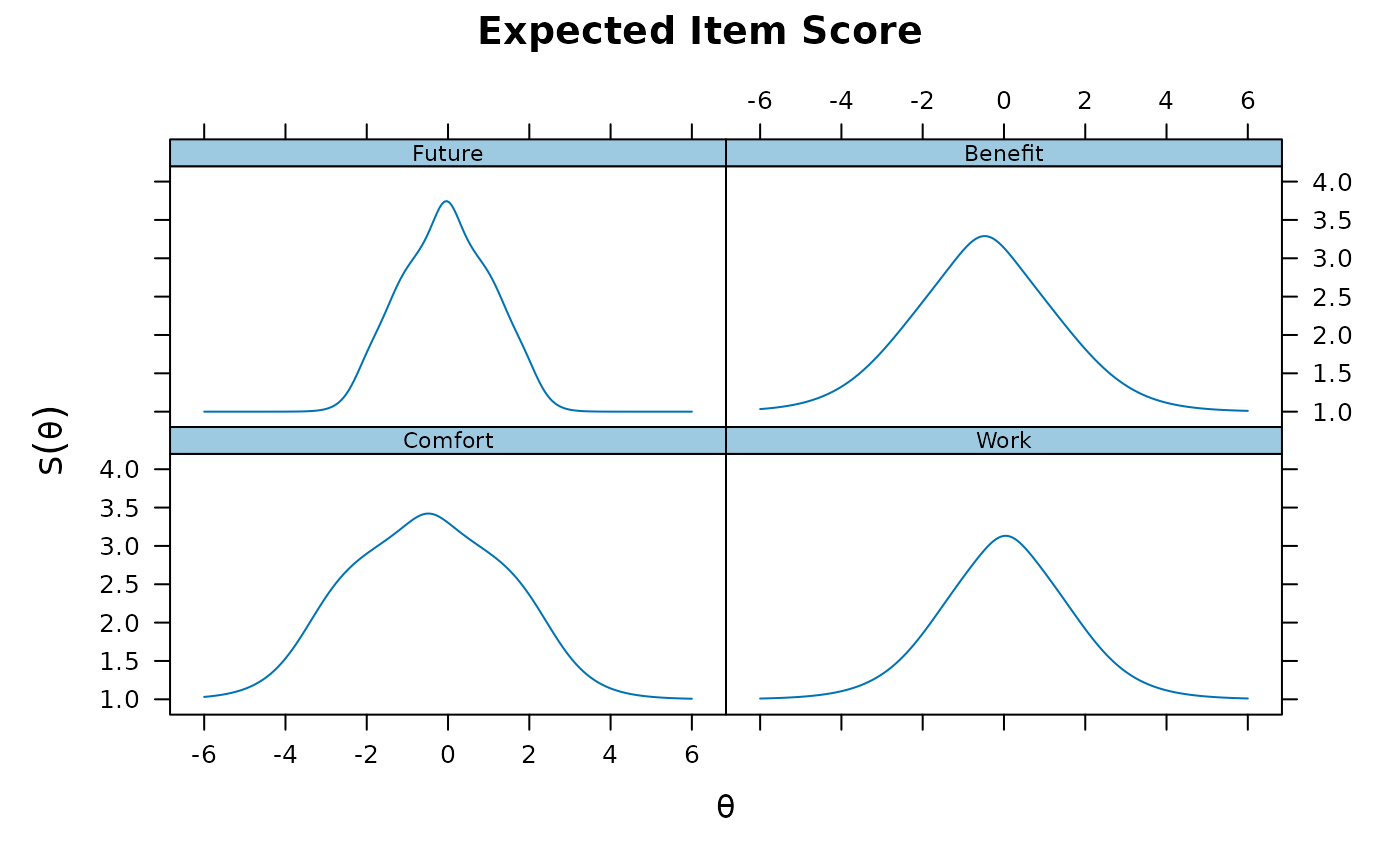 # monotonic polyomial models
(monopoly <- mirt(Science, 1, 'monopoly'))
#>
#> Call:
#> mirt(data = Science, model = 1, itemtype = "monopoly")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 50 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -1601.179
#> Estimated parameters: 24
#> AIC = 3250.358
#> BIC = 3345.668; SABIC = 3269.517
#> G2 (231) = 198.18, p = 0.9423
#> RMSEA = 0, CFI = NaN, TLI = NaN
coef(monopoly, simplify=TRUE)
#> $items
#> omega xi1 xi2 xi3 alpha1 tau2
#> Comfort -1.469 2.929 2.218 -1.469 -0.968 0.775
#> Work -0.405 1.378 0.699 -2.152 -0.494 -1.179
#> Future 0.828 4.939 2.246 -1.909 0.015 -8.461
#> Benefit -1.747 1.887 0.618 -1.388 -1.467 0.746
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1
#>
plot(monopoly)
# monotonic polyomial models
(monopoly <- mirt(Science, 1, 'monopoly'))
#>
#> Call:
#> mirt(data = Science, model = 1, itemtype = "monopoly")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 50 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -1601.179
#> Estimated parameters: 24
#> AIC = 3250.358
#> BIC = 3345.668; SABIC = 3269.517
#> G2 (231) = 198.18, p = 0.9423
#> RMSEA = 0, CFI = NaN, TLI = NaN
coef(monopoly, simplify=TRUE)
#> $items
#> omega xi1 xi2 xi3 alpha1 tau2
#> Comfort -1.469 2.929 2.218 -1.469 -0.968 0.775
#> Work -0.405 1.378 0.699 -2.152 -0.494 -1.179
#> Future 0.828 4.939 2.246 -1.909 0.015 -8.461
#> Benefit -1.747 1.887 0.618 -1.388 -1.467 0.746
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1
#>
plot(monopoly)
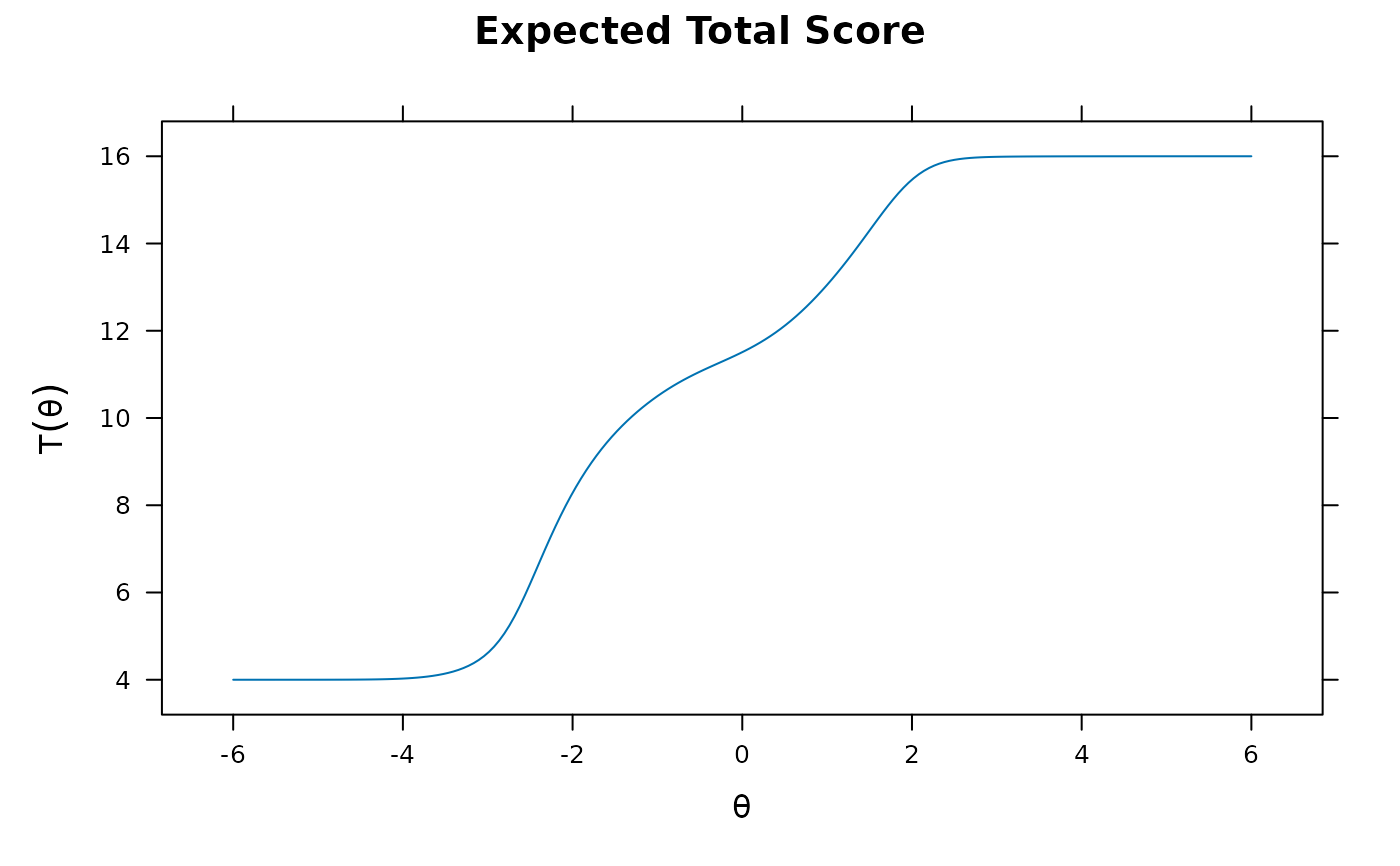 plot(monopoly, type = 'trace')
plot(monopoly, type = 'trace')
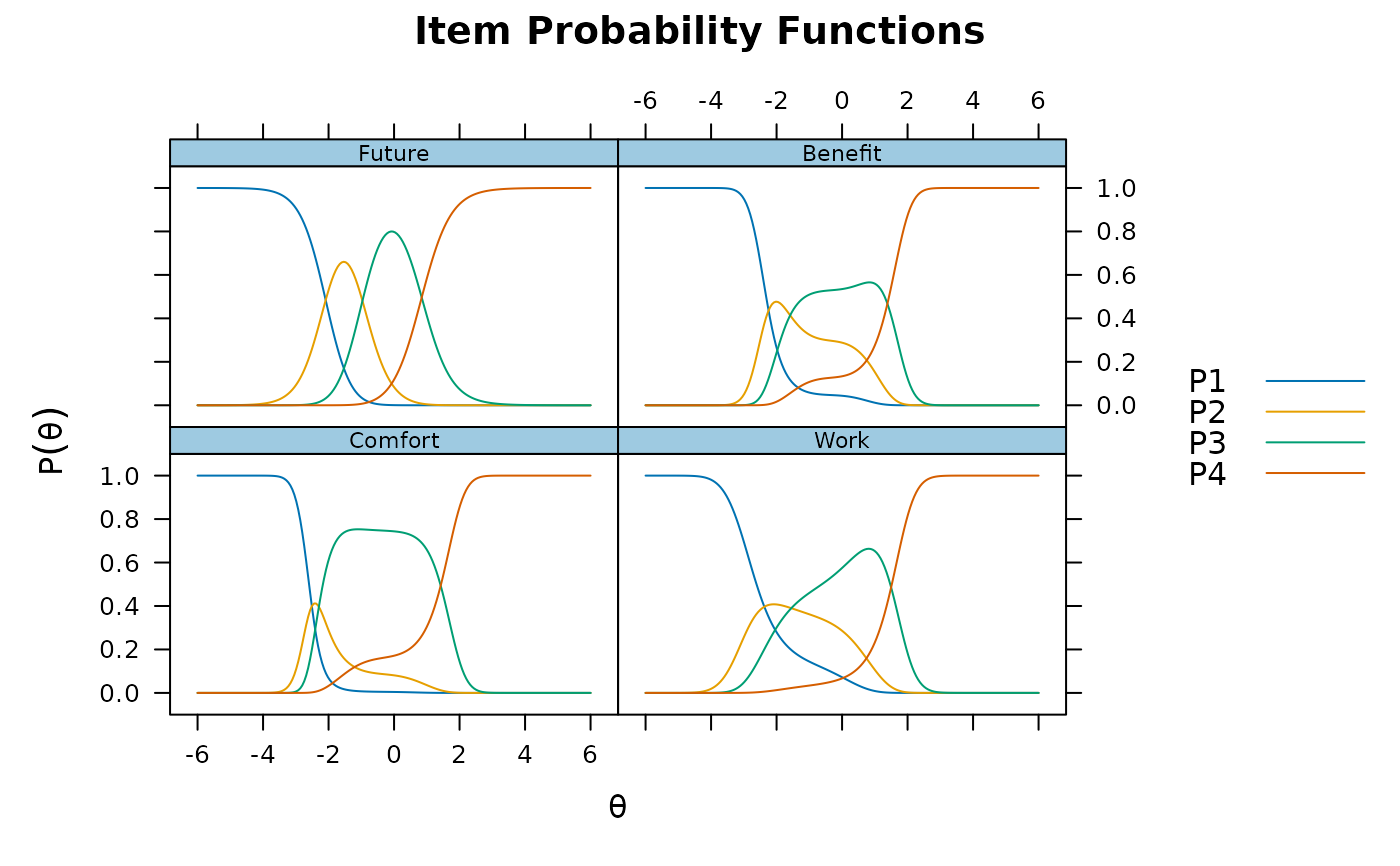 plot(monopoly, type = 'itemscore')
plot(monopoly, type = 'itemscore')
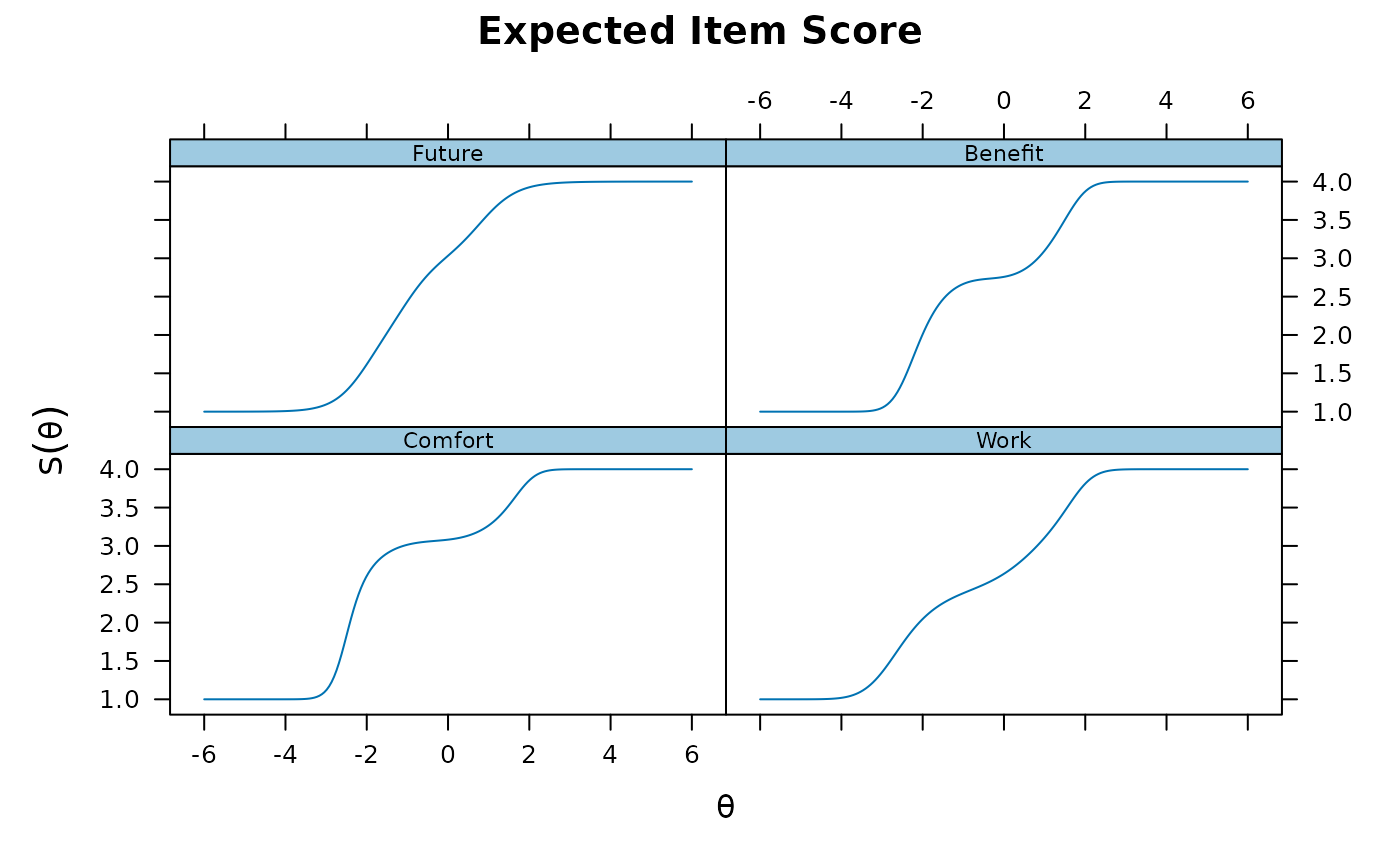 # unipolar IRT model
unimod <- mirt(Science, itemtype = 'ULL')
coef(unimod, simplify=TRUE)
#> $items
#> eta1 log_lambda1 log_lambda2 log_lambda3
#> Comfort 1.175 4.775 2.299 -1.709
#> Work 1.618 2.533 0.554 -2.737
#> Future 2.799 4.029 1.524 -2.593
#> Benefit 1.319 3.020 0.681 -1.995
#>
#> $GroupPars
#> meanlog sdlog
#> par 0 1
#>
plot(unimod)
# unipolar IRT model
unimod <- mirt(Science, itemtype = 'ULL')
coef(unimod, simplify=TRUE)
#> $items
#> eta1 log_lambda1 log_lambda2 log_lambda3
#> Comfort 1.175 4.775 2.299 -1.709
#> Work 1.618 2.533 0.554 -2.737
#> Future 2.799 4.029 1.524 -2.593
#> Benefit 1.319 3.020 0.681 -1.995
#>
#> $GroupPars
#> meanlog sdlog
#> par 0 1
#>
plot(unimod)
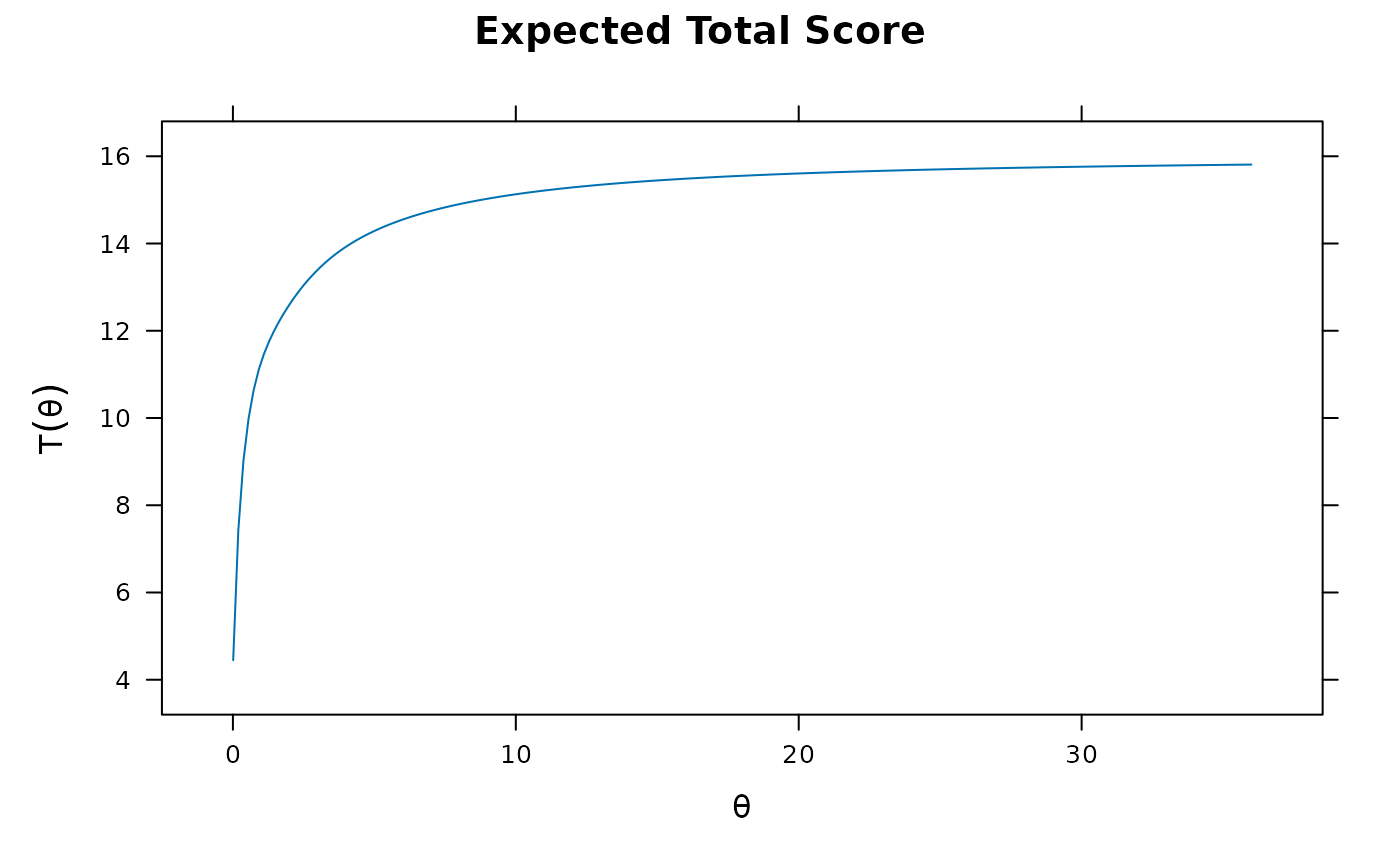 plot(unimod, type = 'trace')
plot(unimod, type = 'trace')
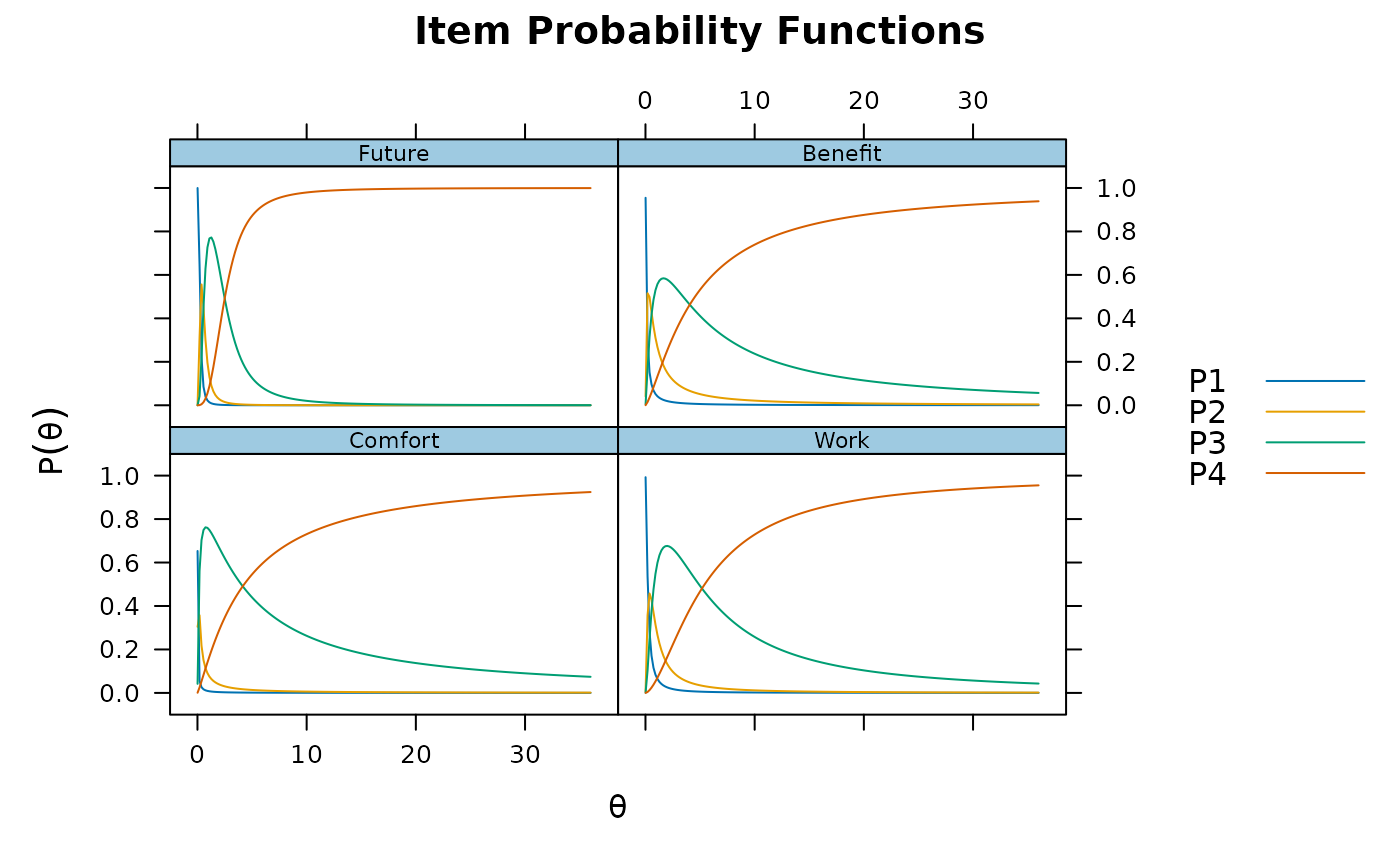 itemplot(unimod, 1)
itemplot(unimod, 1)
 # following use the correct log-normal density for latent trait
itemfit(unimod)
#> item S_X2 df.S_X2 RMSEA.S_X2 p.S_X2
#> 1 Comfort 5.662 6 0.000 0.462
#> 2 Work 10.135 8 0.026 0.256
#> 3 Future 19.460 8 0.061 0.013
#> 4 Benefit 12.104 11 0.016 0.356
M2(unimod, type = 'C2')
#> M2 df p RMSEA RMSEA_5 RMSEA_95 SRMSR
#> stats 18.69399 2 8.722705e-05 0.1461089 0.09025438 0.2096054 0.07864884
#> TLI CFI
#> stats 0.7377197 0.9125732
fs <- fscores(unimod)
hist(fs, 20)
# following use the correct log-normal density for latent trait
itemfit(unimod)
#> item S_X2 df.S_X2 RMSEA.S_X2 p.S_X2
#> 1 Comfort 5.662 6 0.000 0.462
#> 2 Work 10.135 8 0.026 0.256
#> 3 Future 19.460 8 0.061 0.013
#> 4 Benefit 12.104 11 0.016 0.356
M2(unimod, type = 'C2')
#> M2 df p RMSEA RMSEA_5 RMSEA_95 SRMSR
#> stats 18.69399 2 8.722705e-05 0.1461089 0.09025438 0.2096054 0.07864884
#> TLI CFI
#> stats 0.7377197 0.9125732
fs <- fscores(unimod)
hist(fs, 20)
 fscores(unimod, method = 'EAPsum', full.scores = FALSE)
#> df X2 p.X2 SEM.alpha rxx.alpha rxx_F1
#> stats 10 33.917 0 1.305 0.658 0.531
#>
#> Sum.Scores F1 SE_F1 observed expected std.res
#> 4 4 0.138 0.153 2 0.127 5.251
#> 5 5 0.304 0.088 1 0.766 0.268
#> 6 6 0.328 0.084 2 4.337 1.122
#> 7 7 0.352 0.126 1 13.904 3.461
#> 8 8 0.407 0.199 11 27.736 3.178
#> 9 9 0.530 0.305 32 40.626 1.353
#> 10 10 0.748 0.440 58 52.276 0.792
#> 11 11 1.053 0.605 70 63.511 0.814
#> 12 12 1.478 0.845 91 68.881 2.665
#> 13 13 2.164 1.282 56 54.419 0.214
#> 14 14 3.299 2.001 36 36.185 0.031
#> 15 15 5.109 3.236 20 20.819 0.179
#> 16 16 8.222 5.298 12 8.414 1.236
## example applying survey weights.
# weight the first half of the cases to be more representative of population
survey.weights <- c(rep(2, nrow(Science)/2), rep(1, nrow(Science)/2))
survey.weights <- survey.weights/sum(survey.weights) * nrow(Science)
unweighted <- mirt(Science, 1)
weighted <- mirt(Science, 1, survey.weights=survey.weights)
###########
# empirical dimensionality testing that includes 'guessing'
data(SAT12)
data <- key2binary(SAT12,
key = c(1,4,5,2,3,1,2,1,3,1,2,4,2,1,5,3,4,4,1,4,3,3,4,1,3,5,1,3,1,5,4,5))
itemstats(data)
#> $overall
#> N mean_total.score sd_total.score ave.r sd.r alpha SEM.alpha
#> 600 18.202 5.054 0.108 0.075 0.798 2.272
#>
#> $itemstats
#> N mean sd total.r total.r_if_rm alpha_if_rm
#> Item.1 600 0.283 0.451 0.380 0.300 0.793
#> Item.2 600 0.568 0.496 0.539 0.464 0.785
#> Item.3 600 0.280 0.449 0.446 0.371 0.789
#> Item.4 600 0.378 0.485 0.325 0.235 0.796
#> Item.5 600 0.620 0.486 0.424 0.340 0.791
#> Item.6 600 0.160 0.367 0.414 0.351 0.791
#> Item.7 600 0.760 0.427 0.366 0.289 0.793
#> Item.8 600 0.202 0.402 0.307 0.233 0.795
#> Item.9 600 0.885 0.319 0.189 0.127 0.798
#> Item.10 600 0.422 0.494 0.465 0.383 0.789
#> Item.11 600 0.983 0.128 0.181 0.156 0.797
#> Item.12 600 0.415 0.493 0.173 0.076 0.803
#> Item.13 600 0.662 0.474 0.438 0.358 0.790
#> Item.14 600 0.723 0.448 0.411 0.333 0.791
#> Item.15 600 0.817 0.387 0.393 0.325 0.792
#> Item.16 600 0.413 0.493 0.367 0.278 0.794
#> Item.17 600 0.963 0.188 0.238 0.202 0.796
#> Item.18 600 0.352 0.478 0.576 0.508 0.783
#> Item.19 600 0.548 0.498 0.401 0.314 0.792
#> Item.20 600 0.873 0.333 0.376 0.318 0.792
#> Item.21 600 0.915 0.279 0.190 0.136 0.798
#> Item.22 600 0.935 0.247 0.284 0.238 0.795
#> Item.23 600 0.313 0.464 0.338 0.253 0.795
#> Item.24 600 0.728 0.445 0.422 0.346 0.791
#> Item.25 600 0.375 0.485 0.383 0.297 0.793
#> Item.26 600 0.460 0.499 0.562 0.489 0.783
#> Item.27 600 0.862 0.346 0.425 0.367 0.791
#> Item.28 600 0.530 0.500 0.465 0.383 0.789
#> Item.29 600 0.340 0.474 0.407 0.324 0.791
#> Item.30 600 0.440 0.497 0.255 0.159 0.799
#> Item.31 600 0.833 0.373 0.479 0.419 0.788
#> Item.32 600 0.162 0.368 0.110 0.037 0.802
#>
#> $proportions
#> 0 1
#> Item.1 0.717 0.283
#> Item.2 0.432 0.568
#> Item.3 0.720 0.280
#> Item.4 0.622 0.378
#> Item.5 0.380 0.620
#> Item.6 0.840 0.160
#> Item.7 0.240 0.760
#> Item.8 0.798 0.202
#> Item.9 0.115 0.885
#> Item.10 0.578 0.422
#> Item.11 0.017 0.983
#> Item.12 0.585 0.415
#> Item.13 0.338 0.662
#> Item.14 0.277 0.723
#> Item.15 0.183 0.817
#> Item.16 0.587 0.413
#> Item.17 0.037 0.963
#> Item.18 0.648 0.352
#> Item.19 0.452 0.548
#> Item.20 0.127 0.873
#> Item.21 0.085 0.915
#> Item.22 0.065 0.935
#> Item.23 0.687 0.313
#> Item.24 0.272 0.728
#> Item.25 0.625 0.375
#> Item.26 0.540 0.460
#> Item.27 0.138 0.862
#> Item.28 0.470 0.530
#> Item.29 0.660 0.340
#> Item.30 0.560 0.440
#> Item.31 0.167 0.833
#> Item.32 0.838 0.162
#>
mod1 <- mirt(data, 1)
extract.mirt(mod1, 'time') #time elapsed for each estimation component
#> TOTAL: Data Estep Mstep SE Post
#> 0.355 0.049 0.116 0.177 0.000 0.001
# optionally use Newton-Raphson for (generally) faster convergence in the M-step's
mod1 <- mirt(data, 1, optimizer = 'NR')
extract.mirt(mod1, 'time')
#> TOTAL: Data Estep Mstep SE Post
#> 0.228 0.048 0.080 0.084 0.000 0.001
mod2 <- mirt(data, 2, optimizer = 'NR')
#> Warning: EM cycles terminated after 500 iterations.
# difficulty converging with reduced quadpts, reduce TOL
mod3 <- mirt(data, 3, TOL = .001, optimizer = 'NR')
anova(mod1,mod2)
#> AIC SABIC HQ BIC logLik X2 df p
#> mod1 19105.91 19184.13 19215.46 19387.31 -9488.955
#> mod2 19073.92 19190.03 19236.53 19491.63 -9441.963 93.985 31 0
anova(mod2, mod3) #negative AIC, 2 factors probably best
#> AIC SABIC HQ BIC logLik X2 df p
#> mod2 19073.92 19190.03 19236.53 19491.63 -9441.963
#> mod3 19080.18 19232.96 19294.13 19629.80 -9415.090 53.744 30 0.005
# same as above, but using the QMCEM method for generally better accuracy in mod3
mod3 <- mirt(data, 3, method = 'QMCEM', TOL = .001, optimizer = 'NR')
anova(mod2, mod3)
#> AIC SABIC HQ BIC logLik X2 df p
#> mod2 19073.92 19190.03 19236.53 19491.63 -9441.963
#> mod3 19081.58 19234.36 19295.54 19631.20 -9415.792 52.342 30 0.007
# with fixed guessing parameters
mod1g <- mirt(data, 1, guess = .1)
coef(mod1g)
#> $Item.1
#> a1 d g u
#> par 1.211 -1.737 0.1 1
#>
#> $Item.2
#> a1 d g u
#> par 1.78 0.147 0.1 1
#>
#> $Item.3
#> a1 d g u
#> par 1.91 -2.2 0.1 1
#>
#> $Item.4
#> a1 d g u
#> par 0.833 -0.944 0.1 1
#>
#> $Item.5
#> a1 d g u
#> par 1.089 0.399 0.1 1
#>
#> $Item.6
#> a1 d g u
#> par 3.265 -5.212 0.1 1
#>
#> $Item.7
#> a1 d g u
#> par 1.02 1.224 0.1 1
#>
#> $Item.8
#> a1 d g u
#> par 1.639 -2.977 0.1 1
#>
#> $Item.9
#> a1 d g u
#> par 0.49 2.007 0.1 1
#>
#> $Item.10
#> a1 d g u
#> par 1.257 -0.756 0.1 1
#>
#> $Item.11
#> a1 d g u
#> par 1.68 5.18 0.1 1
#>
#> $Item.12
#> a1 d g u
#> par 0.191 -0.625 0.1 1
#>
#> $Item.13
#> a1 d g u
#> par 1.147 0.654 0.1 1
#>
#> $Item.14
#> a1 d g u
#> par 1.099 1.008 0.1 1
#>
#> $Item.15
#> a1 d g u
#> par 1.337 1.79 0.1 1
#>
#> $Item.16
#> a1 d g u
#> par 0.923 -0.744 0.1 1
#>
#> $Item.17
#> a1 d g u
#> par 1.519 4.077 0.1 1
#>
#> $Item.18
#> a1 d g u
#> par 2.585 -1.749 0.1 1
#>
#> $Item.19
#> a1 d g u
#> par 0.91 -0.002 0.1 1
#>
#> $Item.20
#> a1 d g u
#> par 1.485 2.438 0.1 1
#>
#> $Item.21
#> a1 d g u
#> par 0.616 2.407 0.1 1
#>
#> $Item.22
#> a1 d g u
#> par 1.429 3.291 0.1 1
#>
#> $Item.23
#> a1 d g u
#> par 0.96 -1.393 0.1 1
#>
#> $Item.24
#> a1 d g u
#> par 1.282 1.099 0.1 1
#>
#> $Item.25
#> a1 d g u
#> par 1.028 -1 0.1 1
#>
#> $Item.26
#> a1 d g u
#> par 2.059 -0.658 0.1 1
#>
#> $Item.27
#> a1 d g u
#> par 1.839 2.564 0.1 1
#>
#> $Item.28
#> a1 d g u
#> par 1.222 -0.095 0.1 1
#>
#> $Item.29
#> a1 d g u
#> par 1.281 -1.357 0.1 1
#>
#> $Item.30
#> a1 d g u
#> par 0.444 -0.521 0.1 1
#>
#> $Item.31
#> a1 d g u
#> par 2.476 2.697 0.1 1
#>
#> $Item.32
#> a1 d g u
#> par 0.461 -2.742 0.1 1
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
###########
# graded rating scale example
# make some data
set.seed(1234)
a <- matrix(rep(1, 10))
d <- matrix(c(1,0.5,-.5,-1), 10, 4, byrow = TRUE)
c <- seq(-1, 1, length.out=10)
data <- simdata(a, d + c, 2000, itemtype = rep('graded',10))
itemstats(data)
#> $overall
#> N mean_total.score sd_total.score ave.r sd.r alpha SEM.alpha
#> 2000 20.196 8.33 0.203 0.027 0.719 4.419
#>
#> $itemstats
#> N mean sd total.r total.r_if_rm alpha_if_rm
#> Item_1 2000 1.284 1.510 0.512 0.359 0.700
#> Item_2 2000 1.427 1.544 0.529 0.375 0.697
#> Item_3 2000 1.592 1.584 0.545 0.389 0.695
#> Item_4 2000 1.774 1.586 0.538 0.381 0.696
#> Item_5 2000 1.910 1.607 0.539 0.380 0.696
#> Item_6 2000 2.124 1.606 0.533 0.373 0.697
#> Item_7 2000 2.284 1.598 0.520 0.359 0.700
#> Item_8 2000 2.420 1.583 0.578 0.430 0.688
#> Item_9 2000 2.606 1.543 0.530 0.377 0.697
#> Item_10 2000 2.776 1.491 0.495 0.342 0.702
#>
#> $proportions
#> 0 1 2 3 4
#> Item_1 0.500 0.096 0.182 0.065 0.158
#> Item_2 0.450 0.108 0.197 0.059 0.187
#> Item_3 0.407 0.108 0.182 0.092 0.212
#> Item_4 0.346 0.111 0.212 0.085 0.246
#> Item_5 0.319 0.102 0.211 0.086 0.281
#> Item_6 0.269 0.097 0.205 0.099 0.330
#> Item_7 0.244 0.073 0.211 0.101 0.372
#> Item_8 0.216 0.074 0.195 0.106 0.410
#> Item_9 0.175 0.072 0.196 0.083 0.473
#> Item_10 0.150 0.059 0.174 0.102 0.516
#>
mod1 <- mirt(data, 1)
mod2 <- mirt(data, 1, itemtype = 'grsm')
coef(mod2)
#> $Item_1
#> a1 b1 b2 b3 b4 c
#> par 0.959 0.001 -0.507 -1.541 -2.032 0
#>
#> $Item_2
#> a1 b1 b2 b3 b4 c
#> par 0.987 0.001 -0.507 -1.541 -2.032 0.235
#>
#> $Item_3
#> a1 b1 b2 b3 b4 c
#> par 0.994 0.001 -0.507 -1.541 -2.032 0.457
#>
#> $Item_4
#> a1 b1 b2 b3 b4 c
#> par 1.027 0.001 -0.507 -1.541 -2.032 0.728
#>
#> $Item_5
#> a1 b1 b2 b3 b4 c
#> par 0.995 0.001 -0.507 -1.541 -2.032 0.895
#>
#> $Item_6
#> a1 b1 b2 b3 b4 c
#> par 0.987 0.001 -0.507 -1.541 -2.032 1.179
#>
#> $Item_7
#> a1 b1 b2 b3 b4 c
#> par 0.957 0.001 -0.507 -1.541 -2.032 1.404
#>
#> $Item_8
#> a1 b1 b2 b3 b4 c
#> par 1.04 0.001 -0.507 -1.541 -2.032 1.578
#>
#> $Item_9
#> a1 b1 b2 b3 b4 c
#> par 0.964 0.001 -0.507 -1.541 -2.032 1.878
#>
#> $Item_10
#> a1 b1 b2 b3 b4 c
#> par 0.947 0.001 -0.507 -1.541 -2.032 2.136
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
anova(mod2, mod1) #not sig, mod2 should be preferred
#> AIC SABIC HQ BIC logLik X2 df p
#> mod2 55239.72 55295.47 55287.03 55368.55 -27596.86
#> mod1 55252.05 55373.25 55354.88 55532.10 -27576.03 41.671 27 0.035
itemplot(mod2, 1)
fscores(unimod, method = 'EAPsum', full.scores = FALSE)
#> df X2 p.X2 SEM.alpha rxx.alpha rxx_F1
#> stats 10 33.917 0 1.305 0.658 0.531
#>
#> Sum.Scores F1 SE_F1 observed expected std.res
#> 4 4 0.138 0.153 2 0.127 5.251
#> 5 5 0.304 0.088 1 0.766 0.268
#> 6 6 0.328 0.084 2 4.337 1.122
#> 7 7 0.352 0.126 1 13.904 3.461
#> 8 8 0.407 0.199 11 27.736 3.178
#> 9 9 0.530 0.305 32 40.626 1.353
#> 10 10 0.748 0.440 58 52.276 0.792
#> 11 11 1.053 0.605 70 63.511 0.814
#> 12 12 1.478 0.845 91 68.881 2.665
#> 13 13 2.164 1.282 56 54.419 0.214
#> 14 14 3.299 2.001 36 36.185 0.031
#> 15 15 5.109 3.236 20 20.819 0.179
#> 16 16 8.222 5.298 12 8.414 1.236
## example applying survey weights.
# weight the first half of the cases to be more representative of population
survey.weights <- c(rep(2, nrow(Science)/2), rep(1, nrow(Science)/2))
survey.weights <- survey.weights/sum(survey.weights) * nrow(Science)
unweighted <- mirt(Science, 1)
weighted <- mirt(Science, 1, survey.weights=survey.weights)
###########
# empirical dimensionality testing that includes 'guessing'
data(SAT12)
data <- key2binary(SAT12,
key = c(1,4,5,2,3,1,2,1,3,1,2,4,2,1,5,3,4,4,1,4,3,3,4,1,3,5,1,3,1,5,4,5))
itemstats(data)
#> $overall
#> N mean_total.score sd_total.score ave.r sd.r alpha SEM.alpha
#> 600 18.202 5.054 0.108 0.075 0.798 2.272
#>
#> $itemstats
#> N mean sd total.r total.r_if_rm alpha_if_rm
#> Item.1 600 0.283 0.451 0.380 0.300 0.793
#> Item.2 600 0.568 0.496 0.539 0.464 0.785
#> Item.3 600 0.280 0.449 0.446 0.371 0.789
#> Item.4 600 0.378 0.485 0.325 0.235 0.796
#> Item.5 600 0.620 0.486 0.424 0.340 0.791
#> Item.6 600 0.160 0.367 0.414 0.351 0.791
#> Item.7 600 0.760 0.427 0.366 0.289 0.793
#> Item.8 600 0.202 0.402 0.307 0.233 0.795
#> Item.9 600 0.885 0.319 0.189 0.127 0.798
#> Item.10 600 0.422 0.494 0.465 0.383 0.789
#> Item.11 600 0.983 0.128 0.181 0.156 0.797
#> Item.12 600 0.415 0.493 0.173 0.076 0.803
#> Item.13 600 0.662 0.474 0.438 0.358 0.790
#> Item.14 600 0.723 0.448 0.411 0.333 0.791
#> Item.15 600 0.817 0.387 0.393 0.325 0.792
#> Item.16 600 0.413 0.493 0.367 0.278 0.794
#> Item.17 600 0.963 0.188 0.238 0.202 0.796
#> Item.18 600 0.352 0.478 0.576 0.508 0.783
#> Item.19 600 0.548 0.498 0.401 0.314 0.792
#> Item.20 600 0.873 0.333 0.376 0.318 0.792
#> Item.21 600 0.915 0.279 0.190 0.136 0.798
#> Item.22 600 0.935 0.247 0.284 0.238 0.795
#> Item.23 600 0.313 0.464 0.338 0.253 0.795
#> Item.24 600 0.728 0.445 0.422 0.346 0.791
#> Item.25 600 0.375 0.485 0.383 0.297 0.793
#> Item.26 600 0.460 0.499 0.562 0.489 0.783
#> Item.27 600 0.862 0.346 0.425 0.367 0.791
#> Item.28 600 0.530 0.500 0.465 0.383 0.789
#> Item.29 600 0.340 0.474 0.407 0.324 0.791
#> Item.30 600 0.440 0.497 0.255 0.159 0.799
#> Item.31 600 0.833 0.373 0.479 0.419 0.788
#> Item.32 600 0.162 0.368 0.110 0.037 0.802
#>
#> $proportions
#> 0 1
#> Item.1 0.717 0.283
#> Item.2 0.432 0.568
#> Item.3 0.720 0.280
#> Item.4 0.622 0.378
#> Item.5 0.380 0.620
#> Item.6 0.840 0.160
#> Item.7 0.240 0.760
#> Item.8 0.798 0.202
#> Item.9 0.115 0.885
#> Item.10 0.578 0.422
#> Item.11 0.017 0.983
#> Item.12 0.585 0.415
#> Item.13 0.338 0.662
#> Item.14 0.277 0.723
#> Item.15 0.183 0.817
#> Item.16 0.587 0.413
#> Item.17 0.037 0.963
#> Item.18 0.648 0.352
#> Item.19 0.452 0.548
#> Item.20 0.127 0.873
#> Item.21 0.085 0.915
#> Item.22 0.065 0.935
#> Item.23 0.687 0.313
#> Item.24 0.272 0.728
#> Item.25 0.625 0.375
#> Item.26 0.540 0.460
#> Item.27 0.138 0.862
#> Item.28 0.470 0.530
#> Item.29 0.660 0.340
#> Item.30 0.560 0.440
#> Item.31 0.167 0.833
#> Item.32 0.838 0.162
#>
mod1 <- mirt(data, 1)
extract.mirt(mod1, 'time') #time elapsed for each estimation component
#> TOTAL: Data Estep Mstep SE Post
#> 0.355 0.049 0.116 0.177 0.000 0.001
# optionally use Newton-Raphson for (generally) faster convergence in the M-step's
mod1 <- mirt(data, 1, optimizer = 'NR')
extract.mirt(mod1, 'time')
#> TOTAL: Data Estep Mstep SE Post
#> 0.228 0.048 0.080 0.084 0.000 0.001
mod2 <- mirt(data, 2, optimizer = 'NR')
#> Warning: EM cycles terminated after 500 iterations.
# difficulty converging with reduced quadpts, reduce TOL
mod3 <- mirt(data, 3, TOL = .001, optimizer = 'NR')
anova(mod1,mod2)
#> AIC SABIC HQ BIC logLik X2 df p
#> mod1 19105.91 19184.13 19215.46 19387.31 -9488.955
#> mod2 19073.92 19190.03 19236.53 19491.63 -9441.963 93.985 31 0
anova(mod2, mod3) #negative AIC, 2 factors probably best
#> AIC SABIC HQ BIC logLik X2 df p
#> mod2 19073.92 19190.03 19236.53 19491.63 -9441.963
#> mod3 19080.18 19232.96 19294.13 19629.80 -9415.090 53.744 30 0.005
# same as above, but using the QMCEM method for generally better accuracy in mod3
mod3 <- mirt(data, 3, method = 'QMCEM', TOL = .001, optimizer = 'NR')
anova(mod2, mod3)
#> AIC SABIC HQ BIC logLik X2 df p
#> mod2 19073.92 19190.03 19236.53 19491.63 -9441.963
#> mod3 19081.58 19234.36 19295.54 19631.20 -9415.792 52.342 30 0.007
# with fixed guessing parameters
mod1g <- mirt(data, 1, guess = .1)
coef(mod1g)
#> $Item.1
#> a1 d g u
#> par 1.211 -1.737 0.1 1
#>
#> $Item.2
#> a1 d g u
#> par 1.78 0.147 0.1 1
#>
#> $Item.3
#> a1 d g u
#> par 1.91 -2.2 0.1 1
#>
#> $Item.4
#> a1 d g u
#> par 0.833 -0.944 0.1 1
#>
#> $Item.5
#> a1 d g u
#> par 1.089 0.399 0.1 1
#>
#> $Item.6
#> a1 d g u
#> par 3.265 -5.212 0.1 1
#>
#> $Item.7
#> a1 d g u
#> par 1.02 1.224 0.1 1
#>
#> $Item.8
#> a1 d g u
#> par 1.639 -2.977 0.1 1
#>
#> $Item.9
#> a1 d g u
#> par 0.49 2.007 0.1 1
#>
#> $Item.10
#> a1 d g u
#> par 1.257 -0.756 0.1 1
#>
#> $Item.11
#> a1 d g u
#> par 1.68 5.18 0.1 1
#>
#> $Item.12
#> a1 d g u
#> par 0.191 -0.625 0.1 1
#>
#> $Item.13
#> a1 d g u
#> par 1.147 0.654 0.1 1
#>
#> $Item.14
#> a1 d g u
#> par 1.099 1.008 0.1 1
#>
#> $Item.15
#> a1 d g u
#> par 1.337 1.79 0.1 1
#>
#> $Item.16
#> a1 d g u
#> par 0.923 -0.744 0.1 1
#>
#> $Item.17
#> a1 d g u
#> par 1.519 4.077 0.1 1
#>
#> $Item.18
#> a1 d g u
#> par 2.585 -1.749 0.1 1
#>
#> $Item.19
#> a1 d g u
#> par 0.91 -0.002 0.1 1
#>
#> $Item.20
#> a1 d g u
#> par 1.485 2.438 0.1 1
#>
#> $Item.21
#> a1 d g u
#> par 0.616 2.407 0.1 1
#>
#> $Item.22
#> a1 d g u
#> par 1.429 3.291 0.1 1
#>
#> $Item.23
#> a1 d g u
#> par 0.96 -1.393 0.1 1
#>
#> $Item.24
#> a1 d g u
#> par 1.282 1.099 0.1 1
#>
#> $Item.25
#> a1 d g u
#> par 1.028 -1 0.1 1
#>
#> $Item.26
#> a1 d g u
#> par 2.059 -0.658 0.1 1
#>
#> $Item.27
#> a1 d g u
#> par 1.839 2.564 0.1 1
#>
#> $Item.28
#> a1 d g u
#> par 1.222 -0.095 0.1 1
#>
#> $Item.29
#> a1 d g u
#> par 1.281 -1.357 0.1 1
#>
#> $Item.30
#> a1 d g u
#> par 0.444 -0.521 0.1 1
#>
#> $Item.31
#> a1 d g u
#> par 2.476 2.697 0.1 1
#>
#> $Item.32
#> a1 d g u
#> par 0.461 -2.742 0.1 1
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
###########
# graded rating scale example
# make some data
set.seed(1234)
a <- matrix(rep(1, 10))
d <- matrix(c(1,0.5,-.5,-1), 10, 4, byrow = TRUE)
c <- seq(-1, 1, length.out=10)
data <- simdata(a, d + c, 2000, itemtype = rep('graded',10))
itemstats(data)
#> $overall
#> N mean_total.score sd_total.score ave.r sd.r alpha SEM.alpha
#> 2000 20.196 8.33 0.203 0.027 0.719 4.419
#>
#> $itemstats
#> N mean sd total.r total.r_if_rm alpha_if_rm
#> Item_1 2000 1.284 1.510 0.512 0.359 0.700
#> Item_2 2000 1.427 1.544 0.529 0.375 0.697
#> Item_3 2000 1.592 1.584 0.545 0.389 0.695
#> Item_4 2000 1.774 1.586 0.538 0.381 0.696
#> Item_5 2000 1.910 1.607 0.539 0.380 0.696
#> Item_6 2000 2.124 1.606 0.533 0.373 0.697
#> Item_7 2000 2.284 1.598 0.520 0.359 0.700
#> Item_8 2000 2.420 1.583 0.578 0.430 0.688
#> Item_9 2000 2.606 1.543 0.530 0.377 0.697
#> Item_10 2000 2.776 1.491 0.495 0.342 0.702
#>
#> $proportions
#> 0 1 2 3 4
#> Item_1 0.500 0.096 0.182 0.065 0.158
#> Item_2 0.450 0.108 0.197 0.059 0.187
#> Item_3 0.407 0.108 0.182 0.092 0.212
#> Item_4 0.346 0.111 0.212 0.085 0.246
#> Item_5 0.319 0.102 0.211 0.086 0.281
#> Item_6 0.269 0.097 0.205 0.099 0.330
#> Item_7 0.244 0.073 0.211 0.101 0.372
#> Item_8 0.216 0.074 0.195 0.106 0.410
#> Item_9 0.175 0.072 0.196 0.083 0.473
#> Item_10 0.150 0.059 0.174 0.102 0.516
#>
mod1 <- mirt(data, 1)
mod2 <- mirt(data, 1, itemtype = 'grsm')
coef(mod2)
#> $Item_1
#> a1 b1 b2 b3 b4 c
#> par 0.959 0.001 -0.507 -1.541 -2.032 0
#>
#> $Item_2
#> a1 b1 b2 b3 b4 c
#> par 0.987 0.001 -0.507 -1.541 -2.032 0.235
#>
#> $Item_3
#> a1 b1 b2 b3 b4 c
#> par 0.994 0.001 -0.507 -1.541 -2.032 0.457
#>
#> $Item_4
#> a1 b1 b2 b3 b4 c
#> par 1.027 0.001 -0.507 -1.541 -2.032 0.728
#>
#> $Item_5
#> a1 b1 b2 b3 b4 c
#> par 0.995 0.001 -0.507 -1.541 -2.032 0.895
#>
#> $Item_6
#> a1 b1 b2 b3 b4 c
#> par 0.987 0.001 -0.507 -1.541 -2.032 1.179
#>
#> $Item_7
#> a1 b1 b2 b3 b4 c
#> par 0.957 0.001 -0.507 -1.541 -2.032 1.404
#>
#> $Item_8
#> a1 b1 b2 b3 b4 c
#> par 1.04 0.001 -0.507 -1.541 -2.032 1.578
#>
#> $Item_9
#> a1 b1 b2 b3 b4 c
#> par 0.964 0.001 -0.507 -1.541 -2.032 1.878
#>
#> $Item_10
#> a1 b1 b2 b3 b4 c
#> par 0.947 0.001 -0.507 -1.541 -2.032 2.136
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1
#>
anova(mod2, mod1) #not sig, mod2 should be preferred
#> AIC SABIC HQ BIC logLik X2 df p
#> mod2 55239.72 55295.47 55287.03 55368.55 -27596.86
#> mod1 55252.05 55373.25 55354.88 55532.10 -27576.03 41.671 27 0.035
itemplot(mod2, 1)
 itemplot(mod2, 5)
itemplot(mod2, 5)
 itemplot(mod2, 10)
itemplot(mod2, 10)
 ###########
# 2PL nominal response model example (Suh and Bolt, 2010)
data(SAT12)
SAT12[SAT12 == 8] <- NA #set 8 as a missing value
head(SAT12)
#> Item.1 Item.2 Item.3 Item.4 Item.5 Item.6 Item.7 Item.8 Item.9 Item.10
#> 1 1 4 5 2 3 1 2 1 3 1
#> 2 3 4 2 NA 3 3 2 NA 3 1
#> 3 1 4 5 4 3 2 2 3 3 2
#> 4 2 4 4 2 3 3 2 4 3 2
#> 5 2 4 5 2 3 2 2 1 1 2
#> 6 1 4 3 1 3 2 2 3 3 1
#> Item.11 Item.12 Item.13 Item.14 Item.15 Item.16 Item.17 Item.18 Item.19
#> 1 2 4 2 1 5 3 4 4 1
#> 2 2 NA 2 1 5 2 4 1 1
#> 3 2 1 3 1 5 5 4 1 3
#> 4 2 4 2 1 5 2 4 1 3
#> 5 2 4 2 1 5 4 4 5 1
#> 6 2 3 2 1 5 5 4 4 1
#> Item.20 Item.21 Item.22 Item.23 Item.24 Item.25 Item.26 Item.27 Item.28
#> 1 4 3 3 4 1 3 5 1 3
#> 2 4 3 3 NA 1 NA 4 1 4
#> 3 4 3 3 1 1 3 4 1 3
#> 4 4 3 1 5 2 5 4 1 3
#> 5 4 3 3 3 1 1 5 1 3
#> 6 4 3 3 4 1 1 4 1 4
#> Item.29 Item.30 Item.31 Item.32
#> 1 1 5 4 5
#> 2 5 NA 4 NA
#> 3 4 4 4 1
#> 4 4 2 4 2
#> 5 1 2 4 1
#> 6 2 3 4 3
# correct answer key
key <- c(1,4,5,2,3,1,2,1,3,1,2,4,2,1,5,3,4,4,1,4,3,3,4,1,3,5,1,3,1,5,4,5)
scoredSAT12 <- key2binary(SAT12, key)
mod0 <- mirt(scoredSAT12, 1)
# for first 5 items use 2PLNRM and nominal
scoredSAT12[,1:5] <- as.matrix(SAT12[,1:5])
mod1 <- mirt(scoredSAT12, 1, c(rep('nominal',5),rep('2PL', 27)))
mod2 <- mirt(scoredSAT12, 1, c(rep('2PLNRM',5),rep('2PL', 27)), key=key)
coef(mod0)$Item.1
#> a1 d g u
#> par 0.8107167 -1.042366 0 1
coef(mod1)$Item.1
#> a1 ak0 ak1 ak2 ak3 ak4 d0 d1 d2
#> par -0.8772035 0 0.5286601 1.116593 1.129494 4 0 -0.1909232 0.01878857
#> d3 d4
#> par -0.1258261 -5.65218
coef(mod2)$Item.1
#> a1 d g u ak0 ak1 ak2 ak3 d0 d1
#> par 0.8102548 -1.04233 0 1 0 -0.5653287 -0.5712706 -3.025613 0 0.2117761
#> d2 d3
#> par 0.06919723 -5.309272
itemplot(mod0, 1)
###########
# 2PL nominal response model example (Suh and Bolt, 2010)
data(SAT12)
SAT12[SAT12 == 8] <- NA #set 8 as a missing value
head(SAT12)
#> Item.1 Item.2 Item.3 Item.4 Item.5 Item.6 Item.7 Item.8 Item.9 Item.10
#> 1 1 4 5 2 3 1 2 1 3 1
#> 2 3 4 2 NA 3 3 2 NA 3 1
#> 3 1 4 5 4 3 2 2 3 3 2
#> 4 2 4 4 2 3 3 2 4 3 2
#> 5 2 4 5 2 3 2 2 1 1 2
#> 6 1 4 3 1 3 2 2 3 3 1
#> Item.11 Item.12 Item.13 Item.14 Item.15 Item.16 Item.17 Item.18 Item.19
#> 1 2 4 2 1 5 3 4 4 1
#> 2 2 NA 2 1 5 2 4 1 1
#> 3 2 1 3 1 5 5 4 1 3
#> 4 2 4 2 1 5 2 4 1 3
#> 5 2 4 2 1 5 4 4 5 1
#> 6 2 3 2 1 5 5 4 4 1
#> Item.20 Item.21 Item.22 Item.23 Item.24 Item.25 Item.26 Item.27 Item.28
#> 1 4 3 3 4 1 3 5 1 3
#> 2 4 3 3 NA 1 NA 4 1 4
#> 3 4 3 3 1 1 3 4 1 3
#> 4 4 3 1 5 2 5 4 1 3
#> 5 4 3 3 3 1 1 5 1 3
#> 6 4 3 3 4 1 1 4 1 4
#> Item.29 Item.30 Item.31 Item.32
#> 1 1 5 4 5
#> 2 5 NA 4 NA
#> 3 4 4 4 1
#> 4 4 2 4 2
#> 5 1 2 4 1
#> 6 2 3 4 3
# correct answer key
key <- c(1,4,5,2,3,1,2,1,3,1,2,4,2,1,5,3,4,4,1,4,3,3,4,1,3,5,1,3,1,5,4,5)
scoredSAT12 <- key2binary(SAT12, key)
mod0 <- mirt(scoredSAT12, 1)
# for first 5 items use 2PLNRM and nominal
scoredSAT12[,1:5] <- as.matrix(SAT12[,1:5])
mod1 <- mirt(scoredSAT12, 1, c(rep('nominal',5),rep('2PL', 27)))
mod2 <- mirt(scoredSAT12, 1, c(rep('2PLNRM',5),rep('2PL', 27)), key=key)
coef(mod0)$Item.1
#> a1 d g u
#> par 0.8107167 -1.042366 0 1
coef(mod1)$Item.1
#> a1 ak0 ak1 ak2 ak3 ak4 d0 d1 d2
#> par -0.8772035 0 0.5286601 1.116593 1.129494 4 0 -0.1909232 0.01878857
#> d3 d4
#> par -0.1258261 -5.65218
coef(mod2)$Item.1
#> a1 d g u ak0 ak1 ak2 ak3 d0 d1
#> par 0.8102548 -1.04233 0 1 0 -0.5653287 -0.5712706 -3.025613 0 0.2117761
#> d2 d3
#> par 0.06919723 -5.309272
itemplot(mod0, 1)
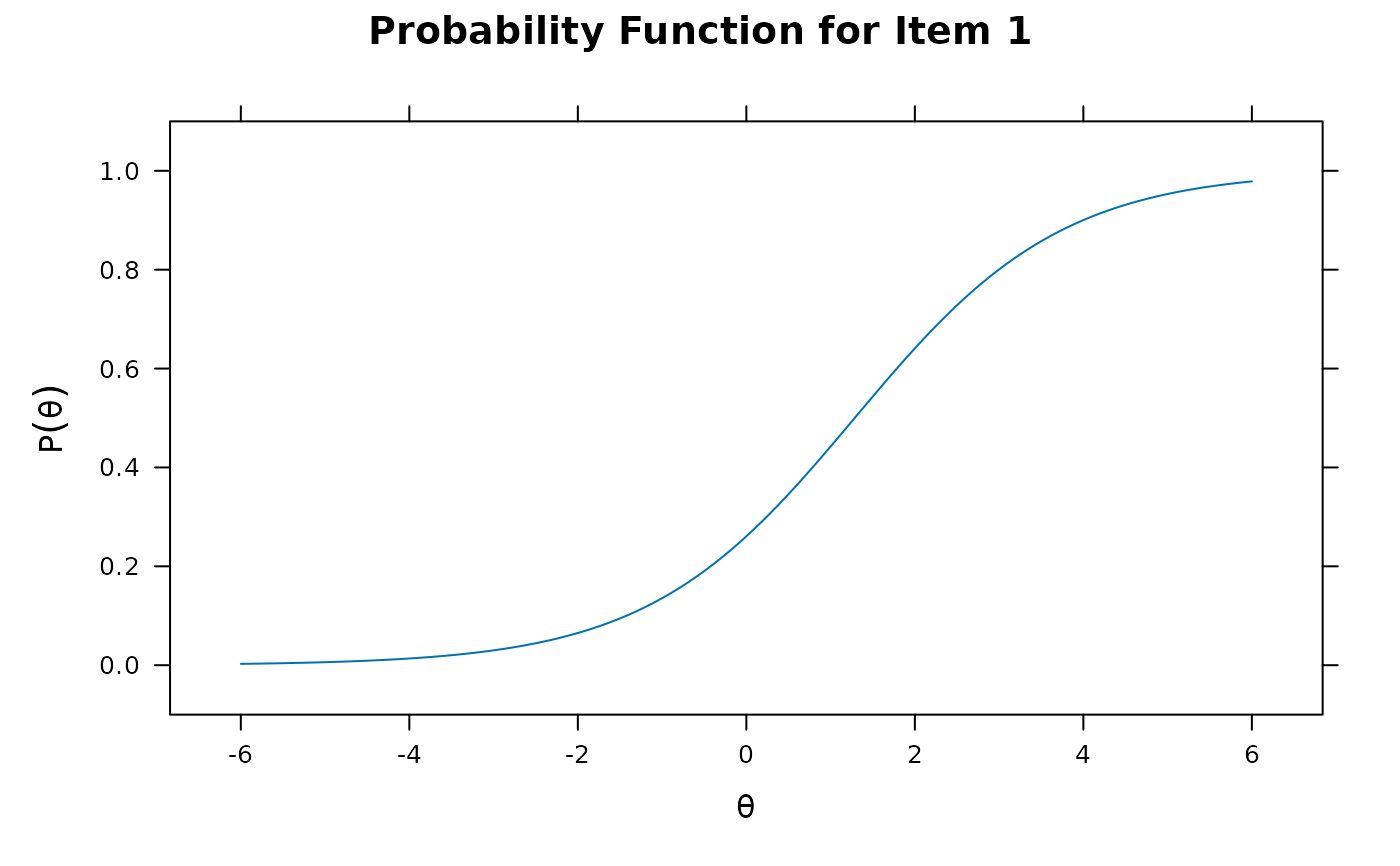 itemplot(mod1, 1)
itemplot(mod1, 1)
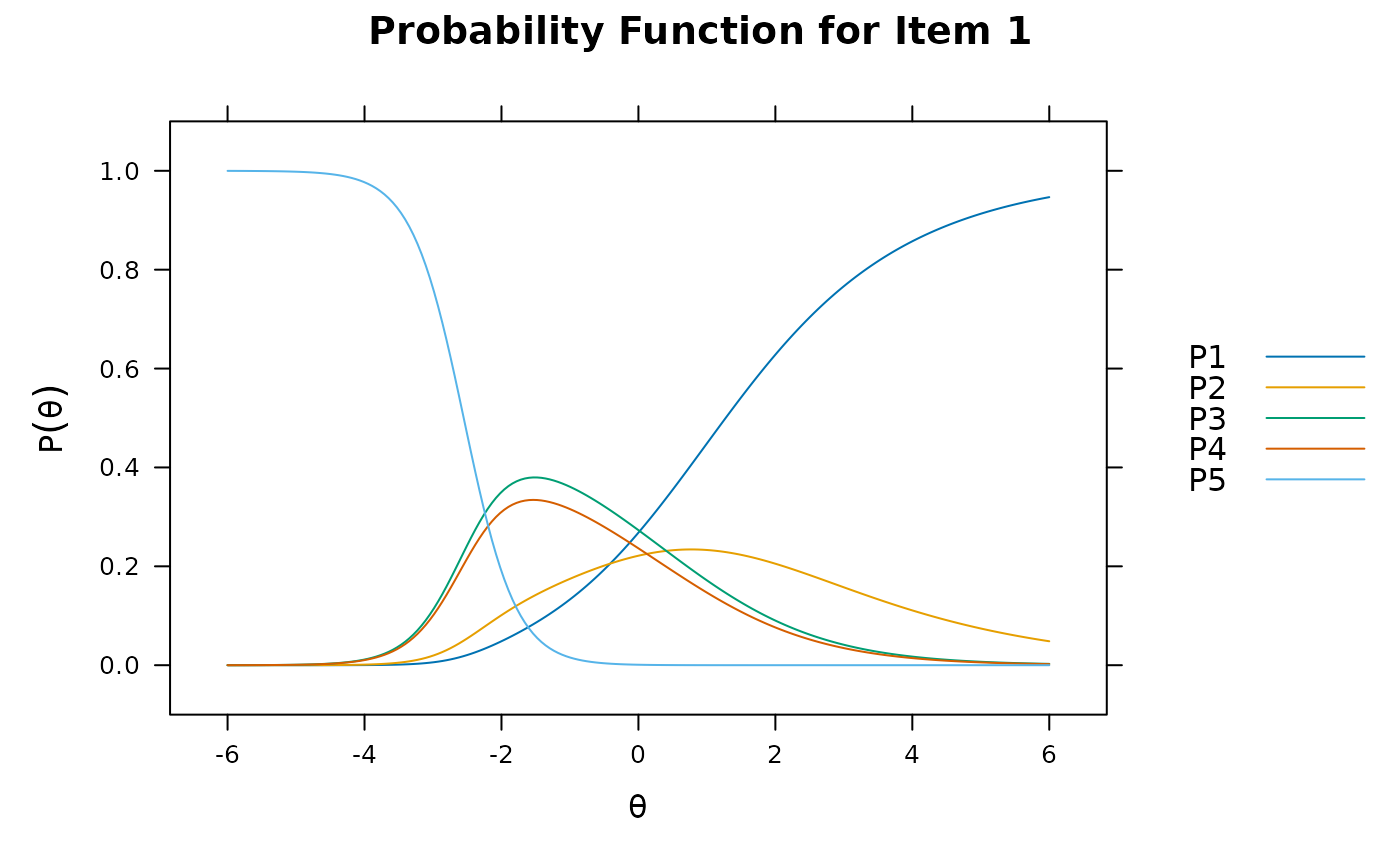 itemplot(mod2, 1)
itemplot(mod2, 1)
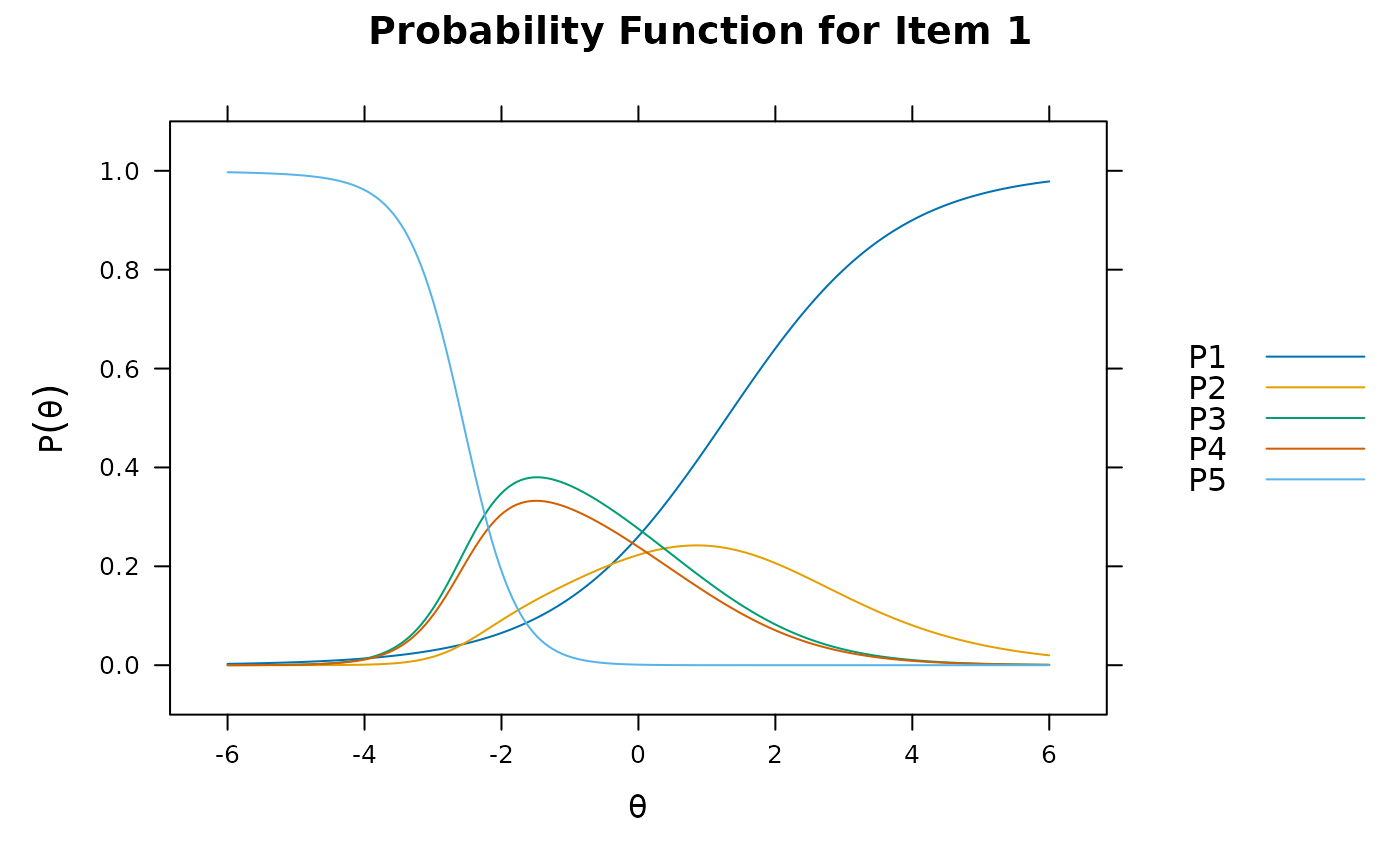 # compare added information from distractors
Theta <- matrix(seq(-4,4,.01))
par(mfrow = c(2,3))
for(i in 1:5){
info <- iteminfo(extract.item(mod0,i), Theta)
info2 <- iteminfo(extract.item(mod2,i), Theta)
plot(Theta, info2, type = 'l', main = paste('Information for item', i), ylab = 'Information')
lines(Theta, info, col = 'red')
}
par(mfrow = c(1,1))
# compare added information from distractors
Theta <- matrix(seq(-4,4,.01))
par(mfrow = c(2,3))
for(i in 1:5){
info <- iteminfo(extract.item(mod0,i), Theta)
info2 <- iteminfo(extract.item(mod2,i), Theta)
plot(Theta, info2, type = 'l', main = paste('Information for item', i), ylab = 'Information')
lines(Theta, info, col = 'red')
}
par(mfrow = c(1,1))
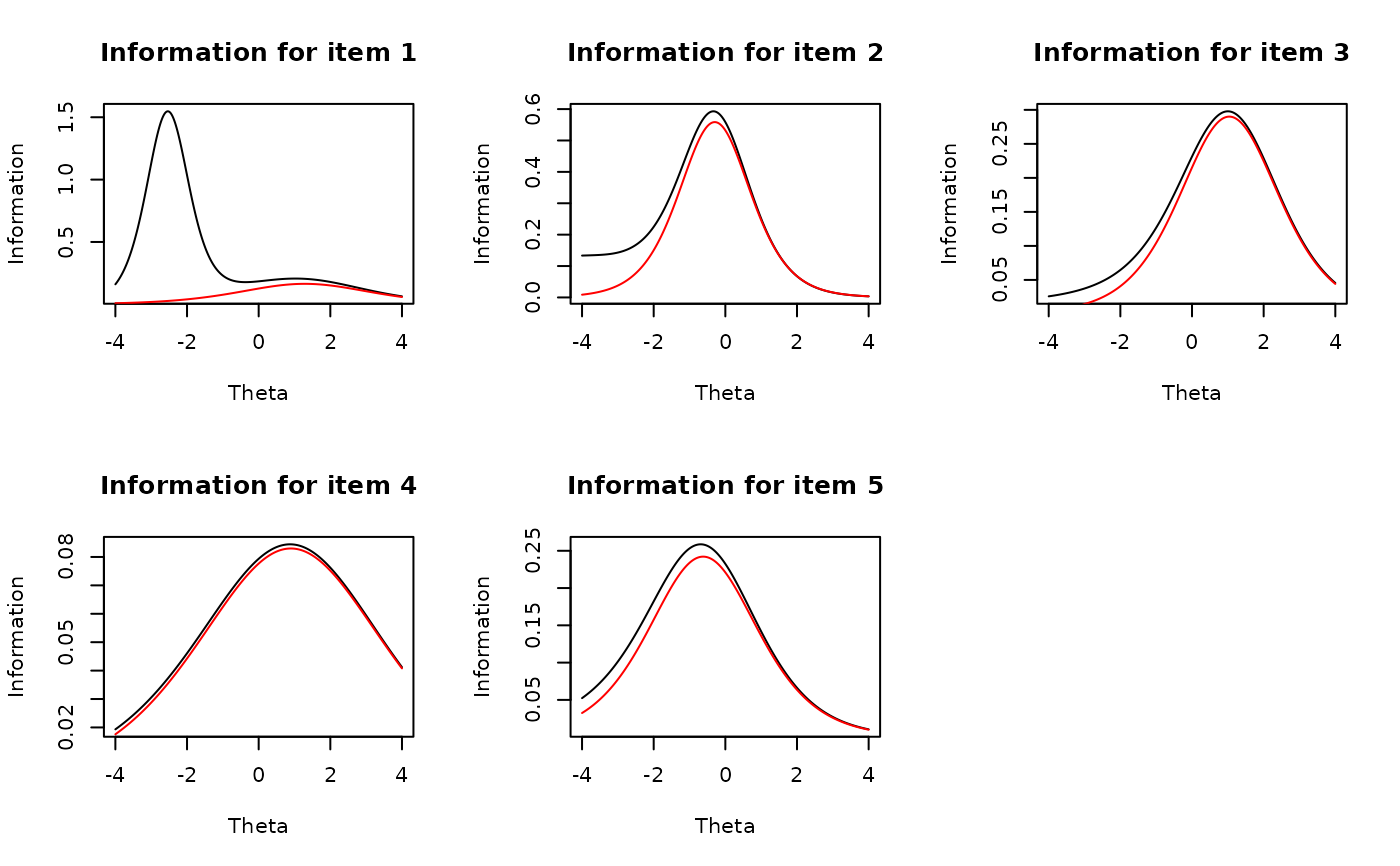 # test information
plot(Theta, testinfo(mod2, Theta), type = 'l', main = 'Test information', ylab = 'Information')
lines(Theta, testinfo(mod0, Theta), col = 'red')
# test information
plot(Theta, testinfo(mod2, Theta), type = 'l', main = 'Test information', ylab = 'Information')
lines(Theta, testinfo(mod0, Theta), col = 'red')
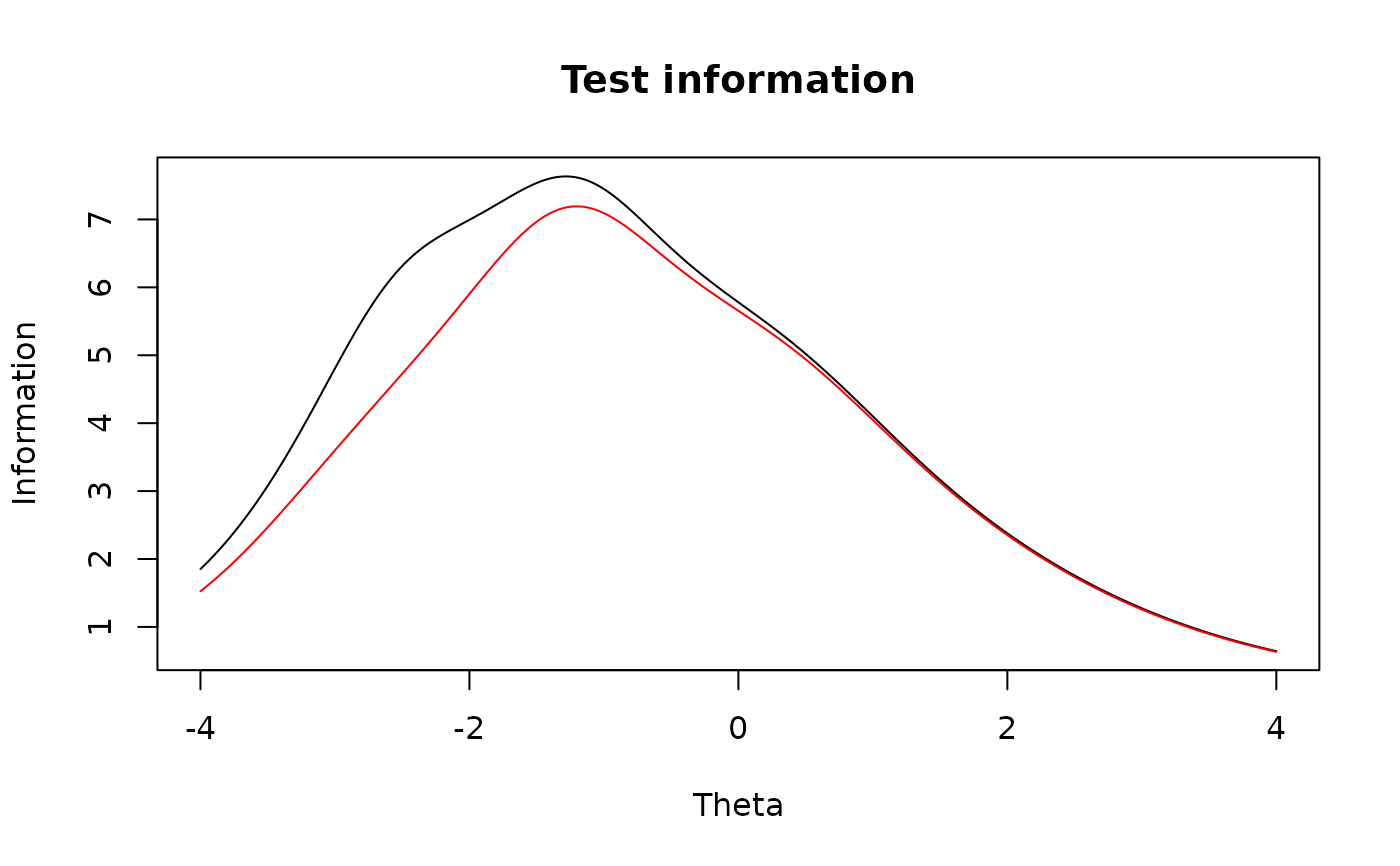 ###########
# using the MH-RM algorithm
data(LSAT7)
fulldata <- expand.table(LSAT7)
(mod1 <- mirt(fulldata, 1, method = 'MHRM'))
#>
#> Call:
#> mirt(data = fulldata, model = 1, method = "MHRM")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 0.001 tolerance after 73 MHRM iterations.
#> mirt version: 1.43
#> M-step optimizer: NR1
#> Latent density type: Gaussian
#> Average MH acceptance ratio(s): 0.4
#>
#> Log-likelihood = -2659.472, SE = 0.018
#> Estimated parameters: 10
#> AIC = 5338.944
#> BIC = 5388.022; SABIC = 5356.261
#> G2 (21) = 32.89, p = 0.0475
#> RMSEA = 0.024, CFI = NaN, TLI = NaN
# Confirmatory models
# simulate data
a <- matrix(c(
1.5,NA,
0.5,NA,
1.0,NA,
1.0,0.5,
NA,1.5,
NA,0.5,
NA,1.0,
NA,1.0),ncol=2,byrow=TRUE)
d <- matrix(c(
-1.0,NA,NA,
-1.5,NA,NA,
1.5,NA,NA,
0.0,NA,NA,
3.0,2.0,-0.5,
2.5,1.0,-1,
2.0,0.0,NA,
1.0,NA,NA),ncol=3,byrow=TRUE)
sigma <- diag(2)
sigma[1,2] <- sigma[2,1] <- .4
items <- c(rep('2PL',4), rep('graded',3), '2PL')
dataset <- simdata(a,d,2000,items,sigma)
# analyses
# CIFA for 2 factor crossed structure
model.1 <- '
F1 = 1-4
F2 = 4-8
COV = F1*F2'
# compute model, and use parallel computation of the log-likelihood
if(interactive()) mirtCluster()
mod1 <- mirt(dataset, model.1, method = 'MHRM')
coef(mod1)
#> $Item_1
#> a1 a2 d g u
#> par 1.668 0 -1.024 0 1
#>
#> $Item_2
#> a1 a2 d g u
#> par 0.327 0 -1.502 0 1
#>
#> $Item_3
#> a1 a2 d g u
#> par 0.976 0 1.487 0 1
#>
#> $Item_4
#> a1 a2 d g u
#> par 1.073 0.569 0.076 0 1
#>
#> $Item_5
#> a1 a2 d1 d2 d3
#> par 0 1.669 3.233 2.194 -0.587
#>
#> $Item_6
#> a1 a2 d1 d2 d3
#> par 0 0.402 2.418 0.932 -0.944
#>
#> $Item_7
#> a1 a2 d1 d2
#> par 0 0.915 1.884 0.018
#>
#> $Item_8
#> a1 a2 d g u
#> par 0 0.957 1.016 0 1
#>
#> $GroupPars
#> MEAN_1 MEAN_2 COV_11 COV_21 COV_22
#> par 0 0 1 0.464 1
#>
summary(mod1)
#> F1 F2 h2
#> Item_1 0.700 0.000 0.4900
#> Item_2 0.189 0.000 0.0356
#> Item_3 0.498 0.000 0.2475
#> Item_4 0.513 0.272 0.3374
#> Item_5 0.000 0.700 0.4902
#> Item_6 0.000 0.230 0.0529
#> Item_7 0.000 0.473 0.2241
#> Item_8 0.000 0.490 0.2400
#>
#> SS loadings: 1.036 1.081
#> Proportion Var: 0.13 0.135
#>
#> Factor correlations:
#>
#> F1 F2
#> F1 1.000
#> F2 0.464 1
residuals(mod1)
#> LD matrix (lower triangle) and standardized residual correlations (upper triangle)
#>
#> Upper triangle summary:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> -0.068 -0.021 0.000 -0.001 0.016 0.077
#>
#> Item_1 Item_2 Item_3 Item_4 Item_5 Item_6 Item_7 Item_8
#> Item_1 -0.021 0.004 -0.002 0.020 -0.019 0.004 0.004
#> Item_2 0.921 0.014 0.007 0.044 -0.038 0.077 0.009
#> Item_3 0.030 0.404 0.002 -0.030 0.024 -0.018 -0.009
#> Item_4 0.009 0.094 0.011 -0.041 -0.031 -0.025 0.042
#> Item_5 0.802 3.910 1.851 3.355 -0.021 0.024 -0.015
#> Item_6 0.696 2.911 1.156 1.950 2.687 0.045 -0.068
#> Item_7 0.034 11.845 0.637 1.236 2.335 8.233 -0.013
#> Item_8 0.031 0.147 0.147 3.467 0.448 9.292 0.346
#####
# bifactor
model.3 <- '
G = 1-8
F1 = 1-4
F2 = 5-8'
mod3 <- mirt(dataset,model.3, method = 'MHRM')
coef(mod3)
#> $Item_1
#> a1 a2 a3 d g u
#> par 0.926 1.21 0 -0.982 0 1
#>
#> $Item_2
#> a1 a2 a3 d g u
#> par 0.318 0.109 0 -1.504 0 1
#>
#> $Item_3
#> a1 a2 a3 d g u
#> par 0.467 1.032 0 1.558 0 1
#>
#> $Item_4
#> a1 a2 a3 d g u
#> par 1.378 0.787 0 0.082 0 1
#>
#> $Item_5
#> a1 a2 a3 d1 d2 d3
#> par 1.318 0 0.88 3.157 2.143 -0.563
#>
#> $Item_6
#> a1 a2 a3 d1 d2 d3
#> par 0.305 0 0.237 2.414 0.931 -0.94
#>
#> $Item_7
#> a1 a2 a3 d1 d2
#> par 0.733 0 0.739 1.954 0.023
#>
#> $Item_8
#> a1 a2 a3 d g u
#> par 0.943 0 0.26 1.024 0 1
#>
#> $GroupPars
#> MEAN_1 MEAN_2 MEAN_3 COV_11 COV_21 COV_31 COV_22 COV_32 COV_33
#> par 0 0 0 1 0 0 1 0 1
#>
summary(mod3)
#> G F1 F2 h2
#> Item_1 0.405 0.5297 0.000 0.4449
#> Item_2 0.183 0.0629 0.000 0.0375
#> Item_3 0.228 0.5047 0.000 0.3069
#> Item_4 0.592 0.3384 0.000 0.4650
#> Item_5 0.567 0.0000 0.378 0.4644
#> Item_6 0.175 0.0000 0.136 0.0489
#> Item_7 0.368 0.0000 0.370 0.2723
#> Item_8 0.481 0.0000 0.132 0.2485
#>
#> SS loadings: 1.318 0.654 0.316
#> Proportion Var: 0.165 0.082 0.04
#>
#> Factor correlations:
#>
#> G F1 F2
#> G 1
#> F1 0 1
#> F2 0 0 1
residuals(mod3)
#> LD matrix (lower triangle) and standardized residual correlations (upper triangle)
#>
#> Upper triangle summary:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> -0.042 -0.014 0.005 0.006 0.022 0.068
#>
#> Item_1 Item_2 Item_3 Item_4 Item_5 Item_6 Item_7 Item_8
#> Item_1 -0.009 -0.004 0.003 -0.021 0.018 0.007 -0.018
#> Item_2 0.153 0.023 -0.003 -0.042 -0.042 0.063 -0.014
#> Item_3 0.026 1.078 -0.003 -0.014 0.033 0.012 -0.007
#> Item_4 0.017 0.017 0.016 0.041 0.031 -0.017 0.011
#> Item_5 0.848 3.453 0.420 3.391 0.021 -0.025 0.006
#> Item_6 0.677 3.518 2.129 1.909 2.730 0.045 0.068
#> Item_7 0.104 7.916 0.298 0.561 2.413 8.223 0.013
#> Item_8 0.639 0.399 0.094 0.244 0.080 9.376 0.348
anova(mod1,mod3)
#> AIC SABIC HQ BIC logLik X2 df p
#> mod1 24795.08 24850.82 24842.38 24923.9 -12374.54
#> mod3 24801.87 24872.17 24861.51 24964.3 -12371.94 5.201 6 0.518
#####
# polynomial/combinations
data(SAT12)
data <- key2binary(SAT12,
key = c(1,4,5,2,3,1,2,1,3,1,2,4,2,1,5,3,4,4,1,4,3,3,4,1,3,5,1,3,1,5,4,5))
model.quad <- '
F1 = 1-32
(F1*F1) = 1-32'
model.combo <- '
F1 = 1-16
F2 = 17-32
(F1*F2) = 1-8'
(mod.quad <- mirt(data, model.quad))
#> Warning: EM cycles terminated after 500 iterations.
#>
#> Call:
#> mirt(data = data, model = model.quad)
#>
#> Full-information item factor analysis with 1 factor(s).
#> FAILED TO CONVERGE within 1e-04 tolerance after 500 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -9424.241
#> Estimated parameters: 96
#> AIC = 19040.48
#> BIC = 19462.59; SABIC = 19157.81
#>
summary(mod.quad)
#> F1 (F1*F1) h2
#> Item.1 0.24663 0.3209 0.1638
#> Item.2 0.31596 0.6624 0.5387
#> Item.3 0.18818 0.4633 0.2501
#> Item.4 0.22510 0.2806 0.1294
#> Item.5 0.26811 0.4770 0.2994
#> Item.6 0.22963 0.4344 0.2414
#> Item.7 -0.23582 0.6831 0.5222
#> Item.8 0.07027 0.3231 0.1093
#> Item.9 0.07005 0.2450 0.0649
#> Item.10 0.12791 0.4486 0.2176
#> Item.11 -0.00281 0.9833 0.9668
#> Item.12 0.13108 0.0672 0.0217
#> Item.13 -0.12488 0.6409 0.4263
#> Item.14 0.42095 0.5445 0.4737
#> Item.15 -0.26242 0.8067 0.7197
#> Item.16 0.15664 0.3586 0.1531
#> Item.17 -0.31048 0.8826 0.8754
#> Item.18 0.22351 0.6548 0.4787
#> Item.19 0.17123 0.4040 0.1925
#> Item.20 0.36774 0.7936 0.7651
#> Item.21 -0.36757 0.5732 0.4636
#> Item.22 -0.27773 0.9318 0.9455
#> Item.23 0.41388 0.2198 0.2196
#> Item.24 -0.13625 0.7628 0.6005
#> Item.25 0.60633 0.2566 0.4335
#> Item.26 0.35193 0.6301 0.5209
#> Item.27 -0.05667 0.9283 0.8650
#> Item.28 0.08842 0.5132 0.2712
#> Item.29 0.26492 0.3620 0.2012
#> Item.30 0.05452 0.1697 0.0318
#> Item.31 0.25344 0.9268 0.9232
#> Item.32 0.01294 0.1086 0.0120
#>
#> SS loadings: 2.11 10.988
#> Proportion Var: 0.066 0.343
#>
#> Factor correlations:
#>
#> F1
#> F1 1
(mod.combo <- mirt(data, model.combo))
#>
#> Call:
#> mirt(data = data, model = model.combo)
#>
#> Full-information item factor analysis with 2 factor(s).
#> Converged within 1e-04 tolerance after 22 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 31
#> Latent density type: Gaussian
#>
#> Log-likelihood = -9619.871
#> Estimated parameters: 72
#> AIC = 19383.74
#> BIC = 19700.32; SABIC = 19471.74
#>
anova(mod.combo, mod.quad)
#> AIC SABIC HQ BIC logLik X2 df p
#> mod.combo 19383.74 19471.74 19506.98 19700.32 -9619.871
#> mod.quad 19040.48 19157.81 19204.80 19462.59 -9424.241 391.259 24 0
# non-linear item and test plots
plot(mod.quad)
###########
# using the MH-RM algorithm
data(LSAT7)
fulldata <- expand.table(LSAT7)
(mod1 <- mirt(fulldata, 1, method = 'MHRM'))
#>
#> Call:
#> mirt(data = fulldata, model = 1, method = "MHRM")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 0.001 tolerance after 73 MHRM iterations.
#> mirt version: 1.43
#> M-step optimizer: NR1
#> Latent density type: Gaussian
#> Average MH acceptance ratio(s): 0.4
#>
#> Log-likelihood = -2659.472, SE = 0.018
#> Estimated parameters: 10
#> AIC = 5338.944
#> BIC = 5388.022; SABIC = 5356.261
#> G2 (21) = 32.89, p = 0.0475
#> RMSEA = 0.024, CFI = NaN, TLI = NaN
# Confirmatory models
# simulate data
a <- matrix(c(
1.5,NA,
0.5,NA,
1.0,NA,
1.0,0.5,
NA,1.5,
NA,0.5,
NA,1.0,
NA,1.0),ncol=2,byrow=TRUE)
d <- matrix(c(
-1.0,NA,NA,
-1.5,NA,NA,
1.5,NA,NA,
0.0,NA,NA,
3.0,2.0,-0.5,
2.5,1.0,-1,
2.0,0.0,NA,
1.0,NA,NA),ncol=3,byrow=TRUE)
sigma <- diag(2)
sigma[1,2] <- sigma[2,1] <- .4
items <- c(rep('2PL',4), rep('graded',3), '2PL')
dataset <- simdata(a,d,2000,items,sigma)
# analyses
# CIFA for 2 factor crossed structure
model.1 <- '
F1 = 1-4
F2 = 4-8
COV = F1*F2'
# compute model, and use parallel computation of the log-likelihood
if(interactive()) mirtCluster()
mod1 <- mirt(dataset, model.1, method = 'MHRM')
coef(mod1)
#> $Item_1
#> a1 a2 d g u
#> par 1.668 0 -1.024 0 1
#>
#> $Item_2
#> a1 a2 d g u
#> par 0.327 0 -1.502 0 1
#>
#> $Item_3
#> a1 a2 d g u
#> par 0.976 0 1.487 0 1
#>
#> $Item_4
#> a1 a2 d g u
#> par 1.073 0.569 0.076 0 1
#>
#> $Item_5
#> a1 a2 d1 d2 d3
#> par 0 1.669 3.233 2.194 -0.587
#>
#> $Item_6
#> a1 a2 d1 d2 d3
#> par 0 0.402 2.418 0.932 -0.944
#>
#> $Item_7
#> a1 a2 d1 d2
#> par 0 0.915 1.884 0.018
#>
#> $Item_8
#> a1 a2 d g u
#> par 0 0.957 1.016 0 1
#>
#> $GroupPars
#> MEAN_1 MEAN_2 COV_11 COV_21 COV_22
#> par 0 0 1 0.464 1
#>
summary(mod1)
#> F1 F2 h2
#> Item_1 0.700 0.000 0.4900
#> Item_2 0.189 0.000 0.0356
#> Item_3 0.498 0.000 0.2475
#> Item_4 0.513 0.272 0.3374
#> Item_5 0.000 0.700 0.4902
#> Item_6 0.000 0.230 0.0529
#> Item_7 0.000 0.473 0.2241
#> Item_8 0.000 0.490 0.2400
#>
#> SS loadings: 1.036 1.081
#> Proportion Var: 0.13 0.135
#>
#> Factor correlations:
#>
#> F1 F2
#> F1 1.000
#> F2 0.464 1
residuals(mod1)
#> LD matrix (lower triangle) and standardized residual correlations (upper triangle)
#>
#> Upper triangle summary:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> -0.068 -0.021 0.000 -0.001 0.016 0.077
#>
#> Item_1 Item_2 Item_3 Item_4 Item_5 Item_6 Item_7 Item_8
#> Item_1 -0.021 0.004 -0.002 0.020 -0.019 0.004 0.004
#> Item_2 0.921 0.014 0.007 0.044 -0.038 0.077 0.009
#> Item_3 0.030 0.404 0.002 -0.030 0.024 -0.018 -0.009
#> Item_4 0.009 0.094 0.011 -0.041 -0.031 -0.025 0.042
#> Item_5 0.802 3.910 1.851 3.355 -0.021 0.024 -0.015
#> Item_6 0.696 2.911 1.156 1.950 2.687 0.045 -0.068
#> Item_7 0.034 11.845 0.637 1.236 2.335 8.233 -0.013
#> Item_8 0.031 0.147 0.147 3.467 0.448 9.292 0.346
#####
# bifactor
model.3 <- '
G = 1-8
F1 = 1-4
F2 = 5-8'
mod3 <- mirt(dataset,model.3, method = 'MHRM')
coef(mod3)
#> $Item_1
#> a1 a2 a3 d g u
#> par 0.926 1.21 0 -0.982 0 1
#>
#> $Item_2
#> a1 a2 a3 d g u
#> par 0.318 0.109 0 -1.504 0 1
#>
#> $Item_3
#> a1 a2 a3 d g u
#> par 0.467 1.032 0 1.558 0 1
#>
#> $Item_4
#> a1 a2 a3 d g u
#> par 1.378 0.787 0 0.082 0 1
#>
#> $Item_5
#> a1 a2 a3 d1 d2 d3
#> par 1.318 0 0.88 3.157 2.143 -0.563
#>
#> $Item_6
#> a1 a2 a3 d1 d2 d3
#> par 0.305 0 0.237 2.414 0.931 -0.94
#>
#> $Item_7
#> a1 a2 a3 d1 d2
#> par 0.733 0 0.739 1.954 0.023
#>
#> $Item_8
#> a1 a2 a3 d g u
#> par 0.943 0 0.26 1.024 0 1
#>
#> $GroupPars
#> MEAN_1 MEAN_2 MEAN_3 COV_11 COV_21 COV_31 COV_22 COV_32 COV_33
#> par 0 0 0 1 0 0 1 0 1
#>
summary(mod3)
#> G F1 F2 h2
#> Item_1 0.405 0.5297 0.000 0.4449
#> Item_2 0.183 0.0629 0.000 0.0375
#> Item_3 0.228 0.5047 0.000 0.3069
#> Item_4 0.592 0.3384 0.000 0.4650
#> Item_5 0.567 0.0000 0.378 0.4644
#> Item_6 0.175 0.0000 0.136 0.0489
#> Item_7 0.368 0.0000 0.370 0.2723
#> Item_8 0.481 0.0000 0.132 0.2485
#>
#> SS loadings: 1.318 0.654 0.316
#> Proportion Var: 0.165 0.082 0.04
#>
#> Factor correlations:
#>
#> G F1 F2
#> G 1
#> F1 0 1
#> F2 0 0 1
residuals(mod3)
#> LD matrix (lower triangle) and standardized residual correlations (upper triangle)
#>
#> Upper triangle summary:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> -0.042 -0.014 0.005 0.006 0.022 0.068
#>
#> Item_1 Item_2 Item_3 Item_4 Item_5 Item_6 Item_7 Item_8
#> Item_1 -0.009 -0.004 0.003 -0.021 0.018 0.007 -0.018
#> Item_2 0.153 0.023 -0.003 -0.042 -0.042 0.063 -0.014
#> Item_3 0.026 1.078 -0.003 -0.014 0.033 0.012 -0.007
#> Item_4 0.017 0.017 0.016 0.041 0.031 -0.017 0.011
#> Item_5 0.848 3.453 0.420 3.391 0.021 -0.025 0.006
#> Item_6 0.677 3.518 2.129 1.909 2.730 0.045 0.068
#> Item_7 0.104 7.916 0.298 0.561 2.413 8.223 0.013
#> Item_8 0.639 0.399 0.094 0.244 0.080 9.376 0.348
anova(mod1,mod3)
#> AIC SABIC HQ BIC logLik X2 df p
#> mod1 24795.08 24850.82 24842.38 24923.9 -12374.54
#> mod3 24801.87 24872.17 24861.51 24964.3 -12371.94 5.201 6 0.518
#####
# polynomial/combinations
data(SAT12)
data <- key2binary(SAT12,
key = c(1,4,5,2,3,1,2,1,3,1,2,4,2,1,5,3,4,4,1,4,3,3,4,1,3,5,1,3,1,5,4,5))
model.quad <- '
F1 = 1-32
(F1*F1) = 1-32'
model.combo <- '
F1 = 1-16
F2 = 17-32
(F1*F2) = 1-8'
(mod.quad <- mirt(data, model.quad))
#> Warning: EM cycles terminated after 500 iterations.
#>
#> Call:
#> mirt(data = data, model = model.quad)
#>
#> Full-information item factor analysis with 1 factor(s).
#> FAILED TO CONVERGE within 1e-04 tolerance after 500 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -9424.241
#> Estimated parameters: 96
#> AIC = 19040.48
#> BIC = 19462.59; SABIC = 19157.81
#>
summary(mod.quad)
#> F1 (F1*F1) h2
#> Item.1 0.24663 0.3209 0.1638
#> Item.2 0.31596 0.6624 0.5387
#> Item.3 0.18818 0.4633 0.2501
#> Item.4 0.22510 0.2806 0.1294
#> Item.5 0.26811 0.4770 0.2994
#> Item.6 0.22963 0.4344 0.2414
#> Item.7 -0.23582 0.6831 0.5222
#> Item.8 0.07027 0.3231 0.1093
#> Item.9 0.07005 0.2450 0.0649
#> Item.10 0.12791 0.4486 0.2176
#> Item.11 -0.00281 0.9833 0.9668
#> Item.12 0.13108 0.0672 0.0217
#> Item.13 -0.12488 0.6409 0.4263
#> Item.14 0.42095 0.5445 0.4737
#> Item.15 -0.26242 0.8067 0.7197
#> Item.16 0.15664 0.3586 0.1531
#> Item.17 -0.31048 0.8826 0.8754
#> Item.18 0.22351 0.6548 0.4787
#> Item.19 0.17123 0.4040 0.1925
#> Item.20 0.36774 0.7936 0.7651
#> Item.21 -0.36757 0.5732 0.4636
#> Item.22 -0.27773 0.9318 0.9455
#> Item.23 0.41388 0.2198 0.2196
#> Item.24 -0.13625 0.7628 0.6005
#> Item.25 0.60633 0.2566 0.4335
#> Item.26 0.35193 0.6301 0.5209
#> Item.27 -0.05667 0.9283 0.8650
#> Item.28 0.08842 0.5132 0.2712
#> Item.29 0.26492 0.3620 0.2012
#> Item.30 0.05452 0.1697 0.0318
#> Item.31 0.25344 0.9268 0.9232
#> Item.32 0.01294 0.1086 0.0120
#>
#> SS loadings: 2.11 10.988
#> Proportion Var: 0.066 0.343
#>
#> Factor correlations:
#>
#> F1
#> F1 1
(mod.combo <- mirt(data, model.combo))
#>
#> Call:
#> mirt(data = data, model = model.combo)
#>
#> Full-information item factor analysis with 2 factor(s).
#> Converged within 1e-04 tolerance after 22 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 31
#> Latent density type: Gaussian
#>
#> Log-likelihood = -9619.871
#> Estimated parameters: 72
#> AIC = 19383.74
#> BIC = 19700.32; SABIC = 19471.74
#>
anova(mod.combo, mod.quad)
#> AIC SABIC HQ BIC logLik X2 df p
#> mod.combo 19383.74 19471.74 19506.98 19700.32 -9619.871
#> mod.quad 19040.48 19157.81 19204.80 19462.59 -9424.241 391.259 24 0
# non-linear item and test plots
plot(mod.quad)
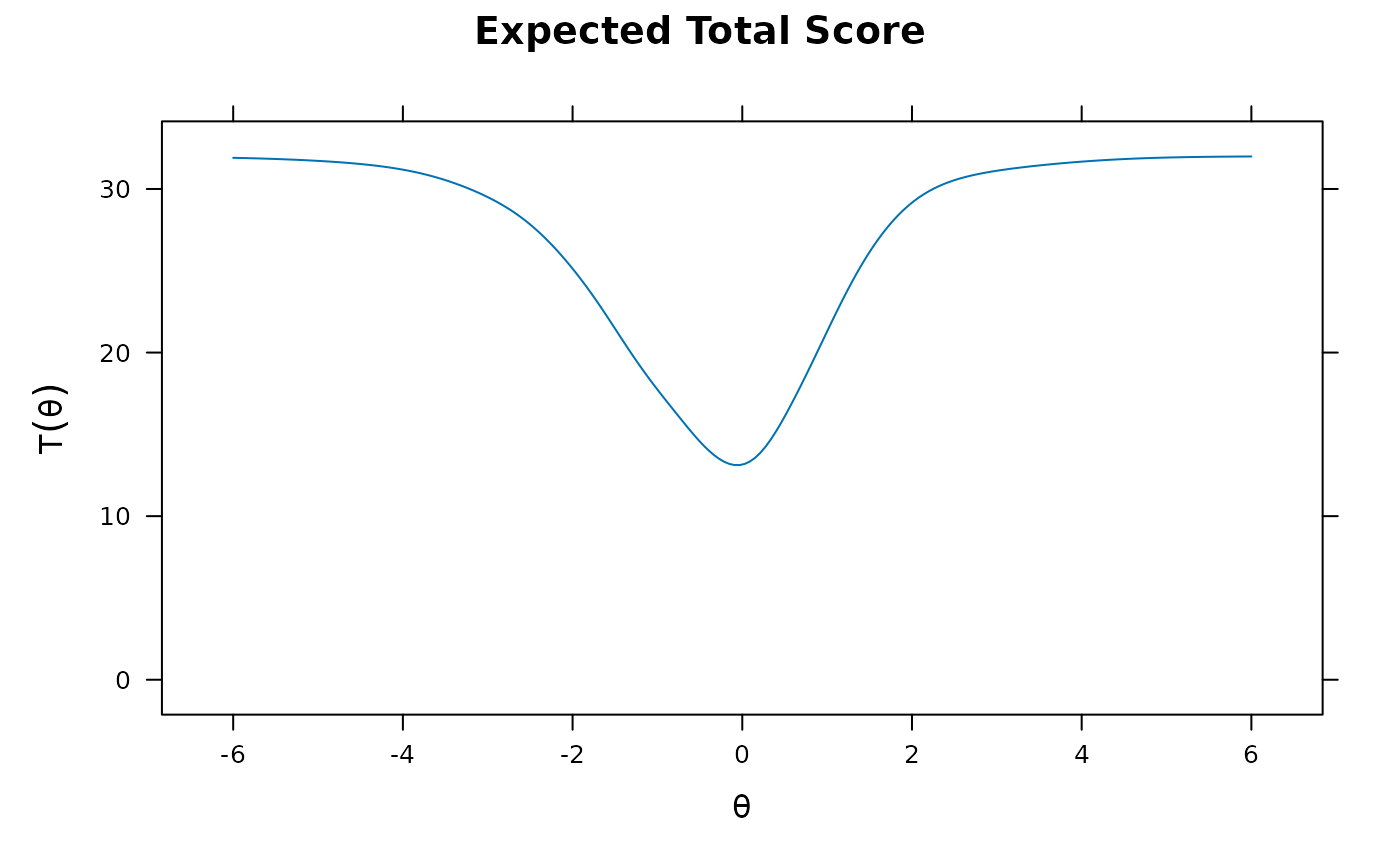 plot(mod.combo, type = 'SE')
plot(mod.combo, type = 'SE')
 itemplot(mod.quad, 1, type = 'score')
itemplot(mod.quad, 1, type = 'score')
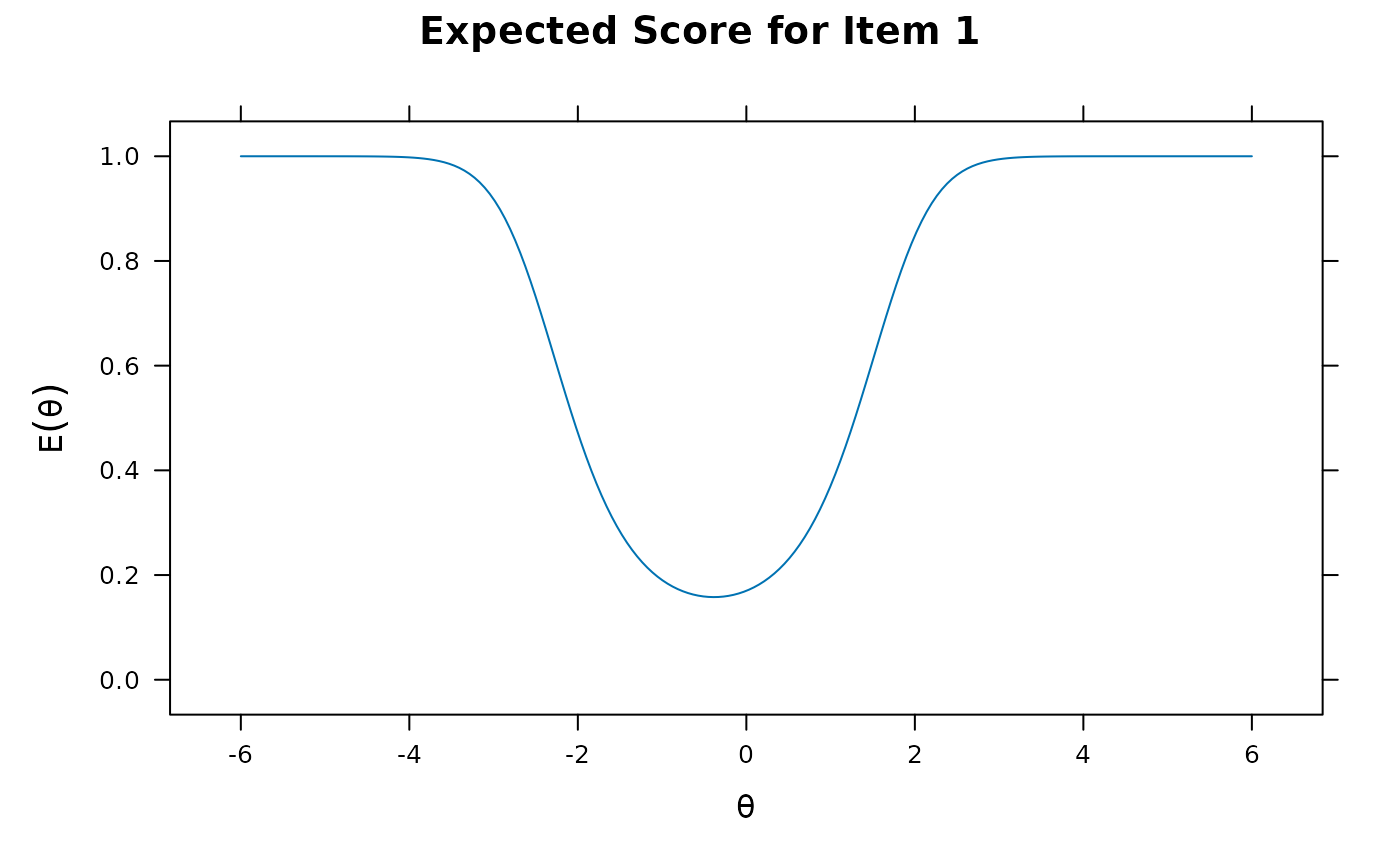 itemplot(mod.combo, 2, type = 'score')
itemplot(mod.combo, 2, type = 'score')
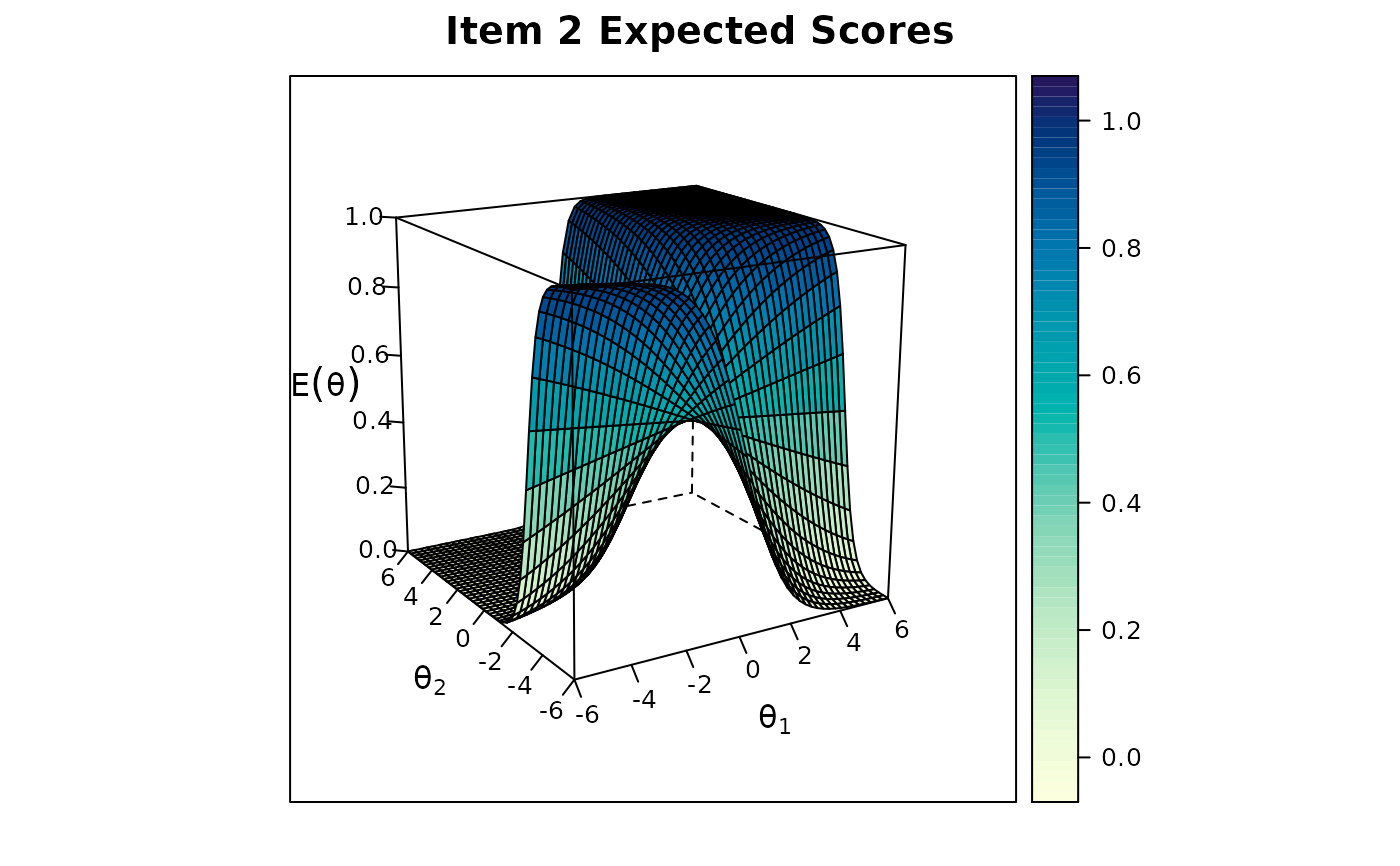 itemplot(mod.combo, 2, type = 'infocontour')
itemplot(mod.combo, 2, type = 'infocontour')
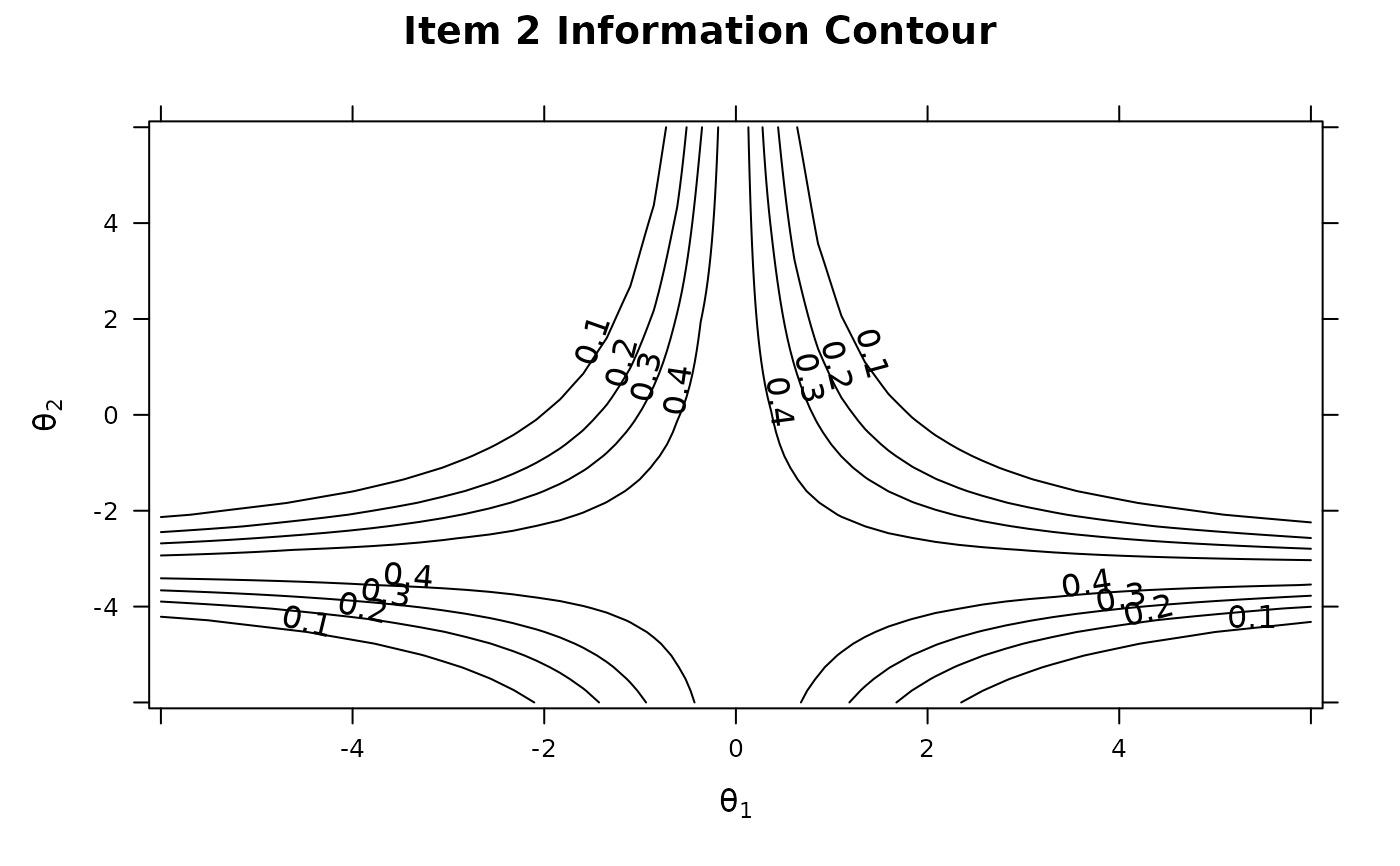 ## empirical histogram examples (normal, skew and bimodality)
# make some data
set.seed(1234)
a <- matrix(rlnorm(50, .2, .2))
d <- matrix(rnorm(50))
ThetaNormal <- matrix(rnorm(2000))
ThetaBimodal <- scale(matrix(c(rnorm(1000, -2), rnorm(1000,2)))) #bimodal
ThetaSkew <- scale(matrix(rchisq(2000, 3))) #positive skew
datNormal <- simdata(a, d, 2000, itemtype = '2PL', Theta=ThetaNormal)
datBimodal <- simdata(a, d, 2000, itemtype = '2PL', Theta=ThetaBimodal)
datSkew <- simdata(a, d, 2000, itemtype = '2PL', Theta=ThetaSkew)
normal <- mirt(datNormal, 1, dentype = "empiricalhist")
plot(normal, type = 'empiricalhist')
## empirical histogram examples (normal, skew and bimodality)
# make some data
set.seed(1234)
a <- matrix(rlnorm(50, .2, .2))
d <- matrix(rnorm(50))
ThetaNormal <- matrix(rnorm(2000))
ThetaBimodal <- scale(matrix(c(rnorm(1000, -2), rnorm(1000,2)))) #bimodal
ThetaSkew <- scale(matrix(rchisq(2000, 3))) #positive skew
datNormal <- simdata(a, d, 2000, itemtype = '2PL', Theta=ThetaNormal)
datBimodal <- simdata(a, d, 2000, itemtype = '2PL', Theta=ThetaBimodal)
datSkew <- simdata(a, d, 2000, itemtype = '2PL', Theta=ThetaSkew)
normal <- mirt(datNormal, 1, dentype = "empiricalhist")
plot(normal, type = 'empiricalhist')
 histogram(ThetaNormal, breaks=30)
histogram(ThetaNormal, breaks=30)
 bimodal <- mirt(datBimodal, 1, dentype = "empiricalhist")
plot(bimodal, type = 'empiricalhist')
bimodal <- mirt(datBimodal, 1, dentype = "empiricalhist")
plot(bimodal, type = 'empiricalhist')
 histogram(ThetaBimodal, breaks=30)
histogram(ThetaBimodal, breaks=30)
 skew <- mirt(datSkew, 1, dentype = "empiricalhist")
plot(skew, type = 'empiricalhist')
skew <- mirt(datSkew, 1, dentype = "empiricalhist")
plot(skew, type = 'empiricalhist')
 histogram(ThetaSkew, breaks=30)
histogram(ThetaSkew, breaks=30)
 #####
# non-linear parameter constraints with Rsolnp package (nloptr supported as well):
# Find Rasch model subject to the constraint that the intercepts sum to 0
dat <- expand.table(LSAT6)
itemstats(dat)
#> $overall
#> N mean_total.score sd_total.score ave.r sd.r alpha SEM.alpha
#> 1000 3.819 1.035 0.077 0.03 0.295 0.869
#>
#> $itemstats
#> N mean sd total.r total.r_if_rm alpha_if_rm
#> Item_1 1000 0.924 0.265 0.362 0.113 0.275
#> Item_2 1000 0.709 0.454 0.567 0.153 0.238
#> Item_3 1000 0.553 0.497 0.618 0.173 0.217
#> Item_4 1000 0.763 0.425 0.534 0.144 0.246
#> Item_5 1000 0.870 0.336 0.435 0.122 0.266
#>
#> $proportions
#> 0 1
#> Item_1 0.076 0.924
#> Item_2 0.291 0.709
#> Item_3 0.447 0.553
#> Item_4 0.237 0.763
#> Item_5 0.130 0.870
#>
# free latent mean and variance terms
model <- 'Theta = 1-5
MEAN = Theta
COV = Theta*Theta'
# view how vector of parameters is organized internally
sv <- mirt(dat, model, itemtype = 'Rasch', pars = 'values')
sv[sv$est, ]
#> group item class name parnum value lbound ubound est const nconst
#> 2 all Item_1 dich d 2 2.815 -Inf Inf TRUE none none
#> 6 all Item_2 dich d 6 1.082 -Inf Inf TRUE none none
#> 10 all Item_3 dich d 10 0.262 -Inf Inf TRUE none none
#> 14 all Item_4 dich d 14 1.407 -Inf Inf TRUE none none
#> 18 all Item_5 dich d 18 2.214 -Inf Inf TRUE none none
#> 21 all GROUP GroupPars MEAN_1 21 0.000 -Inf Inf TRUE none none
#> 22 all GROUP GroupPars COV_11 22 1.000 0 Inf TRUE none none
#> prior.type prior_1 prior_2
#> 2 none NaN NaN
#> 6 none NaN NaN
#> 10 none NaN NaN
#> 14 none NaN NaN
#> 18 none NaN NaN
#> 21 none NaN NaN
#> 22 none NaN NaN
# constraint: create function for solnp to compute constraint, and declare value in eqB
eqfun <- function(p, optim_args) sum(p[1:5]) #could use browser() here, if it helps
LB <- c(rep(-15, 6), 1e-4) # more reasonable lower bound for variance term
mod <- mirt(dat, model, sv=sv, itemtype = 'Rasch', optimizer = 'solnp',
solnp_args=list(eqfun=eqfun, eqB=0, LB=LB))
print(mod)
#>
#> Call:
#> mirt(data = dat, model = model, itemtype = "Rasch", optimizer = "solnp",
#> solnp_args = list(eqfun = eqfun, eqB = 0, LB = LB), sv = sv)
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 34 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: solnp
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -2466.943
#> Estimated parameters: 7
#> AIC = 4947.887
#> BIC = 4982.241; SABIC = 4960.009
#> G2 (25) = 21.81, p = 0.6467
#> RMSEA = 0, CFI = NaN, TLI = NaN
coef(mod)
#> $Item_1
#> a1 d g u
#> par 1 1.253 0 1
#>
#> $Item_2
#> a1 d g u
#> par 1 -0.475 0 1
#>
#> $Item_3
#> a1 d g u
#> par 1 -1.233 0 1
#>
#> $Item_4
#> a1 d g u
#> par 1 -0.168 0 1
#>
#> $Item_5
#> a1 d g u
#> par 1 0.623 0 1
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 1.472 0.559
#>
(ds <- sapply(coef(mod)[1:5], function(x) x[,'d']))
#> Item_1 Item_2 Item_3 Item_4 Item_5
#> 1.2529541 -0.4754463 -1.2327297 -0.1681700 0.6233919
sum(ds)
#> [1] 4.607426e-15
# same likelihood location as: mirt(dat, 1, itemtype = 'Rasch')
#######
# latent regression Rasch model
# simulate data
set.seed(1234)
N <- 1000
# covariates
X1 <- rnorm(N); X2 <- rnorm(N)
covdata <- data.frame(X1, X2, X3 = rnorm(N))
Theta <- matrix(0.5 * X1 + -1 * X2 + rnorm(N, sd = 0.5))
# items and response data
a <- matrix(1, 20); d <- matrix(rnorm(20))
dat <- simdata(a, d, 1000, itemtype = '2PL', Theta=Theta)
# unconditional Rasch model
mod0 <- mirt(dat, 1, 'Rasch', SE=TRUE)
coef(mod0, printSE=TRUE)
#> $Item_1
#> a1 d logit(g) logit(u)
#> par 1 -0.998 -999 999
#> SE NA 0.085 NA NA
#>
#> $Item_2
#> a1 d logit(g) logit(u)
#> par 1 -0.917 -999 999
#> SE NA 0.085 NA NA
#>
#> $Item_3
#> a1 d logit(g) logit(u)
#> par 1 -0.100 -999 999
#> SE NA 0.081 NA NA
#>
#> $Item_4
#> a1 d logit(g) logit(u)
#> par 1 1.893 -999 999
#> SE NA 0.099 NA NA
#>
#> $Item_5
#> a1 d logit(g) logit(u)
#> par 1 0.609 -999 999
#> SE NA 0.082 NA NA
#>
#> $Item_6
#> a1 d logit(g) logit(u)
#> par 1 1.071 -999 999
#> SE NA 0.086 NA NA
#>
#> $Item_7
#> a1 d logit(g) logit(u)
#> par 1 -0.074 -999 999
#> SE NA 0.081 NA NA
#>
#> $Item_8
#> a1 d logit(g) logit(u)
#> par 1 -1.405 -999 999
#> SE NA 0.090 NA NA
#>
#> $Item_9
#> a1 d logit(g) logit(u)
#> par 1 0.707 -999 999
#> SE NA 0.083 NA NA
#>
#> $Item_10
#> a1 d logit(g) logit(u)
#> par 1 -0.258 -999 999
#> SE NA 0.081 NA NA
#>
#> $Item_11
#> a1 d logit(g) logit(u)
#> par 1 0.336 -999 999
#> SE NA 0.081 NA NA
#>
#> $Item_12
#> a1 d logit(g) logit(u)
#> par 1 0.891 -999 999
#> SE NA 0.084 NA NA
#>
#> $Item_13
#> a1 d logit(g) logit(u)
#> par 1 0.653 -999 999
#> SE NA 0.083 NA NA
#>
#> $Item_14
#> a1 d logit(g) logit(u)
#> par 1 -1.942 -999 999
#> SE NA 0.099 NA NA
#>
#> $Item_15
#> a1 d logit(g) logit(u)
#> par 1 -2.143 -999 999
#> SE NA 0.104 NA NA
#>
#> $Item_16
#> a1 d logit(g) logit(u)
#> par 1 1.758 -999 999
#> SE NA 0.096 NA NA
#>
#> $Item_17
#> a1 d logit(g) logit(u)
#> par 1 -1.015 -999 999
#> SE NA 0.085 NA NA
#>
#> $Item_18
#> a1 d logit(g) logit(u)
#> par 1 -1.009 -999 999
#> SE NA 0.085 NA NA
#>
#> $Item_19
#> a1 d logit(g) logit(u)
#> par 1 -1.251 -999 999
#> SE NA 0.088 NA NA
#>
#> $Item_20
#> a1 d logit(g) logit(u)
#> par 1 -0.620 -999 999
#> SE NA 0.082 NA NA
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1.393
#> SE NA 0.085
#>
# conditional model using X1, X2, and X3 (bad) as predictors of Theta
mod1 <- mirt(dat, 1, 'Rasch', covdata=covdata, formula = ~ X1 + X2 + X3, SE=TRUE)
coef(mod1, printSE=TRUE)
#> $Item_1
#> a1 d logit(g) logit(u)
#> par 1 -0.967 -999 999
#> SE NA 0.078 NA NA
#>
#> $Item_2
#> a1 d logit(g) logit(u)
#> par 1 -0.887 -999 999
#> SE NA 0.077 NA NA
#>
#> $Item_3
#> a1 d logit(g) logit(u)
#> par 1 -0.068 -999 999
#> SE NA 0.073 NA NA
#>
#> $Item_4
#> a1 d logit(g) logit(u)
#> par 1 1.920 -999 999
#> SE NA 0.092 NA NA
#>
#> $Item_5
#> a1 d logit(g) logit(u)
#> par 1 0.640 -999 999
#> SE NA 0.075 NA NA
#>
#> $Item_6
#> a1 d logit(g) logit(u)
#> par 1 1.100 -999 999
#> SE NA 0.079 NA NA
#>
#> $Item_7
#> a1 d logit(g) logit(u)
#> par 1 -0.043 -999 999
#> SE NA 0.073 NA NA
#>
#> $Item_8
#> a1 d logit(g) logit(u)
#> par 1 -1.375 -999 999
#> SE NA 0.083 NA NA
#>
#> $Item_9
#> a1 d logit(g) logit(u)
#> par 1 0.737 -999 999
#> SE NA 0.076 NA NA
#>
#> $Item_10
#> a1 d logit(g) logit(u)
#> par 1 -0.227 -999 999
#> SE NA 0.073 NA NA
#>
#> $Item_11
#> a1 d logit(g) logit(u)
#> par 1 0.367 -999 999
#> SE NA 0.074 NA NA
#>
#> $Item_12
#> a1 d logit(g) logit(u)
#> par 1 0.921 -999 999
#> SE NA 0.077 NA NA
#>
#> $Item_13
#> a1 d logit(g) logit(u)
#> par 1 0.683 -999 999
#> SE NA 0.075 NA NA
#>
#> $Item_14
#> a1 d logit(g) logit(u)
#> par 1 -1.913 -999 999
#> SE NA 0.093 NA NA
#>
#> $Item_15
#> a1 d logit(g) logit(u)
#> par 1 -2.114 -999 999
#> SE NA 0.098 NA NA
#>
#> $Item_16
#> a1 d logit(g) logit(u)
#> par 1 1.786 -999 999
#> SE NA 0.090 NA NA
#>
#> $Item_17
#> a1 d logit(g) logit(u)
#> par 1 -0.985 -999 999
#> SE NA 0.078 NA NA
#>
#> $Item_18
#> a1 d logit(g) logit(u)
#> par 1 -0.979 -999 999
#> SE NA 0.078 NA NA
#>
#> $Item_19
#> a1 d logit(g) logit(u)
#> par 1 -1.221 -999 999
#> SE NA 0.081 NA NA
#>
#> $Item_20
#> a1 d logit(g) logit(u)
#> par 1 -0.589 -999 999
#> SE NA 0.075 NA NA
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 0.210
#> SE NA 0.011
#>
#> $lr.betas
#> $lr.betas$betas
#> F1
#> (Intercept) 0.000
#> X1 0.513
#> X2 -1.003
#> X3 -0.003
#>
#> $lr.betas$SE
#> F1
#> (Intercept) NA
#> X1 0.015
#> X2 0.015
#> X3 0.014
#>
#>
coef(mod1, simplify=TRUE)
#> $items
#> a1 d g u
#> Item_1 1 -0.967 0 1
#> Item_2 1 -0.887 0 1
#> Item_3 1 -0.068 0 1
#> Item_4 1 1.920 0 1
#> Item_5 1 0.640 0 1
#> Item_6 1 1.100 0 1
#> Item_7 1 -0.043 0 1
#> Item_8 1 -1.375 0 1
#> Item_9 1 0.737 0 1
#> Item_10 1 -0.227 0 1
#> Item_11 1 0.367 0 1
#> Item_12 1 0.921 0 1
#> Item_13 1 0.683 0 1
#> Item_14 1 -1.913 0 1
#> Item_15 1 -2.114 0 1
#> Item_16 1 1.786 0 1
#> Item_17 1 -0.985 0 1
#> Item_18 1 -0.979 0 1
#> Item_19 1 -1.221 0 1
#> Item_20 1 -0.589 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 0.21
#>
#> $lr.betas
#> $lr.betas$betas
#> F1
#> (Intercept) 0.000
#> X1 0.513
#> X2 -1.003
#> X3 -0.003
#>
#> $lr.betas$CI_2.5
#> F1
#> (Intercept) NA
#> X1 0.485
#> X2 -1.032
#> X3 -0.031
#>
#> $lr.betas$CI_97.5
#> F1
#> (Intercept) NA
#> X1 0.542
#> X2 -0.974
#> X3 0.025
#>
#>
anova(mod0, mod1) # jointly significant predictors of theta
#> AIC SABIC HQ BIC logLik X2 df p
#> mod0 21935.46 21971.83 21974.63 22038.53 -10946.73
#> mod1 20756.61 20798.17 20801.38 20874.40 -10354.31 1184.851 3 0
# large sample z-ratios and p-values (if one cares)
cfs <- coef(mod1, printSE=TRUE)
(z <- cfs$lr.betas[[1]] / cfs$lr.betas[[2]])
#> F1
#> (Intercept) NA
#> X1 35.266840
#> X2 -67.584691
#> X3 -0.211456
round(pnorm(abs(z[,1]), lower.tail=FALSE)*2, 3)
#> (Intercept) X1 X2 X3
#> NA 0.000 0.000 0.833
# drop predictor for nested comparison
mod1b <- mirt(dat, 1, 'Rasch', covdata=covdata, formula = ~ X1 + X2)
anova(mod1b, mod1)
#> AIC SABIC HQ BIC logLik X2 df p
#> mod1b 20754.63 20794.46 20797.53 20867.51 -10354.32
#> mod1 20756.61 20798.17 20801.38 20874.40 -10354.31 0.018 1 0.893
# compare to mixedmirt() version of the same model
mod1.mixed <- mixedmirt(dat, 1, itemtype='Rasch',
covdata=covdata, lr.fixed = ~ X1 + X2 + X3, SE=TRUE)
coef(mod1.mixed)
#> $Item_1
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_2
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_3
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_4
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_5
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_6
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_7
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_8
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_9
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_10
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_11
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_12
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_13
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_14
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_15
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_16
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_17
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_18
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_19
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_20
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 0.087
#> CI_2.5 NA 0.068
#> CI_97.5 NA 0.105
#>
#> $lr.betas
#> F1_(Intercept) F1_X1 F1_X2 F1_X3
#> par 0 0.409 -0.795 -0.007
#> CI_2.5 NA 0.376 -0.837 -0.040
#> CI_97.5 NA 0.441 -0.753 0.027
#>
coef(mod1.mixed, printSE=TRUE)
#> $Item_1
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_2
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_3
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_4
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_5
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_6
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_7
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_8
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_9
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_10
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_11
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_12
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_13
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_14
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_15
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_16
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_17
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_18
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_19
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_20
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 0.087
#> SE NA 0.009
#>
#> $lr.betas
#> F1_(Intercept) F1_X1 F1_X2 F1_X3
#> par 0 0.409 -0.795 -0.007
#> SE NA 0.016 0.021 0.017
#>
# draw plausible values for secondary analyses
pv <- fscores(mod1, plausible.draws = 10)
pvmods <- lapply(pv, function(x, covdata) lm(x ~ covdata$X1 + covdata$X2),
covdata=covdata)
# population characteristics recovered well, and can be averaged over
so <- lapply(pvmods, summary)
so
#> [[1]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.3024 -0.3253 -0.0029 0.2943 1.4209
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.002109 0.014512 0.145 0.884
#> covdata$X1 0.512293 0.014574 35.151 <2e-16 ***
#> covdata$X2 -1.021832 0.014814 -68.977 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4587 on 997 degrees of freedom
#> Multiple R-squared: 0.8519, Adjusted R-squared: 0.8517
#> F-statistic: 2869 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[2]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.37892 -0.31265 -0.01041 0.31956 1.32091
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -0.001873 0.014455 -0.13 0.897
#> covdata$X1 0.515384 0.014517 35.50 <2e-16 ***
#> covdata$X2 -1.002085 0.014756 -67.91 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4569 on 997 degrees of freedom
#> Multiple R-squared: 0.8493, Adjusted R-squared: 0.849
#> F-statistic: 2809 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[3]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.26871 -0.30200 -0.01567 0.31489 1.23601
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.006956 0.014420 0.482 0.63
#> covdata$X1 0.519090 0.014482 35.844 <2e-16 ***
#> covdata$X2 -1.012052 0.014720 -68.753 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4558 on 997 degrees of freedom
#> Multiple R-squared: 0.8523, Adjusted R-squared: 0.852
#> F-statistic: 2876 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[4]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.35017 -0.31473 0.01705 0.31290 1.48762
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.006564 0.014297 0.459 0.646
#> covdata$X1 0.500909 0.014358 34.887 <2e-16 ***
#> covdata$X2 -0.984341 0.014594 -67.447 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4519 on 997 degrees of freedom
#> Multiple R-squared: 0.847, Adjusted R-squared: 0.8466
#> F-statistic: 2759 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[5]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.32389 -0.29827 0.00096 0.31562 1.34122
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.006633 0.014657 0.453 0.651
#> covdata$X1 0.510077 0.014720 34.651 <2e-16 ***
#> covdata$X2 -0.988991 0.014963 -66.098 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4633 on 997 degrees of freedom
#> Multiple R-squared: 0.8424, Adjusted R-squared: 0.842
#> F-statistic: 2664 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[6]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.97282 -0.29641 -0.00372 0.31605 1.50584
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.006802 0.014691 0.463 0.643
#> covdata$X1 0.518111 0.014754 35.117 <2e-16 ***
#> covdata$X2 -0.991622 0.014996 -66.124 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4643 on 997 degrees of freedom
#> Multiple R-squared: 0.8432, Adjusted R-squared: 0.8428
#> F-statistic: 2680 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[7]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.60839 -0.33670 0.00625 0.31283 1.54950
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -0.01836 0.01451 -1.265 0.206
#> covdata$X1 0.51820 0.01458 35.554 <2e-16 ***
#> covdata$X2 -1.00357 0.01481 -67.741 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4587 on 997 degrees of freedom
#> Multiple R-squared: 0.8488, Adjusted R-squared: 0.8485
#> F-statistic: 2799 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[8]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.32175 -0.32431 0.00085 0.32458 1.47297
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -0.0004909 0.0147258 -0.033 0.973
#> covdata$X1 0.5028177 0.0147890 34.000 <2e-16 ***
#> covdata$X2 -0.9908742 0.0150323 -65.916 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4654 on 997 degrees of freedom
#> Multiple R-squared: 0.8408, Adjusted R-squared: 0.8404
#> F-statistic: 2632 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[9]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.4037 -0.3273 0.0104 0.3006 1.5314
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -0.01576 0.01409 -1.118 0.264
#> covdata$X1 0.52738 0.01415 37.268 <2e-16 ***
#> covdata$X2 -0.98051 0.01438 -68.167 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4454 on 997 degrees of freedom
#> Multiple R-squared: 0.8526, Adjusted R-squared: 0.8523
#> F-statistic: 2883 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[10]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.31797 -0.30127 -0.01976 0.29663 1.75980
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.009382 0.014374 0.653 0.514
#> covdata$X1 0.508881 0.014436 35.252 <2e-16 ***
#> covdata$X2 -0.999708 0.014673 -68.132 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4543 on 997 degrees of freedom
#> Multiple R-squared: 0.8496, Adjusted R-squared: 0.8493
#> F-statistic: 2815 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
# compute Rubin's multiple imputation average
par <- lapply(so, function(x) x$coefficients[, 'Estimate'])
SEpar <- lapply(so, function(x) x$coefficients[, 'Std. Error'])
averageMI(par, SEpar)
#> par SEpar t df p
#> (Intercept) 0.000 0.018 0.011 80.28 0.248
#> covdata$X1 0.513 0.017 30.572 143.494 0
#> covdata$X2 -0.998 0.020 -49.932 43.858 0
############
# Example using Gauss-Hermite quadrature with custom input functions
library(fastGHQuad)
#> Loading required package: Rcpp
data(SAT12)
data <- key2binary(SAT12,
key = c(1,4,5,2,3,1,2,1,3,1,2,4,2,1,5,3,4,4,1,4,3,3,4,1,3,5,1,3,1,5,4,5))
GH <- gaussHermiteData(50)
Theta <- matrix(GH$x)
# This prior works for uni- and multi-dimensional models
prior <- function(Theta, Etable){
P <- grid <- GH$w / sqrt(pi)
if(ncol(Theta) > 1)
for(i in 2:ncol(Theta))
P <- expand.grid(P, grid)
if(!is.vector(P)) P <- apply(P, 1, prod)
P
}
GHmod1 <- mirt(data, 1, optimizer = 'NR',
technical = list(customTheta = Theta, customPriorFun = prior))
coef(GHmod1, simplify=TRUE)
#> $items
#> a1 d g u
#> Item.1 1.147 -1.042 0 1
#> Item.2 2.114 0.442 0 1
#> Item.3 1.523 -1.120 0 1
#> Item.4 0.815 -0.517 0 1
#> Item.5 1.392 0.610 0 1
#> Item.6 1.627 -2.051 0 1
#> Item.7 1.418 1.389 0 1
#> Item.8 0.967 -1.501 0 1
#> Item.9 0.753 2.143 0 1
#> Item.10 1.410 -0.355 0 1
#> Item.11 2.494 5.283 0 1
#> Item.12 0.223 -0.331 0 1
#> Item.13 1.569 0.853 0 1
#> Item.14 1.457 1.184 0 1
#> Item.15 1.792 1.917 0 1
#> Item.16 1.016 -0.379 0 1
#> Item.17 2.211 4.176 0 1
#> Item.18 2.420 -0.849 0 1
#> Item.19 1.195 0.238 0 1
#> Item.20 2.182 2.631 0 1
#> Item.21 0.919 2.559 0 1
#> Item.22 2.183 3.481 0 1
#> Item.23 0.900 -0.843 0 1
#> Item.24 1.681 1.266 0 1
#> Item.25 1.082 -0.552 0 1
#> Item.26 2.158 -0.170 0 1
#> Item.27 2.743 2.813 0 1
#> Item.28 1.492 0.183 0 1
#> Item.29 1.176 -0.738 0 1
#> Item.30 0.535 -0.231 0 1
#> Item.31 3.307 2.792 0 1
#> Item.32 0.163 -1.638 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1
#>
Theta2 <- as.matrix(expand.grid(Theta, Theta))
GHmod2 <- mirt(data, 2, optimizer = 'NR', TOL = .0002,
technical = list(customTheta = Theta2, customPriorFun = prior))
summary(GHmod2, suppress=.2)
#>
#> Rotation: oblimin
#>
#> Rotated factor loadings:
#>
#> F1 F2 h2
#> Item.1 0.585 0.34969
#> Item.2 0.328 0.543 0.60987
#> Item.3 0.366 0.387 0.44761
#> Item.4 0.583 0.26862
#> Item.5 0.235 0.472 0.40648
#> Item.6 0.619 0.49035
#> Item.7 0.865 0.60276
#> Item.8 0.390 0.24233
#> Item.9 0.627 0.29129
#> Item.10 0.533 0.44344
#> Item.11 0.702 0.68751
#> Item.12 -0.233 0.355 0.08425
#> Item.13 0.602 0.49900
#> Item.14 0.719 0.51672
#> Item.15 0.800 0.62384
#> Item.16 0.554 0.30530
#> Item.17 0.589 0.290 0.62909
#> Item.18 0.459 0.462 0.67035
#> Item.19 0.229 0.413 0.33189
#> Item.20 0.361 0.526 0.62724
#> Item.21 0.690 0.35960
#> Item.22 0.572 0.301 0.61706
#> Item.23 -0.216 0.691 0.35086
#> Item.24 0.614 0.52605
#> Item.25 0.721 0.40698
#> Item.26 0.691 0.64288
#> Item.27 0.644 0.299 0.72800
#> Item.28 0.300 0.439 0.43595
#> Item.29 0.632 0.37855
#> Item.30 0.267 0.10193
#> Item.31 0.391 0.608 0.79738
#> Item.32 0.00983
#>
#> Rotated SS loadings: 6.085 6.436
#>
#> Factor correlations:
#>
#> F1 F2
#> F1 1.000
#> F2 0.581 1
############
# Davidian curve example
dat <- key2binary(SAT12,
key = c(1,4,5,2,3,1,2,1,3,1,2,4,2,1,5,3,4,4,1,4,3,3,4,1,3,5,1,3,1,5,4,5))
dav <- mirt(dat, 1, dentype = 'Davidian-4') # use four smoothing parameters
plot(dav, type = 'Davidian') # shape of latent trait distribution
#####
# non-linear parameter constraints with Rsolnp package (nloptr supported as well):
# Find Rasch model subject to the constraint that the intercepts sum to 0
dat <- expand.table(LSAT6)
itemstats(dat)
#> $overall
#> N mean_total.score sd_total.score ave.r sd.r alpha SEM.alpha
#> 1000 3.819 1.035 0.077 0.03 0.295 0.869
#>
#> $itemstats
#> N mean sd total.r total.r_if_rm alpha_if_rm
#> Item_1 1000 0.924 0.265 0.362 0.113 0.275
#> Item_2 1000 0.709 0.454 0.567 0.153 0.238
#> Item_3 1000 0.553 0.497 0.618 0.173 0.217
#> Item_4 1000 0.763 0.425 0.534 0.144 0.246
#> Item_5 1000 0.870 0.336 0.435 0.122 0.266
#>
#> $proportions
#> 0 1
#> Item_1 0.076 0.924
#> Item_2 0.291 0.709
#> Item_3 0.447 0.553
#> Item_4 0.237 0.763
#> Item_5 0.130 0.870
#>
# free latent mean and variance terms
model <- 'Theta = 1-5
MEAN = Theta
COV = Theta*Theta'
# view how vector of parameters is organized internally
sv <- mirt(dat, model, itemtype = 'Rasch', pars = 'values')
sv[sv$est, ]
#> group item class name parnum value lbound ubound est const nconst
#> 2 all Item_1 dich d 2 2.815 -Inf Inf TRUE none none
#> 6 all Item_2 dich d 6 1.082 -Inf Inf TRUE none none
#> 10 all Item_3 dich d 10 0.262 -Inf Inf TRUE none none
#> 14 all Item_4 dich d 14 1.407 -Inf Inf TRUE none none
#> 18 all Item_5 dich d 18 2.214 -Inf Inf TRUE none none
#> 21 all GROUP GroupPars MEAN_1 21 0.000 -Inf Inf TRUE none none
#> 22 all GROUP GroupPars COV_11 22 1.000 0 Inf TRUE none none
#> prior.type prior_1 prior_2
#> 2 none NaN NaN
#> 6 none NaN NaN
#> 10 none NaN NaN
#> 14 none NaN NaN
#> 18 none NaN NaN
#> 21 none NaN NaN
#> 22 none NaN NaN
# constraint: create function for solnp to compute constraint, and declare value in eqB
eqfun <- function(p, optim_args) sum(p[1:5]) #could use browser() here, if it helps
LB <- c(rep(-15, 6), 1e-4) # more reasonable lower bound for variance term
mod <- mirt(dat, model, sv=sv, itemtype = 'Rasch', optimizer = 'solnp',
solnp_args=list(eqfun=eqfun, eqB=0, LB=LB))
print(mod)
#>
#> Call:
#> mirt(data = dat, model = model, itemtype = "Rasch", optimizer = "solnp",
#> solnp_args = list(eqfun = eqfun, eqB = 0, LB = LB), sv = sv)
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 34 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: solnp
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -2466.943
#> Estimated parameters: 7
#> AIC = 4947.887
#> BIC = 4982.241; SABIC = 4960.009
#> G2 (25) = 21.81, p = 0.6467
#> RMSEA = 0, CFI = NaN, TLI = NaN
coef(mod)
#> $Item_1
#> a1 d g u
#> par 1 1.253 0 1
#>
#> $Item_2
#> a1 d g u
#> par 1 -0.475 0 1
#>
#> $Item_3
#> a1 d g u
#> par 1 -1.233 0 1
#>
#> $Item_4
#> a1 d g u
#> par 1 -0.168 0 1
#>
#> $Item_5
#> a1 d g u
#> par 1 0.623 0 1
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 1.472 0.559
#>
(ds <- sapply(coef(mod)[1:5], function(x) x[,'d']))
#> Item_1 Item_2 Item_3 Item_4 Item_5
#> 1.2529541 -0.4754463 -1.2327297 -0.1681700 0.6233919
sum(ds)
#> [1] 4.607426e-15
# same likelihood location as: mirt(dat, 1, itemtype = 'Rasch')
#######
# latent regression Rasch model
# simulate data
set.seed(1234)
N <- 1000
# covariates
X1 <- rnorm(N); X2 <- rnorm(N)
covdata <- data.frame(X1, X2, X3 = rnorm(N))
Theta <- matrix(0.5 * X1 + -1 * X2 + rnorm(N, sd = 0.5))
# items and response data
a <- matrix(1, 20); d <- matrix(rnorm(20))
dat <- simdata(a, d, 1000, itemtype = '2PL', Theta=Theta)
# unconditional Rasch model
mod0 <- mirt(dat, 1, 'Rasch', SE=TRUE)
coef(mod0, printSE=TRUE)
#> $Item_1
#> a1 d logit(g) logit(u)
#> par 1 -0.998 -999 999
#> SE NA 0.085 NA NA
#>
#> $Item_2
#> a1 d logit(g) logit(u)
#> par 1 -0.917 -999 999
#> SE NA 0.085 NA NA
#>
#> $Item_3
#> a1 d logit(g) logit(u)
#> par 1 -0.100 -999 999
#> SE NA 0.081 NA NA
#>
#> $Item_4
#> a1 d logit(g) logit(u)
#> par 1 1.893 -999 999
#> SE NA 0.099 NA NA
#>
#> $Item_5
#> a1 d logit(g) logit(u)
#> par 1 0.609 -999 999
#> SE NA 0.082 NA NA
#>
#> $Item_6
#> a1 d logit(g) logit(u)
#> par 1 1.071 -999 999
#> SE NA 0.086 NA NA
#>
#> $Item_7
#> a1 d logit(g) logit(u)
#> par 1 -0.074 -999 999
#> SE NA 0.081 NA NA
#>
#> $Item_8
#> a1 d logit(g) logit(u)
#> par 1 -1.405 -999 999
#> SE NA 0.090 NA NA
#>
#> $Item_9
#> a1 d logit(g) logit(u)
#> par 1 0.707 -999 999
#> SE NA 0.083 NA NA
#>
#> $Item_10
#> a1 d logit(g) logit(u)
#> par 1 -0.258 -999 999
#> SE NA 0.081 NA NA
#>
#> $Item_11
#> a1 d logit(g) logit(u)
#> par 1 0.336 -999 999
#> SE NA 0.081 NA NA
#>
#> $Item_12
#> a1 d logit(g) logit(u)
#> par 1 0.891 -999 999
#> SE NA 0.084 NA NA
#>
#> $Item_13
#> a1 d logit(g) logit(u)
#> par 1 0.653 -999 999
#> SE NA 0.083 NA NA
#>
#> $Item_14
#> a1 d logit(g) logit(u)
#> par 1 -1.942 -999 999
#> SE NA 0.099 NA NA
#>
#> $Item_15
#> a1 d logit(g) logit(u)
#> par 1 -2.143 -999 999
#> SE NA 0.104 NA NA
#>
#> $Item_16
#> a1 d logit(g) logit(u)
#> par 1 1.758 -999 999
#> SE NA 0.096 NA NA
#>
#> $Item_17
#> a1 d logit(g) logit(u)
#> par 1 -1.015 -999 999
#> SE NA 0.085 NA NA
#>
#> $Item_18
#> a1 d logit(g) logit(u)
#> par 1 -1.009 -999 999
#> SE NA 0.085 NA NA
#>
#> $Item_19
#> a1 d logit(g) logit(u)
#> par 1 -1.251 -999 999
#> SE NA 0.088 NA NA
#>
#> $Item_20
#> a1 d logit(g) logit(u)
#> par 1 -0.620 -999 999
#> SE NA 0.082 NA NA
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1.393
#> SE NA 0.085
#>
# conditional model using X1, X2, and X3 (bad) as predictors of Theta
mod1 <- mirt(dat, 1, 'Rasch', covdata=covdata, formula = ~ X1 + X2 + X3, SE=TRUE)
coef(mod1, printSE=TRUE)
#> $Item_1
#> a1 d logit(g) logit(u)
#> par 1 -0.967 -999 999
#> SE NA 0.078 NA NA
#>
#> $Item_2
#> a1 d logit(g) logit(u)
#> par 1 -0.887 -999 999
#> SE NA 0.077 NA NA
#>
#> $Item_3
#> a1 d logit(g) logit(u)
#> par 1 -0.068 -999 999
#> SE NA 0.073 NA NA
#>
#> $Item_4
#> a1 d logit(g) logit(u)
#> par 1 1.920 -999 999
#> SE NA 0.092 NA NA
#>
#> $Item_5
#> a1 d logit(g) logit(u)
#> par 1 0.640 -999 999
#> SE NA 0.075 NA NA
#>
#> $Item_6
#> a1 d logit(g) logit(u)
#> par 1 1.100 -999 999
#> SE NA 0.079 NA NA
#>
#> $Item_7
#> a1 d logit(g) logit(u)
#> par 1 -0.043 -999 999
#> SE NA 0.073 NA NA
#>
#> $Item_8
#> a1 d logit(g) logit(u)
#> par 1 -1.375 -999 999
#> SE NA 0.083 NA NA
#>
#> $Item_9
#> a1 d logit(g) logit(u)
#> par 1 0.737 -999 999
#> SE NA 0.076 NA NA
#>
#> $Item_10
#> a1 d logit(g) logit(u)
#> par 1 -0.227 -999 999
#> SE NA 0.073 NA NA
#>
#> $Item_11
#> a1 d logit(g) logit(u)
#> par 1 0.367 -999 999
#> SE NA 0.074 NA NA
#>
#> $Item_12
#> a1 d logit(g) logit(u)
#> par 1 0.921 -999 999
#> SE NA 0.077 NA NA
#>
#> $Item_13
#> a1 d logit(g) logit(u)
#> par 1 0.683 -999 999
#> SE NA 0.075 NA NA
#>
#> $Item_14
#> a1 d logit(g) logit(u)
#> par 1 -1.913 -999 999
#> SE NA 0.093 NA NA
#>
#> $Item_15
#> a1 d logit(g) logit(u)
#> par 1 -2.114 -999 999
#> SE NA 0.098 NA NA
#>
#> $Item_16
#> a1 d logit(g) logit(u)
#> par 1 1.786 -999 999
#> SE NA 0.090 NA NA
#>
#> $Item_17
#> a1 d logit(g) logit(u)
#> par 1 -0.985 -999 999
#> SE NA 0.078 NA NA
#>
#> $Item_18
#> a1 d logit(g) logit(u)
#> par 1 -0.979 -999 999
#> SE NA 0.078 NA NA
#>
#> $Item_19
#> a1 d logit(g) logit(u)
#> par 1 -1.221 -999 999
#> SE NA 0.081 NA NA
#>
#> $Item_20
#> a1 d logit(g) logit(u)
#> par 1 -0.589 -999 999
#> SE NA 0.075 NA NA
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 0.210
#> SE NA 0.011
#>
#> $lr.betas
#> $lr.betas$betas
#> F1
#> (Intercept) 0.000
#> X1 0.513
#> X2 -1.003
#> X3 -0.003
#>
#> $lr.betas$SE
#> F1
#> (Intercept) NA
#> X1 0.015
#> X2 0.015
#> X3 0.014
#>
#>
coef(mod1, simplify=TRUE)
#> $items
#> a1 d g u
#> Item_1 1 -0.967 0 1
#> Item_2 1 -0.887 0 1
#> Item_3 1 -0.068 0 1
#> Item_4 1 1.920 0 1
#> Item_5 1 0.640 0 1
#> Item_6 1 1.100 0 1
#> Item_7 1 -0.043 0 1
#> Item_8 1 -1.375 0 1
#> Item_9 1 0.737 0 1
#> Item_10 1 -0.227 0 1
#> Item_11 1 0.367 0 1
#> Item_12 1 0.921 0 1
#> Item_13 1 0.683 0 1
#> Item_14 1 -1.913 0 1
#> Item_15 1 -2.114 0 1
#> Item_16 1 1.786 0 1
#> Item_17 1 -0.985 0 1
#> Item_18 1 -0.979 0 1
#> Item_19 1 -1.221 0 1
#> Item_20 1 -0.589 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 0.21
#>
#> $lr.betas
#> $lr.betas$betas
#> F1
#> (Intercept) 0.000
#> X1 0.513
#> X2 -1.003
#> X3 -0.003
#>
#> $lr.betas$CI_2.5
#> F1
#> (Intercept) NA
#> X1 0.485
#> X2 -1.032
#> X3 -0.031
#>
#> $lr.betas$CI_97.5
#> F1
#> (Intercept) NA
#> X1 0.542
#> X2 -0.974
#> X3 0.025
#>
#>
anova(mod0, mod1) # jointly significant predictors of theta
#> AIC SABIC HQ BIC logLik X2 df p
#> mod0 21935.46 21971.83 21974.63 22038.53 -10946.73
#> mod1 20756.61 20798.17 20801.38 20874.40 -10354.31 1184.851 3 0
# large sample z-ratios and p-values (if one cares)
cfs <- coef(mod1, printSE=TRUE)
(z <- cfs$lr.betas[[1]] / cfs$lr.betas[[2]])
#> F1
#> (Intercept) NA
#> X1 35.266840
#> X2 -67.584691
#> X3 -0.211456
round(pnorm(abs(z[,1]), lower.tail=FALSE)*2, 3)
#> (Intercept) X1 X2 X3
#> NA 0.000 0.000 0.833
# drop predictor for nested comparison
mod1b <- mirt(dat, 1, 'Rasch', covdata=covdata, formula = ~ X1 + X2)
anova(mod1b, mod1)
#> AIC SABIC HQ BIC logLik X2 df p
#> mod1b 20754.63 20794.46 20797.53 20867.51 -10354.32
#> mod1 20756.61 20798.17 20801.38 20874.40 -10354.31 0.018 1 0.893
# compare to mixedmirt() version of the same model
mod1.mixed <- mixedmirt(dat, 1, itemtype='Rasch',
covdata=covdata, lr.fixed = ~ X1 + X2 + X3, SE=TRUE)
coef(mod1.mixed)
#> $Item_1
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_2
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_3
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_4
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_5
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_6
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_7
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_8
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_9
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_10
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_11
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_12
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_13
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_14
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_15
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_16
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_17
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_18
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_19
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $Item_20
#> (Intercept) a1 d g u
#> par -0.131 1 0 0 1
#> CI_2.5 -0.166 NA NA NA NA
#> CI_97.5 -0.097 NA NA NA NA
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 0.087
#> CI_2.5 NA 0.068
#> CI_97.5 NA 0.105
#>
#> $lr.betas
#> F1_(Intercept) F1_X1 F1_X2 F1_X3
#> par 0 0.409 -0.795 -0.007
#> CI_2.5 NA 0.376 -0.837 -0.040
#> CI_97.5 NA 0.441 -0.753 0.027
#>
coef(mod1.mixed, printSE=TRUE)
#> $Item_1
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_2
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_3
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_4
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_5
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_6
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_7
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_8
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_9
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_10
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_11
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_12
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_13
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_14
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_15
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_16
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_17
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_18
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_19
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $Item_20
#> (Intercept) a1 d g u
#> par -0.131 1 0 -999 999
#> SE 0.018 NA NA NA NA
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 0.087
#> SE NA 0.009
#>
#> $lr.betas
#> F1_(Intercept) F1_X1 F1_X2 F1_X3
#> par 0 0.409 -0.795 -0.007
#> SE NA 0.016 0.021 0.017
#>
# draw plausible values for secondary analyses
pv <- fscores(mod1, plausible.draws = 10)
pvmods <- lapply(pv, function(x, covdata) lm(x ~ covdata$X1 + covdata$X2),
covdata=covdata)
# population characteristics recovered well, and can be averaged over
so <- lapply(pvmods, summary)
so
#> [[1]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.3024 -0.3253 -0.0029 0.2943 1.4209
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.002109 0.014512 0.145 0.884
#> covdata$X1 0.512293 0.014574 35.151 <2e-16 ***
#> covdata$X2 -1.021832 0.014814 -68.977 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4587 on 997 degrees of freedom
#> Multiple R-squared: 0.8519, Adjusted R-squared: 0.8517
#> F-statistic: 2869 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[2]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.37892 -0.31265 -0.01041 0.31956 1.32091
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -0.001873 0.014455 -0.13 0.897
#> covdata$X1 0.515384 0.014517 35.50 <2e-16 ***
#> covdata$X2 -1.002085 0.014756 -67.91 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4569 on 997 degrees of freedom
#> Multiple R-squared: 0.8493, Adjusted R-squared: 0.849
#> F-statistic: 2809 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[3]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.26871 -0.30200 -0.01567 0.31489 1.23601
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.006956 0.014420 0.482 0.63
#> covdata$X1 0.519090 0.014482 35.844 <2e-16 ***
#> covdata$X2 -1.012052 0.014720 -68.753 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4558 on 997 degrees of freedom
#> Multiple R-squared: 0.8523, Adjusted R-squared: 0.852
#> F-statistic: 2876 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[4]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.35017 -0.31473 0.01705 0.31290 1.48762
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.006564 0.014297 0.459 0.646
#> covdata$X1 0.500909 0.014358 34.887 <2e-16 ***
#> covdata$X2 -0.984341 0.014594 -67.447 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4519 on 997 degrees of freedom
#> Multiple R-squared: 0.847, Adjusted R-squared: 0.8466
#> F-statistic: 2759 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[5]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.32389 -0.29827 0.00096 0.31562 1.34122
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.006633 0.014657 0.453 0.651
#> covdata$X1 0.510077 0.014720 34.651 <2e-16 ***
#> covdata$X2 -0.988991 0.014963 -66.098 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4633 on 997 degrees of freedom
#> Multiple R-squared: 0.8424, Adjusted R-squared: 0.842
#> F-statistic: 2664 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[6]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.97282 -0.29641 -0.00372 0.31605 1.50584
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.006802 0.014691 0.463 0.643
#> covdata$X1 0.518111 0.014754 35.117 <2e-16 ***
#> covdata$X2 -0.991622 0.014996 -66.124 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4643 on 997 degrees of freedom
#> Multiple R-squared: 0.8432, Adjusted R-squared: 0.8428
#> F-statistic: 2680 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[7]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.60839 -0.33670 0.00625 0.31283 1.54950
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -0.01836 0.01451 -1.265 0.206
#> covdata$X1 0.51820 0.01458 35.554 <2e-16 ***
#> covdata$X2 -1.00357 0.01481 -67.741 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4587 on 997 degrees of freedom
#> Multiple R-squared: 0.8488, Adjusted R-squared: 0.8485
#> F-statistic: 2799 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[8]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.32175 -0.32431 0.00085 0.32458 1.47297
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -0.0004909 0.0147258 -0.033 0.973
#> covdata$X1 0.5028177 0.0147890 34.000 <2e-16 ***
#> covdata$X2 -0.9908742 0.0150323 -65.916 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4654 on 997 degrees of freedom
#> Multiple R-squared: 0.8408, Adjusted R-squared: 0.8404
#> F-statistic: 2632 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[9]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.4037 -0.3273 0.0104 0.3006 1.5314
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -0.01576 0.01409 -1.118 0.264
#> covdata$X1 0.52738 0.01415 37.268 <2e-16 ***
#> covdata$X2 -0.98051 0.01438 -68.167 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4454 on 997 degrees of freedom
#> Multiple R-squared: 0.8526, Adjusted R-squared: 0.8523
#> F-statistic: 2883 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
#> [[10]]
#>
#> Call:
#> lm(formula = x ~ covdata$X1 + covdata$X2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.31797 -0.30127 -0.01976 0.29663 1.75980
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.009382 0.014374 0.653 0.514
#> covdata$X1 0.508881 0.014436 35.252 <2e-16 ***
#> covdata$X2 -0.999708 0.014673 -68.132 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> Residual standard error: 0.4543 on 997 degrees of freedom
#> Multiple R-squared: 0.8496, Adjusted R-squared: 0.8493
#> F-statistic: 2815 on 2 and 997 DF, p-value: < 2.2e-16
#>
#>
# compute Rubin's multiple imputation average
par <- lapply(so, function(x) x$coefficients[, 'Estimate'])
SEpar <- lapply(so, function(x) x$coefficients[, 'Std. Error'])
averageMI(par, SEpar)
#> par SEpar t df p
#> (Intercept) 0.000 0.018 0.011 80.28 0.248
#> covdata$X1 0.513 0.017 30.572 143.494 0
#> covdata$X2 -0.998 0.020 -49.932 43.858 0
############
# Example using Gauss-Hermite quadrature with custom input functions
library(fastGHQuad)
#> Loading required package: Rcpp
data(SAT12)
data <- key2binary(SAT12,
key = c(1,4,5,2,3,1,2,1,3,1,2,4,2,1,5,3,4,4,1,4,3,3,4,1,3,5,1,3,1,5,4,5))
GH <- gaussHermiteData(50)
Theta <- matrix(GH$x)
# This prior works for uni- and multi-dimensional models
prior <- function(Theta, Etable){
P <- grid <- GH$w / sqrt(pi)
if(ncol(Theta) > 1)
for(i in 2:ncol(Theta))
P <- expand.grid(P, grid)
if(!is.vector(P)) P <- apply(P, 1, prod)
P
}
GHmod1 <- mirt(data, 1, optimizer = 'NR',
technical = list(customTheta = Theta, customPriorFun = prior))
coef(GHmod1, simplify=TRUE)
#> $items
#> a1 d g u
#> Item.1 1.147 -1.042 0 1
#> Item.2 2.114 0.442 0 1
#> Item.3 1.523 -1.120 0 1
#> Item.4 0.815 -0.517 0 1
#> Item.5 1.392 0.610 0 1
#> Item.6 1.627 -2.051 0 1
#> Item.7 1.418 1.389 0 1
#> Item.8 0.967 -1.501 0 1
#> Item.9 0.753 2.143 0 1
#> Item.10 1.410 -0.355 0 1
#> Item.11 2.494 5.283 0 1
#> Item.12 0.223 -0.331 0 1
#> Item.13 1.569 0.853 0 1
#> Item.14 1.457 1.184 0 1
#> Item.15 1.792 1.917 0 1
#> Item.16 1.016 -0.379 0 1
#> Item.17 2.211 4.176 0 1
#> Item.18 2.420 -0.849 0 1
#> Item.19 1.195 0.238 0 1
#> Item.20 2.182 2.631 0 1
#> Item.21 0.919 2.559 0 1
#> Item.22 2.183 3.481 0 1
#> Item.23 0.900 -0.843 0 1
#> Item.24 1.681 1.266 0 1
#> Item.25 1.082 -0.552 0 1
#> Item.26 2.158 -0.170 0 1
#> Item.27 2.743 2.813 0 1
#> Item.28 1.492 0.183 0 1
#> Item.29 1.176 -0.738 0 1
#> Item.30 0.535 -0.231 0 1
#> Item.31 3.307 2.792 0 1
#> Item.32 0.163 -1.638 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1
#>
Theta2 <- as.matrix(expand.grid(Theta, Theta))
GHmod2 <- mirt(data, 2, optimizer = 'NR', TOL = .0002,
technical = list(customTheta = Theta2, customPriorFun = prior))
summary(GHmod2, suppress=.2)
#>
#> Rotation: oblimin
#>
#> Rotated factor loadings:
#>
#> F1 F2 h2
#> Item.1 0.585 0.34969
#> Item.2 0.328 0.543 0.60987
#> Item.3 0.366 0.387 0.44761
#> Item.4 0.583 0.26862
#> Item.5 0.235 0.472 0.40648
#> Item.6 0.619 0.49035
#> Item.7 0.865 0.60276
#> Item.8 0.390 0.24233
#> Item.9 0.627 0.29129
#> Item.10 0.533 0.44344
#> Item.11 0.702 0.68751
#> Item.12 -0.233 0.355 0.08425
#> Item.13 0.602 0.49900
#> Item.14 0.719 0.51672
#> Item.15 0.800 0.62384
#> Item.16 0.554 0.30530
#> Item.17 0.589 0.290 0.62909
#> Item.18 0.459 0.462 0.67035
#> Item.19 0.229 0.413 0.33189
#> Item.20 0.361 0.526 0.62724
#> Item.21 0.690 0.35960
#> Item.22 0.572 0.301 0.61706
#> Item.23 -0.216 0.691 0.35086
#> Item.24 0.614 0.52605
#> Item.25 0.721 0.40698
#> Item.26 0.691 0.64288
#> Item.27 0.644 0.299 0.72800
#> Item.28 0.300 0.439 0.43595
#> Item.29 0.632 0.37855
#> Item.30 0.267 0.10193
#> Item.31 0.391 0.608 0.79738
#> Item.32 0.00983
#>
#> Rotated SS loadings: 6.085 6.436
#>
#> Factor correlations:
#>
#> F1 F2
#> F1 1.000
#> F2 0.581 1
############
# Davidian curve example
dat <- key2binary(SAT12,
key = c(1,4,5,2,3,1,2,1,3,1,2,4,2,1,5,3,4,4,1,4,3,3,4,1,3,5,1,3,1,5,4,5))
dav <- mirt(dat, 1, dentype = 'Davidian-4') # use four smoothing parameters
plot(dav, type = 'Davidian') # shape of latent trait distribution
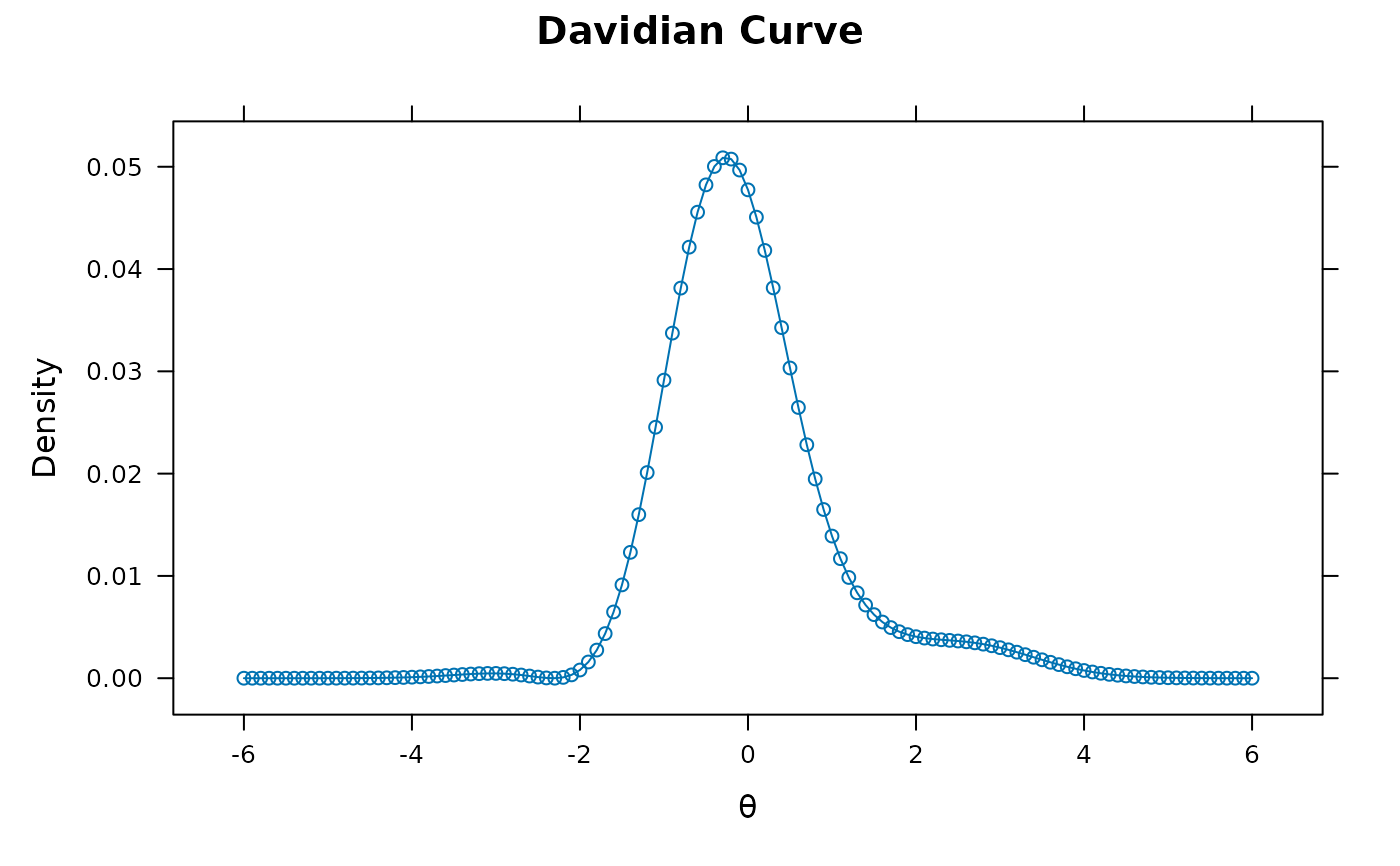 coef(dav, simplify=TRUE)
#> $items
#> a1 d g u
#> Item.1 0.774 -1.048 0 1
#> Item.2 1.684 0.495 0 1
#> Item.3 1.051 -1.114 0 1
#> Item.4 0.582 -0.531 0 1
#> Item.5 1.043 0.613 0 1
#> Item.6 1.037 -2.030 0 1
#> Item.7 1.096 1.397 0 1
#> Item.8 0.639 -1.513 0 1
#> Item.9 0.543 2.128 0 1
#> Item.10 0.993 -0.352 0 1
#> Item.11 2.130 5.453 0 1
#> Item.12 0.163 -0.338 0 1
#> Item.13 1.204 0.867 0 1
#> Item.14 1.171 1.211 0 1
#> Item.15 1.387 1.925 0 1
#> Item.16 0.725 -0.389 0 1
#> Item.17 1.860 4.273 0 1
#> Item.18 1.763 -0.788 0 1
#> Item.19 0.880 0.236 0 1
#> Item.20 1.866 2.743 0 1
#> Item.21 0.695 2.552 0 1
#> Item.22 1.863 3.592 0 1
#> Item.23 0.590 -0.851 0 1
#> Item.24 1.335 1.296 0 1
#> Item.25 0.733 -0.558 0 1
#> Item.26 1.649 -0.125 0 1
#> Item.27 2.356 2.968 0 1
#> Item.28 1.060 0.184 0 1
#> Item.29 0.803 -0.742 0 1
#> Item.30 0.352 -0.241 0 1
#> Item.31 2.944 3.061 0 1
#> Item.32 0.169 -1.651 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1
#>
#> $Davidian_phis
#> [1] 1.289 0.086 -0.444 1.245
#>
fs <- fscores(dav) # assume normal prior
fs2 <- fscores(dav, use_dentype_estimate=TRUE) # use Davidian estimated prior shape
head(cbind(fs, fs2))
#> F1 F1
#> [1,] 2.6681586 3.599628723
#> [2,] 0.1464627 0.070477227
#> [3,] 0.0679956 0.004011929
#> [4,] -0.4157916 -0.426768949
#> [5,] 0.6702426 0.559785683
#> [6,] 0.4547451 0.353798617
itemfit(dav) # assume normal prior
#> Error: Only X2, G2, PV_Q1, PV_Q1*, infit, X2*, and X2*_df can be computed with missing data.
#> Pass na.rm=TRUE to remove missing data row-wise
itemfit(dav, use_dentype_estimate=TRUE) # use Davidian estimated prior shape
#> Error: Only X2, G2, PV_Q1, PV_Q1*, infit, X2*, and X2*_df can be computed with missing data.
#> Pass na.rm=TRUE to remove missing data row-wise
###########
# 5PL and restricted 5PL example
dat <- expand.table(LSAT7)
mod2PL <- mirt(dat)
mod2PL
#>
#> Call:
#> mirt(data = dat)
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 28 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -2658.805
#> Estimated parameters: 10
#> AIC = 5337.61
#> BIC = 5386.688; SABIC = 5354.927
#> G2 (21) = 31.7, p = 0.0628
#> RMSEA = 0.023, CFI = NaN, TLI = NaN
# Following does not converge without including strong priors
# mod5PL <- mirt(dat, itemtype = '5PL')
# mod5PL
# restricted version of 5PL (asymmetric 2PL)
model <- 'Theta = 1-5
FIXED = (1-5, g), (1-5, u)'
mod2PL_asym <- mirt(dat, model=model, itemtype = '5PL')
mod2PL_asym
#>
#> Call:
#> mirt(data = dat, model = model, itemtype = "5PL")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 223 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -2657.877
#> Estimated parameters: 15
#> AIC = 5345.754
#> BIC = 5419.37; SABIC = 5371.729
#> G2 (16) = 29.84, p = 0.0188
#> RMSEA = 0.029, CFI = NaN, TLI = NaN
coef(mod2PL_asym, simplify=TRUE)
#> $items
#> a1 d g u logS
#> Item.1 0.923 2.961 0 1 1.038
#> Item.2 2.276 -1.748 0 1 -1.539
#> Item.3 1.595 2.029 0 1 0.230
#> Item.4 0.609 2.324 0 1 1.614
#> Item.5 0.743 2.027 0 1 0.152
#>
#> $means
#> Theta
#> 0
#>
#> $cov
#> Theta
#> Theta 1
#>
coef(mod2PL_asym, simplify=TRUE, IRTpars=TRUE)
#> $items
#> a b g u S
#> Item.1 0.923 -3.208 0 1 2.824
#> Item.2 2.276 0.768 0 1 0.215
#> Item.3 1.595 -1.272 0 1 1.259
#> Item.4 0.609 -3.817 0 1 5.020
#> Item.5 0.743 -2.728 0 1 1.164
#>
#> $means
#> Theta
#> 0
#>
#> $cov
#> Theta
#> Theta 1
#>
# no big difference statistically or visually
anova(mod2PL, mod2PL_asym)
#> AIC SABIC HQ BIC logLik X2 df p
#> mod2PL 5337.610 5354.927 5356.263 5386.688 -2658.805
#> mod2PL_asym 5345.754 5371.729 5373.733 5419.370 -2657.877 1.857 5 0.869
plot(mod2PL, type = 'trace')
coef(dav, simplify=TRUE)
#> $items
#> a1 d g u
#> Item.1 0.774 -1.048 0 1
#> Item.2 1.684 0.495 0 1
#> Item.3 1.051 -1.114 0 1
#> Item.4 0.582 -0.531 0 1
#> Item.5 1.043 0.613 0 1
#> Item.6 1.037 -2.030 0 1
#> Item.7 1.096 1.397 0 1
#> Item.8 0.639 -1.513 0 1
#> Item.9 0.543 2.128 0 1
#> Item.10 0.993 -0.352 0 1
#> Item.11 2.130 5.453 0 1
#> Item.12 0.163 -0.338 0 1
#> Item.13 1.204 0.867 0 1
#> Item.14 1.171 1.211 0 1
#> Item.15 1.387 1.925 0 1
#> Item.16 0.725 -0.389 0 1
#> Item.17 1.860 4.273 0 1
#> Item.18 1.763 -0.788 0 1
#> Item.19 0.880 0.236 0 1
#> Item.20 1.866 2.743 0 1
#> Item.21 0.695 2.552 0 1
#> Item.22 1.863 3.592 0 1
#> Item.23 0.590 -0.851 0 1
#> Item.24 1.335 1.296 0 1
#> Item.25 0.733 -0.558 0 1
#> Item.26 1.649 -0.125 0 1
#> Item.27 2.356 2.968 0 1
#> Item.28 1.060 0.184 0 1
#> Item.29 0.803 -0.742 0 1
#> Item.30 0.352 -0.241 0 1
#> Item.31 2.944 3.061 0 1
#> Item.32 0.169 -1.651 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1
#>
#> $Davidian_phis
#> [1] 1.289 0.086 -0.444 1.245
#>
fs <- fscores(dav) # assume normal prior
fs2 <- fscores(dav, use_dentype_estimate=TRUE) # use Davidian estimated prior shape
head(cbind(fs, fs2))
#> F1 F1
#> [1,] 2.6681586 3.599628723
#> [2,] 0.1464627 0.070477227
#> [3,] 0.0679956 0.004011929
#> [4,] -0.4157916 -0.426768949
#> [5,] 0.6702426 0.559785683
#> [6,] 0.4547451 0.353798617
itemfit(dav) # assume normal prior
#> Error: Only X2, G2, PV_Q1, PV_Q1*, infit, X2*, and X2*_df can be computed with missing data.
#> Pass na.rm=TRUE to remove missing data row-wise
itemfit(dav, use_dentype_estimate=TRUE) # use Davidian estimated prior shape
#> Error: Only X2, G2, PV_Q1, PV_Q1*, infit, X2*, and X2*_df can be computed with missing data.
#> Pass na.rm=TRUE to remove missing data row-wise
###########
# 5PL and restricted 5PL example
dat <- expand.table(LSAT7)
mod2PL <- mirt(dat)
mod2PL
#>
#> Call:
#> mirt(data = dat)
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 28 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -2658.805
#> Estimated parameters: 10
#> AIC = 5337.61
#> BIC = 5386.688; SABIC = 5354.927
#> G2 (21) = 31.7, p = 0.0628
#> RMSEA = 0.023, CFI = NaN, TLI = NaN
# Following does not converge without including strong priors
# mod5PL <- mirt(dat, itemtype = '5PL')
# mod5PL
# restricted version of 5PL (asymmetric 2PL)
model <- 'Theta = 1-5
FIXED = (1-5, g), (1-5, u)'
mod2PL_asym <- mirt(dat, model=model, itemtype = '5PL')
mod2PL_asym
#>
#> Call:
#> mirt(data = dat, model = model, itemtype = "5PL")
#>
#> Full-information item factor analysis with 1 factor(s).
#> Converged within 1e-04 tolerance after 223 EM iterations.
#> mirt version: 1.43
#> M-step optimizer: BFGS
#> EM acceleration: Ramsay
#> Number of rectangular quadrature: 61
#> Latent density type: Gaussian
#>
#> Log-likelihood = -2657.877
#> Estimated parameters: 15
#> AIC = 5345.754
#> BIC = 5419.37; SABIC = 5371.729
#> G2 (16) = 29.84, p = 0.0188
#> RMSEA = 0.029, CFI = NaN, TLI = NaN
coef(mod2PL_asym, simplify=TRUE)
#> $items
#> a1 d g u logS
#> Item.1 0.923 2.961 0 1 1.038
#> Item.2 2.276 -1.748 0 1 -1.539
#> Item.3 1.595 2.029 0 1 0.230
#> Item.4 0.609 2.324 0 1 1.614
#> Item.5 0.743 2.027 0 1 0.152
#>
#> $means
#> Theta
#> 0
#>
#> $cov
#> Theta
#> Theta 1
#>
coef(mod2PL_asym, simplify=TRUE, IRTpars=TRUE)
#> $items
#> a b g u S
#> Item.1 0.923 -3.208 0 1 2.824
#> Item.2 2.276 0.768 0 1 0.215
#> Item.3 1.595 -1.272 0 1 1.259
#> Item.4 0.609 -3.817 0 1 5.020
#> Item.5 0.743 -2.728 0 1 1.164
#>
#> $means
#> Theta
#> 0
#>
#> $cov
#> Theta
#> Theta 1
#>
# no big difference statistically or visually
anova(mod2PL, mod2PL_asym)
#> AIC SABIC HQ BIC logLik X2 df p
#> mod2PL 5337.610 5354.927 5356.263 5386.688 -2658.805
#> mod2PL_asym 5345.754 5371.729 5373.733 5419.370 -2657.877 1.857 5 0.869
plot(mod2PL, type = 'trace')
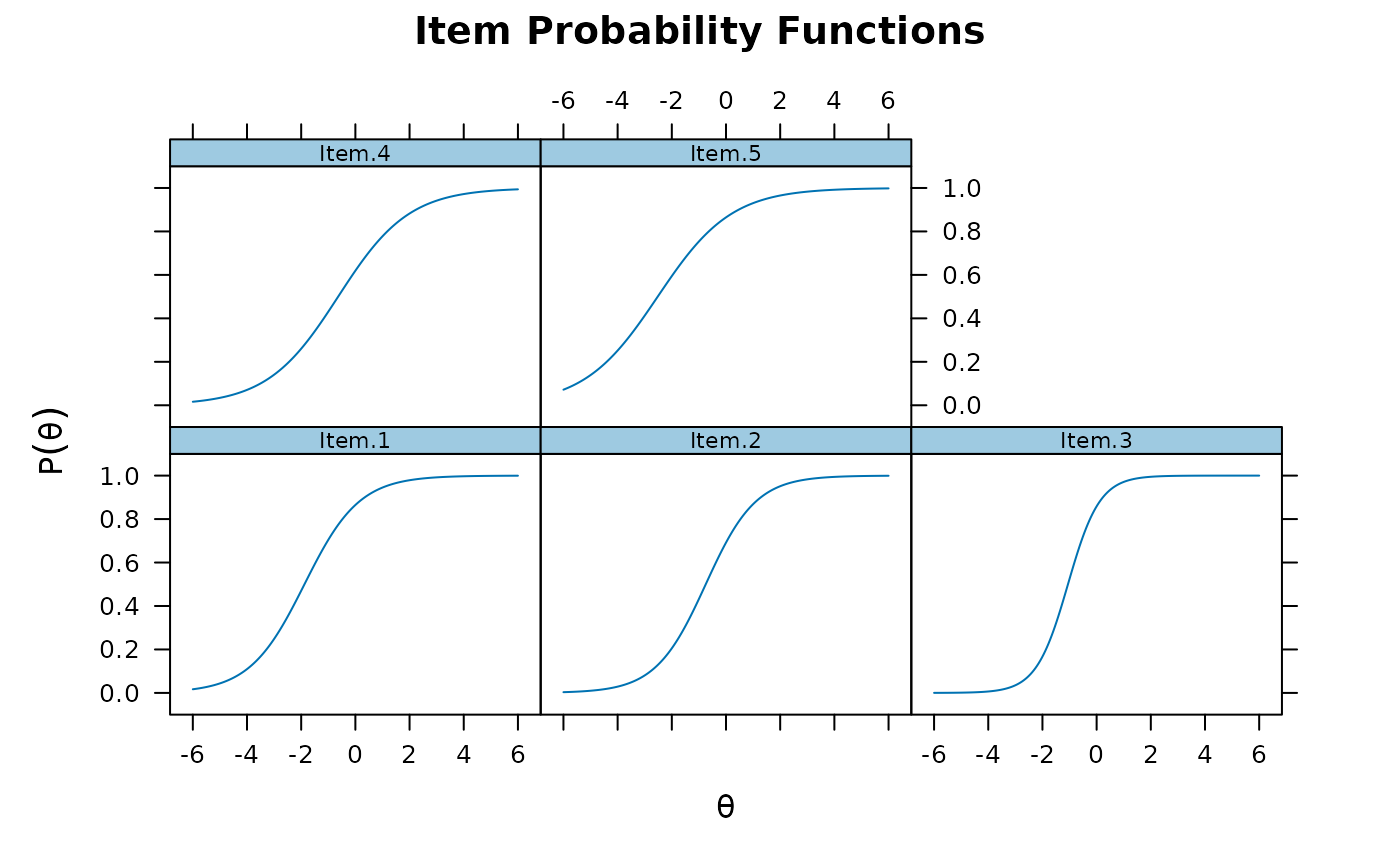 plot(mod2PL_asym, type = 'trace')
plot(mod2PL_asym, type = 'trace')
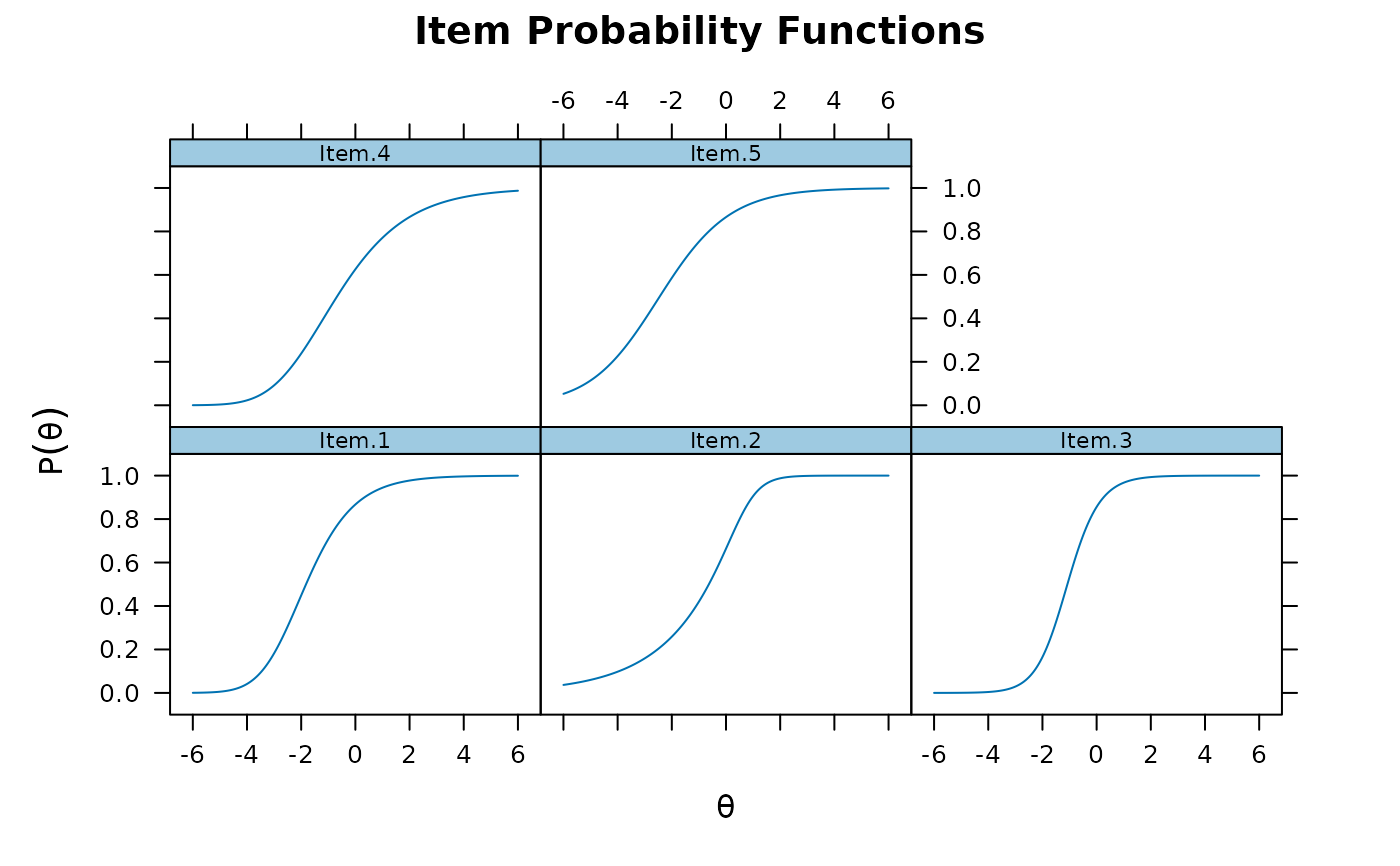 ###################
# LLTM example
a <- matrix(rep(1,30))
d <- rep(c(1,0, -1),each = 10) # first easy, then medium, last difficult
dat <- simdata(a, d, 1000, itemtype = '2PL')
# unconditional model for intercept comparisons
mod <- mirt(dat, itemtype = 'Rasch')
coef(mod, simplify=TRUE)
#> $items
#> a1 d g u
#> Item_1 1 1.040 0 1
#> Item_2 1 0.972 0 1
#> Item_3 1 1.052 0 1
#> Item_4 1 1.058 0 1
#> Item_5 1 0.927 0 1
#> Item_6 1 1.012 0 1
#> Item_7 1 1.092 0 1
#> Item_8 1 1.000 0 1
#> Item_9 1 0.933 0 1
#> Item_10 1 0.872 0 1
#> Item_11 1 0.083 0 1
#> Item_12 1 -0.035 0 1
#> Item_13 1 -0.094 0 1
#> Item_14 1 0.019 0 1
#> Item_15 1 0.063 0 1
#> Item_16 1 0.058 0 1
#> Item_17 1 -0.099 0 1
#> Item_18 1 -0.025 0 1
#> Item_19 1 -0.055 0 1
#> Item_20 1 0.073 0 1
#> Item_21 1 -0.911 0 1
#> Item_22 1 -1.024 0 1
#> Item_23 1 -1.047 0 1
#> Item_24 1 -1.041 0 1
#> Item_25 1 -0.996 0 1
#> Item_26 1 -1.018 0 1
#> Item_27 1 -1.064 0 1
#> Item_28 1 -1.087 0 1
#> Item_29 1 -0.873 0 1
#> Item_30 1 -1.047 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1.107
#>
# Suppose that the first 10 items were suspected to be easy, followed by 10 medium difficulty items,
# then finally the last 10 items are difficult,
# and we wish to test this item structure hypothesis (more intercept designs are possible
# by including more columns).
itemdesign <- data.frame(difficulty =
factor(c(rep('easy', 10), rep('medium', 10), rep('hard', 10))))
rownames(itemdesign) <- colnames(dat)
itemdesign
#> difficulty
#> Item_1 easy
#> Item_2 easy
#> Item_3 easy
#> Item_4 easy
#> Item_5 easy
#> Item_6 easy
#> Item_7 easy
#> Item_8 easy
#> Item_9 easy
#> Item_10 easy
#> Item_11 medium
#> Item_12 medium
#> Item_13 medium
#> Item_14 medium
#> Item_15 medium
#> Item_16 medium
#> Item_17 medium
#> Item_18 medium
#> Item_19 medium
#> Item_20 medium
#> Item_21 hard
#> Item_22 hard
#> Item_23 hard
#> Item_24 hard
#> Item_25 hard
#> Item_26 hard
#> Item_27 hard
#> Item_28 hard
#> Item_29 hard
#> Item_30 hard
# LLTM with mirt()
lltm <- mirt(dat, itemtype = 'Rasch', SE=TRUE,
item.formula = ~ 0 + difficulty, itemdesign=itemdesign)
coef(lltm, simplify=TRUE)
#> $items
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> Item_1 0.995 0.00 0.000 1 0 0 1
#> Item_2 0.995 0.00 0.000 1 0 0 1
#> Item_3 0.995 0.00 0.000 1 0 0 1
#> Item_4 0.995 0.00 0.000 1 0 0 1
#> Item_5 0.995 0.00 0.000 1 0 0 1
#> Item_6 0.995 0.00 0.000 1 0 0 1
#> Item_7 0.995 0.00 0.000 1 0 0 1
#> Item_8 0.995 0.00 0.000 1 0 0 1
#> Item_9 0.995 0.00 0.000 1 0 0 1
#> Item_10 0.995 0.00 0.000 1 0 0 1
#> Item_11 0.000 0.00 -0.001 1 0 0 1
#> Item_12 0.000 0.00 -0.001 1 0 0 1
#> Item_13 0.000 0.00 -0.001 1 0 0 1
#> Item_14 0.000 0.00 -0.001 1 0 0 1
#> Item_15 0.000 0.00 -0.001 1 0 0 1
#> Item_16 0.000 0.00 -0.001 1 0 0 1
#> Item_17 0.000 0.00 -0.001 1 0 0 1
#> Item_18 0.000 0.00 -0.001 1 0 0 1
#> Item_19 0.000 0.00 -0.001 1 0 0 1
#> Item_20 0.000 0.00 -0.001 1 0 0 1
#> Item_21 0.000 -1.01 0.000 1 0 0 1
#> Item_22 0.000 -1.01 0.000 1 0 0 1
#> Item_23 0.000 -1.01 0.000 1 0 0 1
#> Item_24 0.000 -1.01 0.000 1 0 0 1
#> Item_25 0.000 -1.01 0.000 1 0 0 1
#> Item_26 0.000 -1.01 0.000 1 0 0 1
#> Item_27 0.000 -1.01 0.000 1 0 0 1
#> Item_28 0.000 -1.01 0.000 1 0 0 1
#> Item_29 0.000 -1.01 0.000 1 0 0 1
#> Item_30 0.000 -1.01 0.000 1 0 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1.105
#>
coef(lltm, printSE=TRUE)
#> $Item_1
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_2
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_3
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_4
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_5
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_6
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_7
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_8
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_9
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_10
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_11
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_12
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_13
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_14
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_15
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_16
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_17
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_18
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_19
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_20
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_21
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_22
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_23
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_24
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_25
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_26
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_27
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_28
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_29
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_30
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1.105
#> SE NA 0.062
#>
anova(lltm, mod) # models fit effectively the same; hence, intercept variability well captured
#> AIC SABIC HQ BIC logLik X2 df p
#> lltm 34877.79 34884.71 34885.25 34897.42 -17434.89
#> mod 34907.90 34961.58 34965.72 35060.04 -17422.95 23.89 27 0.636
# additional information for LLTM
plot(lltm)
###################
# LLTM example
a <- matrix(rep(1,30))
d <- rep(c(1,0, -1),each = 10) # first easy, then medium, last difficult
dat <- simdata(a, d, 1000, itemtype = '2PL')
# unconditional model for intercept comparisons
mod <- mirt(dat, itemtype = 'Rasch')
coef(mod, simplify=TRUE)
#> $items
#> a1 d g u
#> Item_1 1 1.040 0 1
#> Item_2 1 0.972 0 1
#> Item_3 1 1.052 0 1
#> Item_4 1 1.058 0 1
#> Item_5 1 0.927 0 1
#> Item_6 1 1.012 0 1
#> Item_7 1 1.092 0 1
#> Item_8 1 1.000 0 1
#> Item_9 1 0.933 0 1
#> Item_10 1 0.872 0 1
#> Item_11 1 0.083 0 1
#> Item_12 1 -0.035 0 1
#> Item_13 1 -0.094 0 1
#> Item_14 1 0.019 0 1
#> Item_15 1 0.063 0 1
#> Item_16 1 0.058 0 1
#> Item_17 1 -0.099 0 1
#> Item_18 1 -0.025 0 1
#> Item_19 1 -0.055 0 1
#> Item_20 1 0.073 0 1
#> Item_21 1 -0.911 0 1
#> Item_22 1 -1.024 0 1
#> Item_23 1 -1.047 0 1
#> Item_24 1 -1.041 0 1
#> Item_25 1 -0.996 0 1
#> Item_26 1 -1.018 0 1
#> Item_27 1 -1.064 0 1
#> Item_28 1 -1.087 0 1
#> Item_29 1 -0.873 0 1
#> Item_30 1 -1.047 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1.107
#>
# Suppose that the first 10 items were suspected to be easy, followed by 10 medium difficulty items,
# then finally the last 10 items are difficult,
# and we wish to test this item structure hypothesis (more intercept designs are possible
# by including more columns).
itemdesign <- data.frame(difficulty =
factor(c(rep('easy', 10), rep('medium', 10), rep('hard', 10))))
rownames(itemdesign) <- colnames(dat)
itemdesign
#> difficulty
#> Item_1 easy
#> Item_2 easy
#> Item_3 easy
#> Item_4 easy
#> Item_5 easy
#> Item_6 easy
#> Item_7 easy
#> Item_8 easy
#> Item_9 easy
#> Item_10 easy
#> Item_11 medium
#> Item_12 medium
#> Item_13 medium
#> Item_14 medium
#> Item_15 medium
#> Item_16 medium
#> Item_17 medium
#> Item_18 medium
#> Item_19 medium
#> Item_20 medium
#> Item_21 hard
#> Item_22 hard
#> Item_23 hard
#> Item_24 hard
#> Item_25 hard
#> Item_26 hard
#> Item_27 hard
#> Item_28 hard
#> Item_29 hard
#> Item_30 hard
# LLTM with mirt()
lltm <- mirt(dat, itemtype = 'Rasch', SE=TRUE,
item.formula = ~ 0 + difficulty, itemdesign=itemdesign)
coef(lltm, simplify=TRUE)
#> $items
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> Item_1 0.995 0.00 0.000 1 0 0 1
#> Item_2 0.995 0.00 0.000 1 0 0 1
#> Item_3 0.995 0.00 0.000 1 0 0 1
#> Item_4 0.995 0.00 0.000 1 0 0 1
#> Item_5 0.995 0.00 0.000 1 0 0 1
#> Item_6 0.995 0.00 0.000 1 0 0 1
#> Item_7 0.995 0.00 0.000 1 0 0 1
#> Item_8 0.995 0.00 0.000 1 0 0 1
#> Item_9 0.995 0.00 0.000 1 0 0 1
#> Item_10 0.995 0.00 0.000 1 0 0 1
#> Item_11 0.000 0.00 -0.001 1 0 0 1
#> Item_12 0.000 0.00 -0.001 1 0 0 1
#> Item_13 0.000 0.00 -0.001 1 0 0 1
#> Item_14 0.000 0.00 -0.001 1 0 0 1
#> Item_15 0.000 0.00 -0.001 1 0 0 1
#> Item_16 0.000 0.00 -0.001 1 0 0 1
#> Item_17 0.000 0.00 -0.001 1 0 0 1
#> Item_18 0.000 0.00 -0.001 1 0 0 1
#> Item_19 0.000 0.00 -0.001 1 0 0 1
#> Item_20 0.000 0.00 -0.001 1 0 0 1
#> Item_21 0.000 -1.01 0.000 1 0 0 1
#> Item_22 0.000 -1.01 0.000 1 0 0 1
#> Item_23 0.000 -1.01 0.000 1 0 0 1
#> Item_24 0.000 -1.01 0.000 1 0 0 1
#> Item_25 0.000 -1.01 0.000 1 0 0 1
#> Item_26 0.000 -1.01 0.000 1 0 0 1
#> Item_27 0.000 -1.01 0.000 1 0 0 1
#> Item_28 0.000 -1.01 0.000 1 0 0 1
#> Item_29 0.000 -1.01 0.000 1 0 0 1
#> Item_30 0.000 -1.01 0.000 1 0 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1.105
#>
coef(lltm, printSE=TRUE)
#> $Item_1
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_2
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_3
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_4
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_5
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_6
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_7
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_8
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_9
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_10
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_11
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_12
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_13
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_14
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_15
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_16
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_17
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_18
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_19
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_20
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_21
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_22
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_23
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_24
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_25
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_26
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_27
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_28
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_29
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $Item_30
#> difficultyeasy difficultyhard difficultymedium a1 d logit(g) logit(u)
#> par 0.995 -1.010 -0.001 1 0 -999 999
#> SE 0.041 0.041 0.040 NA NA NA NA
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1.105
#> SE NA 0.062
#>
anova(lltm, mod) # models fit effectively the same; hence, intercept variability well captured
#> AIC SABIC HQ BIC logLik X2 df p
#> lltm 34877.79 34884.71 34885.25 34897.42 -17434.89
#> mod 34907.90 34961.58 34965.72 35060.04 -17422.95 23.89 27 0.636
# additional information for LLTM
plot(lltm)
 plot(lltm, type = 'trace')
plot(lltm, type = 'trace')
 itemplot(lltm, item=1)
itemplot(lltm, item=1)
 itemfit(lltm)
#> item S_X2 df.S_X2 RMSEA.S_X2 p.S_X2
#> 1 Item_1 18.506 21 0.000 0.617
#> 2 Item_2 24.007 21 0.012 0.293
#> 3 Item_3 17.975 21 0.000 0.651
#> 4 Item_4 19.815 21 0.000 0.533
#> 5 Item_5 31.211 21 0.022 0.070
#> 6 Item_6 36.118 21 0.027 0.021
#> 7 Item_7 30.097 21 0.021 0.090
#> 8 Item_8 14.926 21 0.000 0.827
#> 9 Item_9 24.846 21 0.014 0.254
#> 10 Item_10 20.420 21 0.000 0.495
#> 11 Item_11 26.435 21 0.016 0.190
#> 12 Item_12 30.628 21 0.021 0.080
#> 13 Item_13 26.631 21 0.016 0.183
#> 14 Item_14 21.262 21 0.004 0.443
#> 15 Item_15 26.837 21 0.017 0.176
#> 16 Item_16 33.290 21 0.024 0.043
#> 17 Item_17 20.076 21 0.000 0.516
#> 18 Item_18 33.049 21 0.024 0.046
#> 19 Item_19 37.018 21 0.028 0.017
#> 20 Item_20 29.165 21 0.020 0.110
#> 21 Item_21 27.093 21 0.017 0.168
#> 22 Item_22 23.511 21 0.011 0.317
#> 23 Item_23 26.528 21 0.016 0.187
#> 24 Item_24 21.415 21 0.004 0.434
#> 25 Item_25 27.944 21 0.018 0.142
#> 26 Item_26 29.322 21 0.020 0.106
#> 27 Item_27 25.752 21 0.015 0.216
#> 28 Item_28 20.106 21 0.000 0.515
#> 29 Item_29 28.544 21 0.019 0.125
#> 30 Item_30 25.486 21 0.015 0.227
head(fscores(lltm)) #EAP estimates
#> F1
#> [1,] -0.7060943
#> [2,] 0.8657140
#> [3,] 1.3579909
#> [4,] 0.2830462
#> [5,] -0.7060943
#> [6,] -0.2745315
fscores(lltm, method='EAPsum', full.scores=FALSE)
#> df X2 p.X2 SEM.alpha rxx.alpha rxx_F1
#> stats 30 22.651 0.829 2.366 0.86 0.856
#>
#> Sum.Scores F1 SE_F1 observed expected std.res
#> 0 0 -2.775 0.585 2 1.566 0.347
#> 1 1 -2.459 0.540 3 4.670 0.773
#> 2 2 -2.187 0.505 13 8.859 1.391
#> 3 3 -1.947 0.477 11 13.703 0.730
#> 4 4 -1.731 0.454 13 18.875 1.352
#> 5 5 -1.533 0.436 33 24.133 1.805
#> 6 6 -1.349 0.421 28 29.298 0.240
#> 7 7 -1.177 0.409 35 34.229 0.132
#> 8 8 -1.014 0.400 36 38.814 0.452
#> 9 9 -0.857 0.392 45 42.962 0.311
#> 10 10 -0.706 0.386 53 46.594 0.938
#> 11 11 -0.559 0.381 45 49.648 0.660
#> 12 12 -0.416 0.377 46 52.070 0.841
#> 13 13 -0.275 0.375 55 53.820 0.161
#> 14 14 -0.135 0.373 51 54.870 0.522
#> 15 15 0.004 0.373 52 55.202 0.431
#> 16 16 0.143 0.373 64 54.810 1.241
#> 17 17 0.283 0.375 47 53.703 0.915
#> 18 18 0.424 0.377 48 51.897 0.541
#> 19 19 0.568 0.381 60 49.424 1.504
#> 20 20 0.715 0.386 55 46.325 1.275
#> 21 21 0.866 0.392 36 42.655 1.019
#> 22 22 1.022 0.400 34 38.479 0.722
#> 23 23 1.186 0.409 37 33.878 0.536
#> 24 24 1.358 0.421 25 28.946 0.733
#> 25 25 1.541 0.436 24 23.797 0.042
#> 26 26 1.739 0.454 19 18.572 0.099
#> 27 27 1.955 0.476 17 13.450 0.968
#> 28 28 2.195 0.505 9 8.672 0.111
#> 29 29 2.467 0.540 4 4.557 0.261
#> 30 30 2.783 0.585 0 1.522 1.234
M2(lltm) # goodness of fit
#> M2 df p RMSEA RMSEA_5 RMSEA_95 SRMSR TLI CFI
#> stats 452.9984 461 0.5960236 0 0 0.009921769 0.02960249 1.000596 1
head(personfit(lltm))
#> outfit z.outfit infit z.infit Zh
#> 1 0.9556985 -0.13140309 0.9958807 0.02853420 0.08783112
#> 2 0.6399788 -1.61120831 0.7395941 -1.60495288 1.50441490
#> 3 1.0131241 0.15347265 0.9762310 -0.03209238 0.05424258
#> 4 0.9803474 -0.06312702 0.9532372 -0.27742936 0.25248909
#> 5 0.8274978 -0.76177996 0.9361313 -0.34897186 0.53387552
#> 6 1.0753664 0.49629111 1.0226248 0.20290036 -0.25664723
residuals(lltm)
#> LD matrix (lower triangle) and standardized residual correlations (upper triangle)
#>
#> Upper triangle summary:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> -0.111 -0.043 0.010 0.000 0.044 0.087
#>
#> Item_1 Item_2 Item_3 Item_4 Item_5 Item_6 Item_7 Item_8 Item_9 Item_10
#> Item_1 -0.055 -0.029 0.036 -0.054 -0.047 -0.043 0.031 0.034 0.057
#> Item_2 3.028 -0.025 -0.035 -0.063 -0.030 0.042 0.010 -0.048 -0.066
#> Item_3 0.831 0.623 -0.037 0.041 0.024 -0.040 0.024 -0.038 -0.063
#> Item_4 1.317 1.258 1.373 -0.045 0.046 0.046 -0.037 0.040 0.059
#> Item_5 2.880 3.933 1.669 2.015 -0.039 -0.050 0.029 -0.033 -0.063
#> Item_6 2.223 0.882 0.557 2.071 1.529 -0.037 0.015 -0.047 0.053
#> Item_7 1.874 1.778 1.632 2.079 2.493 1.334 0.037 0.049 0.071
#> Item_8 0.967 0.096 0.580 1.367 0.861 0.211 1.371 0.033 -0.057
#> Item_9 1.160 2.318 1.435 1.617 1.115 2.203 2.428 1.103 0.064
#> Item_10 3.198 4.415 3.947 3.469 3.968 2.783 5.027 3.221 4.066
#> Item_11 1.491 3.375 1.516 4.216 4.070 1.375 3.159 1.388 2.630 4.209
#> Item_12 0.761 0.549 0.846 2.713 2.611 0.336 4.108 0.724 1.399 2.393
#> Item_13 2.409 5.615 4.394 4.291 5.789 1.583 5.492 2.553 5.388 6.493
#> Item_14 1.000 3.943 0.843 1.093 1.009 0.153 1.443 0.096 0.906 3.835
#> Item_15 1.772 3.339 1.295 1.909 2.053 1.395 2.248 1.903 2.237 5.337
#> Item_16 0.808 1.592 0.899 1.260 3.174 1.680 3.782 1.448 1.685 3.776
#> Item_17 2.228 3.623 2.450 2.519 2.077 2.200 6.248 2.901 2.173 3.412
#> Item_18 0.455 0.379 0.690 2.643 1.998 0.158 1.813 1.881 6.735 2.314
#> Item_19 0.941 0.560 3.048 2.056 1.092 2.901 2.438 0.935 1.052 3.083
#> Item_20 1.489 1.981 1.194 1.432 1.976 0.931 2.047 2.783 1.952 3.887
#> Item_21 1.872 2.079 1.735 3.595 2.563 2.168 5.007 3.018 2.421 4.933
#> Item_22 1.997 1.402 0.569 0.632 0.914 1.153 2.394 0.070 1.688 3.344
#> Item_23 0.600 1.194 1.231 0.863 0.909 0.605 2.419 1.983 2.268 2.485
#> Item_24 0.828 0.387 3.366 1.165 2.867 0.206 1.935 0.596 1.585 2.866
#> Item_25 0.807 2.907 3.086 1.744 1.763 0.233 1.347 0.141 0.684 6.600
#> Item_26 0.386 0.560 1.440 1.090 2.842 0.118 1.417 0.452 1.304 2.514
#> Item_27 0.826 0.946 2.004 1.220 1.351 0.860 2.851 2.535 2.196 3.624
#> Item_28 1.828 1.205 2.519 1.653 7.177 1.837 2.613 1.151 1.258 2.790
#> Item_29 4.096 6.266 3.295 6.489 8.539 7.663 5.249 3.852 4.208 6.685
#> Item_30 0.643 0.472 1.795 2.359 0.812 1.039 3.489 1.126 3.201 2.632
#> Item_11 Item_12 Item_13 Item_14 Item_15 Item_16 Item_17 Item_18 Item_19
#> Item_1 -0.039 -0.028 -0.049 -0.032 0.042 -0.028 -0.047 -0.021 -0.031
#> Item_2 -0.058 -0.023 -0.075 -0.063 -0.058 -0.040 0.060 -0.019 0.024
#> Item_3 0.039 0.029 -0.066 0.029 0.036 -0.030 -0.049 0.026 0.055
#> Item_4 0.065 0.052 -0.066 -0.033 0.044 -0.035 0.050 -0.051 0.045
#> Item_5 -0.064 -0.051 -0.076 0.032 0.045 -0.056 -0.046 -0.045 0.033
#> Item_6 0.037 -0.018 -0.040 -0.012 0.037 -0.041 -0.047 -0.013 0.054
#> Item_7 0.056 -0.064 -0.074 0.038 -0.047 -0.061 -0.079 -0.043 0.049
#> Item_8 -0.037 -0.027 0.051 0.010 0.044 -0.038 -0.054 0.043 0.031
#> Item_9 0.051 -0.037 -0.073 -0.030 0.047 0.041 -0.047 0.082 0.032
#> Item_10 0.065 0.049 -0.081 0.062 -0.073 0.061 -0.058 0.048 0.056
#> Item_11 -0.048 -0.057 -0.038 0.061 0.056 0.081 0.057 0.062
#> Item_12 2.316 -0.038 -0.060 -0.079 -0.055 -0.043 0.015 0.056
#> Item_13 3.195 1.463 0.050 0.087 -0.059 0.062 -0.057 0.042
#> Item_14 1.464 3.594 2.452 0.033 0.033 0.052 -0.014 0.028
#> Item_15 3.763 6.174 7.600 1.112 0.049 0.056 0.043 0.038
#> Item_16 3.153 2.971 3.517 1.099 2.412 0.053 -0.031 -0.064
#> Item_17 6.588 1.883 3.830 2.738 3.151 2.808 0.040 0.042
#> Item_18 3.250 0.239 3.276 0.200 1.829 0.960 1.633 -0.025
#> Item_19 3.797 3.117 1.730 0.768 1.429 4.139 1.790 0.608
#> Item_20 6.815 1.633 3.211 1.004 1.566 1.871 3.301 1.653 4.252
#> Item_21 5.023 2.119 6.746 4.620 3.131 1.837 5.118 3.817 2.478
#> Item_22 1.756 0.974 1.445 2.503 0.795 0.716 1.646 0.540 1.570
#> Item_23 2.409 0.433 1.653 2.052 1.072 1.242 4.312 0.421 1.928
#> Item_24 3.107 0.450 1.842 0.397 1.032 1.103 1.686 0.423 0.595
#> Item_25 1.566 0.392 2.815 1.117 2.916 0.666 5.749 2.929 0.976
#> Item_26 1.319 2.305 1.584 0.095 0.754 0.810 3.788 1.671 0.664
#> Item_27 1.947 2.021 2.064 4.415 1.458 1.360 1.940 1.095 0.749
#> Item_28 3.301 1.489 2.404 4.079 2.132 2.431 2.072 0.854 1.127
#> Item_29 3.547 3.534 5.614 4.690 3.384 4.347 6.474 3.556 3.963
#> Item_30 7.049 12.218 1.979 0.878 3.335 1.428 1.995 1.511 1.349
#> Item_20 Item_21 Item_22 Item_23 Item_24 Item_25 Item_26 Item_27 Item_28
#> Item_1 -0.039 -0.043 -0.045 0.024 -0.029 0.028 -0.020 -0.029 -0.043
#> Item_2 -0.045 0.046 0.037 -0.035 -0.020 0.054 0.024 0.031 -0.035
#> Item_3 -0.035 -0.042 -0.024 -0.035 0.058 0.056 0.038 0.045 0.050
#> Item_4 -0.038 0.060 0.025 -0.029 0.034 0.042 -0.033 0.035 0.041
#> Item_5 0.044 -0.051 0.030 -0.030 -0.054 -0.042 -0.053 -0.037 -0.085
#> Item_6 0.031 0.047 0.034 -0.025 0.014 0.015 0.011 0.029 0.043
#> Item_7 -0.045 0.071 -0.049 0.049 0.044 -0.037 -0.038 -0.053 -0.051
#> Item_8 -0.053 0.055 -0.008 -0.045 0.024 0.012 0.021 -0.050 0.034
#> Item_9 -0.044 0.049 -0.041 0.048 0.040 -0.026 -0.036 -0.047 -0.035
#> Item_10 0.062 -0.070 0.058 0.050 0.054 0.081 -0.050 0.060 0.053
#> Item_11 0.083 0.071 -0.042 -0.049 0.056 0.040 0.036 -0.044 0.057
#> Item_12 0.040 -0.046 0.031 -0.021 -0.021 -0.020 -0.048 -0.045 -0.039
#> Item_13 -0.057 -0.082 -0.038 0.041 0.043 0.053 -0.040 0.045 -0.049
#> Item_14 -0.032 0.068 -0.050 0.045 0.020 0.033 -0.010 -0.066 0.064
#> Item_15 0.040 0.056 0.028 -0.033 -0.032 0.054 -0.027 -0.038 0.046
#> Item_16 0.043 0.043 -0.027 -0.035 -0.033 0.026 -0.028 0.037 -0.049
#> Item_17 0.057 -0.072 -0.041 -0.066 -0.041 0.076 -0.062 0.044 -0.046
#> Item_18 0.041 0.062 0.023 -0.021 0.021 0.054 -0.041 0.033 -0.029
#> Item_19 0.065 0.050 0.040 -0.044 -0.024 0.031 -0.026 -0.027 0.034
#> Item_20 -0.047 -0.032 -0.036 -0.035 0.038 -0.044 0.040 -0.051
#> Item_21 2.208 0.044 0.061 0.044 0.060 0.041 0.050 0.082
#> Item_22 1.033 1.923 0.025 -0.043 0.030 0.018 -0.020 -0.029
#> Item_23 1.309 3.701 0.612 0.034 0.023 0.053 -0.023 -0.031
#> Item_24 1.218 1.893 1.812 1.174 0.024 0.012 -0.033 -0.033
#> Item_25 1.416 3.585 0.884 0.537 0.583 0.023 0.058 0.049
#> Item_26 1.897 1.698 0.309 2.782 0.143 0.545 0.020 0.036
#> Item_27 1.593 2.451 0.413 0.513 1.082 3.400 0.407 -0.036
#> Item_28 2.591 6.768 0.854 0.963 1.058 2.364 1.288 1.328
#> Item_29 3.451 5.900 5.999 4.259 4.562 6.714 3.035 4.346 4.441
#> Item_30 1.636 1.936 0.238 0.824 0.919 1.834 0.388 0.535 4.168
#> Item_29 Item_30
#> Item_1 -0.064 -0.025
#> Item_2 -0.079 -0.022
#> Item_3 -0.057 -0.042
#> Item_4 -0.081 -0.049
#> Item_5 -0.092 0.028
#> Item_6 -0.088 0.032
#> Item_7 -0.072 0.059
#> Item_8 -0.062 0.034
#> Item_9 0.065 0.057
#> Item_10 -0.082 0.051
#> Item_11 0.060 0.084
#> Item_12 -0.059 -0.111
#> Item_13 -0.075 0.044
#> Item_14 0.068 0.030
#> Item_15 -0.058 0.058
#> Item_16 -0.066 0.038
#> Item_17 -0.080 0.045
#> Item_18 -0.060 0.039
#> Item_19 -0.063 -0.037
#> Item_20 0.059 0.040
#> Item_21 0.077 0.044
#> Item_22 -0.077 0.015
#> Item_23 -0.065 0.029
#> Item_24 -0.068 0.030
#> Item_25 0.082 0.043
#> Item_26 0.055 0.020
#> Item_27 -0.066 -0.023
#> Item_28 -0.067 0.065
#> Item_29 0.086
#> Item_30 7.382
# intercept across items also possible by removing ~ 0 portion, just interpreted differently
lltm.int <- mirt(dat, itemtype = 'Rasch',
item.formula = ~ difficulty, itemdesign=itemdesign)
anova(lltm, lltm.int) # same
#> AIC SABIC HQ BIC logLik X2 df p
#> lltm 34877.79 34884.71 34885.25 34897.42 -17434.89
#> lltm.int 34877.79 34884.71 34885.25 34897.42 -17434.89 0 0 NaN
coef(lltm.int, simplify=TRUE)
#> $items
#> (Intercept) difficultyhard difficultymedium a1 d g u
#> Item_1 0.995 0.000 0.000 1 0 0 1
#> Item_2 0.995 0.000 0.000 1 0 0 1
#> Item_3 0.995 0.000 0.000 1 0 0 1
#> Item_4 0.995 0.000 0.000 1 0 0 1
#> Item_5 0.995 0.000 0.000 1 0 0 1
#> Item_6 0.995 0.000 0.000 1 0 0 1
#> Item_7 0.995 0.000 0.000 1 0 0 1
#> Item_8 0.995 0.000 0.000 1 0 0 1
#> Item_9 0.995 0.000 0.000 1 0 0 1
#> Item_10 0.995 0.000 0.000 1 0 0 1
#> Item_11 0.995 0.000 -0.996 1 0 0 1
#> Item_12 0.995 0.000 -0.996 1 0 0 1
#> Item_13 0.995 0.000 -0.996 1 0 0 1
#> Item_14 0.995 0.000 -0.996 1 0 0 1
#> Item_15 0.995 0.000 -0.996 1 0 0 1
#> Item_16 0.995 0.000 -0.996 1 0 0 1
#> Item_17 0.995 0.000 -0.996 1 0 0 1
#> Item_18 0.995 0.000 -0.996 1 0 0 1
#> Item_19 0.995 0.000 -0.996 1 0 0 1
#> Item_20 0.995 0.000 -0.996 1 0 0 1
#> Item_21 0.995 -2.005 0.000 1 0 0 1
#> Item_22 0.995 -2.005 0.000 1 0 0 1
#> Item_23 0.995 -2.005 0.000 1 0 0 1
#> Item_24 0.995 -2.005 0.000 1 0 0 1
#> Item_25 0.995 -2.005 0.000 1 0 0 1
#> Item_26 0.995 -2.005 0.000 1 0 0 1
#> Item_27 0.995 -2.005 0.000 1 0 0 1
#> Item_28 0.995 -2.005 0.000 1 0 0 1
#> Item_29 0.995 -2.005 0.000 1 0 0 1
#> Item_30 0.995 -2.005 0.000 1 0 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1.105
#>
# using unconditional modeling for first four items
itemdesign.sub <- itemdesign[5:nrow(itemdesign), , drop=FALSE]
itemdesign.sub # note that rownames are required in this case
#> difficulty
#> Item_5 easy
#> Item_6 easy
#> Item_7 easy
#> Item_8 easy
#> Item_9 easy
#> Item_10 easy
#> Item_11 medium
#> Item_12 medium
#> Item_13 medium
#> Item_14 medium
#> Item_15 medium
#> Item_16 medium
#> Item_17 medium
#> Item_18 medium
#> Item_19 medium
#> Item_20 medium
#> Item_21 hard
#> Item_22 hard
#> Item_23 hard
#> Item_24 hard
#> Item_25 hard
#> Item_26 hard
#> Item_27 hard
#> Item_28 hard
#> Item_29 hard
#> Item_30 hard
lltm.4 <- mirt(dat, itemtype = 'Rasch',
item.formula = ~ 0 + difficulty, itemdesign=itemdesign.sub)
coef(lltm.4, simplify=TRUE) # first four items are the standard Rasch
#> $items
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> Item_1 0.000 0.00 0.000 1 1.040 0 1
#> Item_2 0.000 0.00 0.000 1 0.972 0 1
#> Item_3 0.000 0.00 0.000 1 1.051 0 1
#> Item_4 0.000 0.00 0.000 1 1.057 0 1
#> Item_5 0.972 0.00 0.000 1 0.000 0 1
#> Item_6 0.972 0.00 0.000 1 0.000 0 1
#> Item_7 0.972 0.00 0.000 1 0.000 0 1
#> Item_8 0.972 0.00 0.000 1 0.000 0 1
#> Item_9 0.972 0.00 0.000 1 0.000 0 1
#> Item_10 0.972 0.00 0.000 1 0.000 0 1
#> Item_11 0.000 0.00 -0.001 1 0.000 0 1
#> Item_12 0.000 0.00 -0.001 1 0.000 0 1
#> Item_13 0.000 0.00 -0.001 1 0.000 0 1
#> Item_14 0.000 0.00 -0.001 1 0.000 0 1
#> Item_15 0.000 0.00 -0.001 1 0.000 0 1
#> Item_16 0.000 0.00 -0.001 1 0.000 0 1
#> Item_17 0.000 0.00 -0.001 1 0.000 0 1
#> Item_18 0.000 0.00 -0.001 1 0.000 0 1
#> Item_19 0.000 0.00 -0.001 1 0.000 0 1
#> Item_20 0.000 0.00 -0.001 1 0.000 0 1
#> Item_21 0.000 -1.01 0.000 1 0.000 0 1
#> Item_22 0.000 -1.01 0.000 1 0.000 0 1
#> Item_23 0.000 -1.01 0.000 1 0.000 0 1
#> Item_24 0.000 -1.01 0.000 1 0.000 0 1
#> Item_25 0.000 -1.01 0.000 1 0.000 0 1
#> Item_26 0.000 -1.01 0.000 1 0.000 0 1
#> Item_27 0.000 -1.01 0.000 1 0.000 0 1
#> Item_28 0.000 -1.01 0.000 1 0.000 0 1
#> Item_29 0.000 -1.01 0.000 1 0.000 0 1
#> Item_30 0.000 -1.01 0.000 1 0.000 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1.106
#>
anova(lltm, lltm.4) # similar fit, hence more constrained model preferred
#> AIC SABIC HQ BIC logLik X2 df p
#> lltm 34877.79 34884.71 34885.25 34897.42 -17434.89
#> lltm.4 34883.53 34897.38 34898.45 34922.79 -17433.76 2.26 4 0.688
# LLTM with mixedmirt() (more flexible in general, but slower)
LLTM <- mixedmirt(dat, model=1, fixed = ~ 0 + difficulty,
itemdesign=itemdesign, SE=FALSE)
summary(LLTM)
#>
#> Call:
#> mixedmirt(data = dat, model = 1, fixed = ~0 + difficulty, itemdesign = itemdesign,
#> SE = FALSE)
#>
#> --------------
#> FIXED EFFECTS:
#> Estimate Std.Error z.value
#> difficultyeasy 0.994 NA NA
#> difficultyhard -1.009 NA NA
#> difficultymedium -0.001 NA NA
#>
#> --------------
#> RANDOM EFFECT COVARIANCE(S):
#> Correlations on upper diagonal
#>
#> $Theta
#> F1
#> F1 1.1
#>
coef(LLTM)
#> $Item_1
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_2
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_3
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_4
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_5
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_6
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_7
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_8
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_9
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_10
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_11
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_12
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_13
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_14
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_15
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_16
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_17
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_18
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_19
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_20
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_21
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_22
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_23
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_24
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_25
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_26
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_27
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_28
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_29
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_30
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1.096
#>
# LLTM with random error estimate (not supported with mirt() )
LLTM.e <- mixedmirt(dat, model=1, fixed = ~ 0 + difficulty,
random = ~ 1|items, itemdesign=itemdesign, SE=FALSE)
coef(LLTM.e)
#> $Item_1
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_2
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_3
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_4
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_5
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_6
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_7
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_8
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_9
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_10
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_11
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_12
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_13
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_14
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_15
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_16
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_17
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_18
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_19
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_20
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_21
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_22
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_23
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_24
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_25
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_26
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_27
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_28
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_29
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_30
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1.113
#>
#> $items
#> COV_items_items
#> par 0.005
#>
###################
# General MLTM example (Embretson, 1984)
set.seed(42)
as <- matrix(rep(1,60), ncol=2)
as[11:18,1] <- as[1:9,2] <- 0
d1 <- rep(c(3,1),each = 6) # first easy, then medium, last difficult for first trait
d2 <- rep(c(0,1,2),times = 4) # difficult to easy
d <- rnorm(18)
ds <- rbind(cbind(d1=NA, d2=d), cbind(d1, d2))
(pars <- data.frame(a=as, d=ds))
#> a.1 a.2 d.d1 d.d2
#> 1 1 0 NA 1.37095845
#> 2 1 0 NA -0.56469817
#> 3 1 0 NA 0.36312841
#> 4 1 0 NA 0.63286260
#> 5 1 0 NA 0.40426832
#> 6 1 0 NA -0.10612452
#> 7 1 0 NA 1.51152200
#> 8 1 0 NA -0.09465904
#> 9 1 0 NA 2.01842371
#> 10 1 1 NA -0.06271410
#> 11 0 1 NA 1.30486965
#> 12 0 1 NA 2.28664539
#> 13 0 1 NA -1.38886070
#> 14 0 1 NA -0.27878877
#> 15 0 1 NA -0.13332134
#> 16 0 1 NA 0.63595040
#> 17 0 1 NA -0.28425292
#> 18 0 1 NA -2.65645542
#> 19 1 1 3 0.00000000
#> 20 1 1 3 1.00000000
#> 21 1 1 3 2.00000000
#> 22 1 1 3 0.00000000
#> 23 1 1 3 1.00000000
#> 24 1 1 3 2.00000000
#> 25 1 1 1 0.00000000
#> 26 1 1 1 1.00000000
#> 27 1 1 1 2.00000000
#> 28 1 1 1 0.00000000
#> 29 1 1 1 1.00000000
#> 30 1 1 1 2.00000000
dat <- simdata(as, ds, 2500,
itemtype = c(rep('dich', 18), rep('partcomp', 12)))
itemstats(dat)
#> $overall
#> N mean_total.score sd_total.score ave.r sd.r alpha SEM.alpha
#> 2500 16.494 4.83 0.088 0.059 0.747 2.428
#>
#> $itemstats
#> N mean sd total.r total.r_if_rm alpha_if_rm
#> Item_1 2500 0.752 0.432 0.265 0.180 0.745
#> Item_2 2500 0.384 0.486 0.328 0.234 0.742
#> Item_3 2500 0.563 0.496 0.319 0.222 0.743
#> Item_4 2500 0.635 0.481 0.318 0.224 0.743
#> Item_5 2500 0.582 0.493 0.320 0.224 0.743
#> Item_6 2500 0.478 0.500 0.329 0.233 0.742
#> Item_7 2500 0.767 0.423 0.274 0.191 0.744
#> Item_8 2500 0.469 0.499 0.315 0.218 0.743
#> Item_9 2500 0.849 0.358 0.233 0.161 0.745
#> Item_10 2500 0.471 0.499 0.557 0.480 0.727
#> Item_11 2500 0.736 0.441 0.352 0.268 0.740
#> Item_12 2500 0.882 0.323 0.246 0.182 0.745
#> Item_13 2500 0.232 0.422 0.302 0.220 0.743
#> Item_14 2500 0.460 0.499 0.319 0.222 0.743
#> Item_15 2500 0.480 0.500 0.387 0.294 0.739
#> Item_16 2500 0.627 0.484 0.352 0.260 0.741
#> Item_17 2500 0.441 0.497 0.318 0.222 0.743
#> Item_18 2500 0.097 0.296 0.209 0.149 0.746
#> Item_19 2500 0.466 0.499 0.381 0.287 0.739
#> Item_20 2500 0.643 0.479 0.360 0.269 0.740
#> Item_21 2500 0.788 0.409 0.335 0.257 0.741
#> Item_22 2500 0.456 0.498 0.406 0.315 0.737
#> Item_23 2500 0.646 0.478 0.403 0.315 0.737
#> Item_24 2500 0.769 0.422 0.364 0.284 0.740
#> Item_25 2500 0.349 0.477 0.408 0.321 0.737
#> Item_26 2500 0.492 0.500 0.414 0.323 0.737
#> Item_27 2500 0.586 0.493 0.381 0.289 0.739
#> Item_28 2500 0.330 0.470 0.388 0.300 0.738
#> Item_29 2500 0.477 0.500 0.361 0.266 0.740
#> Item_30 2500 0.587 0.492 0.371 0.278 0.740
#>
#> $proportions
#> 0 1
#> Item_1 0.248 0.752
#> Item_2 0.616 0.384
#> Item_3 0.437 0.563
#> Item_4 0.365 0.635
#> Item_5 0.418 0.582
#> Item_6 0.522 0.478
#> Item_7 0.233 0.767
#> Item_8 0.531 0.469
#> Item_9 0.151 0.849
#> Item_10 0.529 0.471
#> Item_11 0.264 0.736
#> Item_12 0.118 0.882
#> Item_13 0.768 0.232
#> Item_14 0.540 0.460
#> Item_15 0.520 0.480
#> Item_16 0.373 0.627
#> Item_17 0.559 0.441
#> Item_18 0.903 0.097
#> Item_19 0.534 0.466
#> Item_20 0.357 0.643
#> Item_21 0.212 0.788
#> Item_22 0.544 0.456
#> Item_23 0.354 0.646
#> Item_24 0.231 0.769
#> Item_25 0.651 0.349
#> Item_26 0.508 0.492
#> Item_27 0.414 0.586
#> Item_28 0.670 0.330
#> Item_29 0.523 0.477
#> Item_30 0.413 0.587
#>
# unconditional model
syntax <- "theta1 = 1-9, 19-30
theta2 = 10-30
COV = theta1*theta2"
itemtype <- c(rep('Rasch', 18), rep('PC1PL', 12))
mod <- mirt(dat, syntax, itemtype=itemtype)
coef(mod, simplify=TRUE)
#> $items
#> a1 a2 d g u d1 d2
#> Item_1 1 0 1.313 0 1 NA NA
#> Item_2 1 0 -0.563 0 1 NA NA
#> Item_3 1 0 0.303 0 1 NA NA
#> Item_4 1 0 0.660 0 1 NA NA
#> Item_5 1 0 0.393 0 1 NA NA
#> Item_6 1 0 -0.105 0 1 NA NA
#> Item_7 1 0 1.404 0 1 NA NA
#> Item_8 1 0 -0.147 0 1 NA NA
#> Item_9 1 0 2.013 0 1 NA NA
#> Item_10 0 1 -0.141 0 1 NA NA
#> Item_11 0 1 1.227 0 1 NA NA
#> Item_12 0 1 2.350 0 1 NA NA
#> Item_13 0 1 -1.429 0 1 NA NA
#> Item_14 0 1 -0.193 0 1 NA NA
#> Item_15 0 1 -0.098 0 1 NA NA
#> Item_16 0 1 0.623 0 1 NA NA
#> Item_17 0 1 -0.286 0 1 NA NA
#> Item_18 0 1 -2.592 0 1 NA NA
#> Item_19 1 1 NA 0 1 2.869 0.013
#> Item_20 1 1 NA 0 1 3.716 0.832
#> Item_21 1 1 NA 0 1 3.238 1.900
#> Item_22 1 1 NA 0 1 4.408 -0.175
#> Item_23 1 1 NA 0 1 3.538 0.866
#> Item_24 1 1 NA 0 1 2.850 1.890
#> Item_25 1 1 NA 0 1 1.197 -0.137
#> Item_26 1 1 NA 0 1 1.038 0.975
#> Item_27 1 1 NA 0 1 1.063 1.818
#> Item_28 1 1 NA 0 1 0.970 -0.138
#> Item_29 1 1 NA 0 1 0.902 1.010
#> Item_30 1 1 NA 0 1 1.015 1.914
#>
#> $means
#> theta1 theta2
#> 0 0
#>
#> $cov
#> theta1 theta2
#> theta1 0.917 0.081
#> theta2 0.081 0.984
#>
data.frame(est=coef(mod, simplify=TRUE)$items, pop=data.frame(a=as, d=ds))
#> est.a1 est.a2 est.d est.g est.u est.d1 est.d2 pop.a.1
#> Item_1 1 0 1.31304391 0 1 NA NA 1
#> Item_2 1 0 -0.56333612 0 1 NA NA 1
#> Item_3 1 0 0.30308480 0 1 NA NA 1
#> Item_4 1 0 0.66014200 0 1 NA NA 1
#> Item_5 1 0 0.39264419 0 1 NA NA 1
#> Item_6 1 0 -0.10532027 0 1 NA NA 1
#> Item_7 1 0 1.40425986 0 1 NA NA 1
#> Item_8 1 0 -0.14745351 0 1 NA NA 1
#> Item_9 1 0 2.01307023 0 1 NA NA 1
#> Item_10 0 1 -0.14050780 0 1 NA NA 1
#> Item_11 0 1 1.22727239 0 1 NA NA 0
#> Item_12 0 1 2.35002537 0 1 NA NA 0
#> Item_13 0 1 -1.42945629 0 1 NA NA 0
#> Item_14 0 1 -0.19283960 0 1 NA NA 0
#> Item_15 0 1 -0.09795273 0 1 NA NA 0
#> Item_16 0 1 0.62283078 0 1 NA NA 0
#> Item_17 0 1 -0.28629164 0 1 NA NA 0
#> Item_18 0 1 -2.59215041 0 1 NA NA 0
#> Item_19 1 1 NA 0 1 2.8693781 0.01320265 1
#> Item_20 1 1 NA 0 1 3.7155502 0.83156683 1
#> Item_21 1 1 NA 0 1 3.2381301 1.90023689 1
#> Item_22 1 1 NA 0 1 4.4079442 -0.17451472 1
#> Item_23 1 1 NA 0 1 3.5380699 0.86643925 1
#> Item_24 1 1 NA 0 1 2.8503541 1.88964128 1
#> Item_25 1 1 NA 0 1 1.1970301 -0.13667664 1
#> Item_26 1 1 NA 0 1 1.0376816 0.97507994 1
#> Item_27 1 1 NA 0 1 1.0632825 1.81842973 1
#> Item_28 1 1 NA 0 1 0.9702647 -0.13759053 1
#> Item_29 1 1 NA 0 1 0.9016247 1.00974832 1
#> Item_30 1 1 NA 0 1 1.0148298 1.91403020 1
#> pop.a.2 pop.d.d1 pop.d.d2
#> Item_1 0 NA 1.37095845
#> Item_2 0 NA -0.56469817
#> Item_3 0 NA 0.36312841
#> Item_4 0 NA 0.63286260
#> Item_5 0 NA 0.40426832
#> Item_6 0 NA -0.10612452
#> Item_7 0 NA 1.51152200
#> Item_8 0 NA -0.09465904
#> Item_9 0 NA 2.01842371
#> Item_10 1 NA -0.06271410
#> Item_11 1 NA 1.30486965
#> Item_12 1 NA 2.28664539
#> Item_13 1 NA -1.38886070
#> Item_14 1 NA -0.27878877
#> Item_15 1 NA -0.13332134
#> Item_16 1 NA 0.63595040
#> Item_17 1 NA -0.28425292
#> Item_18 1 NA -2.65645542
#> Item_19 1 3 0.00000000
#> Item_20 1 3 1.00000000
#> Item_21 1 3 2.00000000
#> Item_22 1 3 0.00000000
#> Item_23 1 3 1.00000000
#> Item_24 1 3 2.00000000
#> Item_25 1 1 0.00000000
#> Item_26 1 1 1.00000000
#> Item_27 1 1 2.00000000
#> Item_28 1 1 0.00000000
#> Item_29 1 1 1.00000000
#> Item_30 1 1 2.00000000
itemplot(mod, 1)
itemfit(lltm)
#> item S_X2 df.S_X2 RMSEA.S_X2 p.S_X2
#> 1 Item_1 18.506 21 0.000 0.617
#> 2 Item_2 24.007 21 0.012 0.293
#> 3 Item_3 17.975 21 0.000 0.651
#> 4 Item_4 19.815 21 0.000 0.533
#> 5 Item_5 31.211 21 0.022 0.070
#> 6 Item_6 36.118 21 0.027 0.021
#> 7 Item_7 30.097 21 0.021 0.090
#> 8 Item_8 14.926 21 0.000 0.827
#> 9 Item_9 24.846 21 0.014 0.254
#> 10 Item_10 20.420 21 0.000 0.495
#> 11 Item_11 26.435 21 0.016 0.190
#> 12 Item_12 30.628 21 0.021 0.080
#> 13 Item_13 26.631 21 0.016 0.183
#> 14 Item_14 21.262 21 0.004 0.443
#> 15 Item_15 26.837 21 0.017 0.176
#> 16 Item_16 33.290 21 0.024 0.043
#> 17 Item_17 20.076 21 0.000 0.516
#> 18 Item_18 33.049 21 0.024 0.046
#> 19 Item_19 37.018 21 0.028 0.017
#> 20 Item_20 29.165 21 0.020 0.110
#> 21 Item_21 27.093 21 0.017 0.168
#> 22 Item_22 23.511 21 0.011 0.317
#> 23 Item_23 26.528 21 0.016 0.187
#> 24 Item_24 21.415 21 0.004 0.434
#> 25 Item_25 27.944 21 0.018 0.142
#> 26 Item_26 29.322 21 0.020 0.106
#> 27 Item_27 25.752 21 0.015 0.216
#> 28 Item_28 20.106 21 0.000 0.515
#> 29 Item_29 28.544 21 0.019 0.125
#> 30 Item_30 25.486 21 0.015 0.227
head(fscores(lltm)) #EAP estimates
#> F1
#> [1,] -0.7060943
#> [2,] 0.8657140
#> [3,] 1.3579909
#> [4,] 0.2830462
#> [5,] -0.7060943
#> [6,] -0.2745315
fscores(lltm, method='EAPsum', full.scores=FALSE)
#> df X2 p.X2 SEM.alpha rxx.alpha rxx_F1
#> stats 30 22.651 0.829 2.366 0.86 0.856
#>
#> Sum.Scores F1 SE_F1 observed expected std.res
#> 0 0 -2.775 0.585 2 1.566 0.347
#> 1 1 -2.459 0.540 3 4.670 0.773
#> 2 2 -2.187 0.505 13 8.859 1.391
#> 3 3 -1.947 0.477 11 13.703 0.730
#> 4 4 -1.731 0.454 13 18.875 1.352
#> 5 5 -1.533 0.436 33 24.133 1.805
#> 6 6 -1.349 0.421 28 29.298 0.240
#> 7 7 -1.177 0.409 35 34.229 0.132
#> 8 8 -1.014 0.400 36 38.814 0.452
#> 9 9 -0.857 0.392 45 42.962 0.311
#> 10 10 -0.706 0.386 53 46.594 0.938
#> 11 11 -0.559 0.381 45 49.648 0.660
#> 12 12 -0.416 0.377 46 52.070 0.841
#> 13 13 -0.275 0.375 55 53.820 0.161
#> 14 14 -0.135 0.373 51 54.870 0.522
#> 15 15 0.004 0.373 52 55.202 0.431
#> 16 16 0.143 0.373 64 54.810 1.241
#> 17 17 0.283 0.375 47 53.703 0.915
#> 18 18 0.424 0.377 48 51.897 0.541
#> 19 19 0.568 0.381 60 49.424 1.504
#> 20 20 0.715 0.386 55 46.325 1.275
#> 21 21 0.866 0.392 36 42.655 1.019
#> 22 22 1.022 0.400 34 38.479 0.722
#> 23 23 1.186 0.409 37 33.878 0.536
#> 24 24 1.358 0.421 25 28.946 0.733
#> 25 25 1.541 0.436 24 23.797 0.042
#> 26 26 1.739 0.454 19 18.572 0.099
#> 27 27 1.955 0.476 17 13.450 0.968
#> 28 28 2.195 0.505 9 8.672 0.111
#> 29 29 2.467 0.540 4 4.557 0.261
#> 30 30 2.783 0.585 0 1.522 1.234
M2(lltm) # goodness of fit
#> M2 df p RMSEA RMSEA_5 RMSEA_95 SRMSR TLI CFI
#> stats 452.9984 461 0.5960236 0 0 0.009921769 0.02960249 1.000596 1
head(personfit(lltm))
#> outfit z.outfit infit z.infit Zh
#> 1 0.9556985 -0.13140309 0.9958807 0.02853420 0.08783112
#> 2 0.6399788 -1.61120831 0.7395941 -1.60495288 1.50441490
#> 3 1.0131241 0.15347265 0.9762310 -0.03209238 0.05424258
#> 4 0.9803474 -0.06312702 0.9532372 -0.27742936 0.25248909
#> 5 0.8274978 -0.76177996 0.9361313 -0.34897186 0.53387552
#> 6 1.0753664 0.49629111 1.0226248 0.20290036 -0.25664723
residuals(lltm)
#> LD matrix (lower triangle) and standardized residual correlations (upper triangle)
#>
#> Upper triangle summary:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> -0.111 -0.043 0.010 0.000 0.044 0.087
#>
#> Item_1 Item_2 Item_3 Item_4 Item_5 Item_6 Item_7 Item_8 Item_9 Item_10
#> Item_1 -0.055 -0.029 0.036 -0.054 -0.047 -0.043 0.031 0.034 0.057
#> Item_2 3.028 -0.025 -0.035 -0.063 -0.030 0.042 0.010 -0.048 -0.066
#> Item_3 0.831 0.623 -0.037 0.041 0.024 -0.040 0.024 -0.038 -0.063
#> Item_4 1.317 1.258 1.373 -0.045 0.046 0.046 -0.037 0.040 0.059
#> Item_5 2.880 3.933 1.669 2.015 -0.039 -0.050 0.029 -0.033 -0.063
#> Item_6 2.223 0.882 0.557 2.071 1.529 -0.037 0.015 -0.047 0.053
#> Item_7 1.874 1.778 1.632 2.079 2.493 1.334 0.037 0.049 0.071
#> Item_8 0.967 0.096 0.580 1.367 0.861 0.211 1.371 0.033 -0.057
#> Item_9 1.160 2.318 1.435 1.617 1.115 2.203 2.428 1.103 0.064
#> Item_10 3.198 4.415 3.947 3.469 3.968 2.783 5.027 3.221 4.066
#> Item_11 1.491 3.375 1.516 4.216 4.070 1.375 3.159 1.388 2.630 4.209
#> Item_12 0.761 0.549 0.846 2.713 2.611 0.336 4.108 0.724 1.399 2.393
#> Item_13 2.409 5.615 4.394 4.291 5.789 1.583 5.492 2.553 5.388 6.493
#> Item_14 1.000 3.943 0.843 1.093 1.009 0.153 1.443 0.096 0.906 3.835
#> Item_15 1.772 3.339 1.295 1.909 2.053 1.395 2.248 1.903 2.237 5.337
#> Item_16 0.808 1.592 0.899 1.260 3.174 1.680 3.782 1.448 1.685 3.776
#> Item_17 2.228 3.623 2.450 2.519 2.077 2.200 6.248 2.901 2.173 3.412
#> Item_18 0.455 0.379 0.690 2.643 1.998 0.158 1.813 1.881 6.735 2.314
#> Item_19 0.941 0.560 3.048 2.056 1.092 2.901 2.438 0.935 1.052 3.083
#> Item_20 1.489 1.981 1.194 1.432 1.976 0.931 2.047 2.783 1.952 3.887
#> Item_21 1.872 2.079 1.735 3.595 2.563 2.168 5.007 3.018 2.421 4.933
#> Item_22 1.997 1.402 0.569 0.632 0.914 1.153 2.394 0.070 1.688 3.344
#> Item_23 0.600 1.194 1.231 0.863 0.909 0.605 2.419 1.983 2.268 2.485
#> Item_24 0.828 0.387 3.366 1.165 2.867 0.206 1.935 0.596 1.585 2.866
#> Item_25 0.807 2.907 3.086 1.744 1.763 0.233 1.347 0.141 0.684 6.600
#> Item_26 0.386 0.560 1.440 1.090 2.842 0.118 1.417 0.452 1.304 2.514
#> Item_27 0.826 0.946 2.004 1.220 1.351 0.860 2.851 2.535 2.196 3.624
#> Item_28 1.828 1.205 2.519 1.653 7.177 1.837 2.613 1.151 1.258 2.790
#> Item_29 4.096 6.266 3.295 6.489 8.539 7.663 5.249 3.852 4.208 6.685
#> Item_30 0.643 0.472 1.795 2.359 0.812 1.039 3.489 1.126 3.201 2.632
#> Item_11 Item_12 Item_13 Item_14 Item_15 Item_16 Item_17 Item_18 Item_19
#> Item_1 -0.039 -0.028 -0.049 -0.032 0.042 -0.028 -0.047 -0.021 -0.031
#> Item_2 -0.058 -0.023 -0.075 -0.063 -0.058 -0.040 0.060 -0.019 0.024
#> Item_3 0.039 0.029 -0.066 0.029 0.036 -0.030 -0.049 0.026 0.055
#> Item_4 0.065 0.052 -0.066 -0.033 0.044 -0.035 0.050 -0.051 0.045
#> Item_5 -0.064 -0.051 -0.076 0.032 0.045 -0.056 -0.046 -0.045 0.033
#> Item_6 0.037 -0.018 -0.040 -0.012 0.037 -0.041 -0.047 -0.013 0.054
#> Item_7 0.056 -0.064 -0.074 0.038 -0.047 -0.061 -0.079 -0.043 0.049
#> Item_8 -0.037 -0.027 0.051 0.010 0.044 -0.038 -0.054 0.043 0.031
#> Item_9 0.051 -0.037 -0.073 -0.030 0.047 0.041 -0.047 0.082 0.032
#> Item_10 0.065 0.049 -0.081 0.062 -0.073 0.061 -0.058 0.048 0.056
#> Item_11 -0.048 -0.057 -0.038 0.061 0.056 0.081 0.057 0.062
#> Item_12 2.316 -0.038 -0.060 -0.079 -0.055 -0.043 0.015 0.056
#> Item_13 3.195 1.463 0.050 0.087 -0.059 0.062 -0.057 0.042
#> Item_14 1.464 3.594 2.452 0.033 0.033 0.052 -0.014 0.028
#> Item_15 3.763 6.174 7.600 1.112 0.049 0.056 0.043 0.038
#> Item_16 3.153 2.971 3.517 1.099 2.412 0.053 -0.031 -0.064
#> Item_17 6.588 1.883 3.830 2.738 3.151 2.808 0.040 0.042
#> Item_18 3.250 0.239 3.276 0.200 1.829 0.960 1.633 -0.025
#> Item_19 3.797 3.117 1.730 0.768 1.429 4.139 1.790 0.608
#> Item_20 6.815 1.633 3.211 1.004 1.566 1.871 3.301 1.653 4.252
#> Item_21 5.023 2.119 6.746 4.620 3.131 1.837 5.118 3.817 2.478
#> Item_22 1.756 0.974 1.445 2.503 0.795 0.716 1.646 0.540 1.570
#> Item_23 2.409 0.433 1.653 2.052 1.072 1.242 4.312 0.421 1.928
#> Item_24 3.107 0.450 1.842 0.397 1.032 1.103 1.686 0.423 0.595
#> Item_25 1.566 0.392 2.815 1.117 2.916 0.666 5.749 2.929 0.976
#> Item_26 1.319 2.305 1.584 0.095 0.754 0.810 3.788 1.671 0.664
#> Item_27 1.947 2.021 2.064 4.415 1.458 1.360 1.940 1.095 0.749
#> Item_28 3.301 1.489 2.404 4.079 2.132 2.431 2.072 0.854 1.127
#> Item_29 3.547 3.534 5.614 4.690 3.384 4.347 6.474 3.556 3.963
#> Item_30 7.049 12.218 1.979 0.878 3.335 1.428 1.995 1.511 1.349
#> Item_20 Item_21 Item_22 Item_23 Item_24 Item_25 Item_26 Item_27 Item_28
#> Item_1 -0.039 -0.043 -0.045 0.024 -0.029 0.028 -0.020 -0.029 -0.043
#> Item_2 -0.045 0.046 0.037 -0.035 -0.020 0.054 0.024 0.031 -0.035
#> Item_3 -0.035 -0.042 -0.024 -0.035 0.058 0.056 0.038 0.045 0.050
#> Item_4 -0.038 0.060 0.025 -0.029 0.034 0.042 -0.033 0.035 0.041
#> Item_5 0.044 -0.051 0.030 -0.030 -0.054 -0.042 -0.053 -0.037 -0.085
#> Item_6 0.031 0.047 0.034 -0.025 0.014 0.015 0.011 0.029 0.043
#> Item_7 -0.045 0.071 -0.049 0.049 0.044 -0.037 -0.038 -0.053 -0.051
#> Item_8 -0.053 0.055 -0.008 -0.045 0.024 0.012 0.021 -0.050 0.034
#> Item_9 -0.044 0.049 -0.041 0.048 0.040 -0.026 -0.036 -0.047 -0.035
#> Item_10 0.062 -0.070 0.058 0.050 0.054 0.081 -0.050 0.060 0.053
#> Item_11 0.083 0.071 -0.042 -0.049 0.056 0.040 0.036 -0.044 0.057
#> Item_12 0.040 -0.046 0.031 -0.021 -0.021 -0.020 -0.048 -0.045 -0.039
#> Item_13 -0.057 -0.082 -0.038 0.041 0.043 0.053 -0.040 0.045 -0.049
#> Item_14 -0.032 0.068 -0.050 0.045 0.020 0.033 -0.010 -0.066 0.064
#> Item_15 0.040 0.056 0.028 -0.033 -0.032 0.054 -0.027 -0.038 0.046
#> Item_16 0.043 0.043 -0.027 -0.035 -0.033 0.026 -0.028 0.037 -0.049
#> Item_17 0.057 -0.072 -0.041 -0.066 -0.041 0.076 -0.062 0.044 -0.046
#> Item_18 0.041 0.062 0.023 -0.021 0.021 0.054 -0.041 0.033 -0.029
#> Item_19 0.065 0.050 0.040 -0.044 -0.024 0.031 -0.026 -0.027 0.034
#> Item_20 -0.047 -0.032 -0.036 -0.035 0.038 -0.044 0.040 -0.051
#> Item_21 2.208 0.044 0.061 0.044 0.060 0.041 0.050 0.082
#> Item_22 1.033 1.923 0.025 -0.043 0.030 0.018 -0.020 -0.029
#> Item_23 1.309 3.701 0.612 0.034 0.023 0.053 -0.023 -0.031
#> Item_24 1.218 1.893 1.812 1.174 0.024 0.012 -0.033 -0.033
#> Item_25 1.416 3.585 0.884 0.537 0.583 0.023 0.058 0.049
#> Item_26 1.897 1.698 0.309 2.782 0.143 0.545 0.020 0.036
#> Item_27 1.593 2.451 0.413 0.513 1.082 3.400 0.407 -0.036
#> Item_28 2.591 6.768 0.854 0.963 1.058 2.364 1.288 1.328
#> Item_29 3.451 5.900 5.999 4.259 4.562 6.714 3.035 4.346 4.441
#> Item_30 1.636 1.936 0.238 0.824 0.919 1.834 0.388 0.535 4.168
#> Item_29 Item_30
#> Item_1 -0.064 -0.025
#> Item_2 -0.079 -0.022
#> Item_3 -0.057 -0.042
#> Item_4 -0.081 -0.049
#> Item_5 -0.092 0.028
#> Item_6 -0.088 0.032
#> Item_7 -0.072 0.059
#> Item_8 -0.062 0.034
#> Item_9 0.065 0.057
#> Item_10 -0.082 0.051
#> Item_11 0.060 0.084
#> Item_12 -0.059 -0.111
#> Item_13 -0.075 0.044
#> Item_14 0.068 0.030
#> Item_15 -0.058 0.058
#> Item_16 -0.066 0.038
#> Item_17 -0.080 0.045
#> Item_18 -0.060 0.039
#> Item_19 -0.063 -0.037
#> Item_20 0.059 0.040
#> Item_21 0.077 0.044
#> Item_22 -0.077 0.015
#> Item_23 -0.065 0.029
#> Item_24 -0.068 0.030
#> Item_25 0.082 0.043
#> Item_26 0.055 0.020
#> Item_27 -0.066 -0.023
#> Item_28 -0.067 0.065
#> Item_29 0.086
#> Item_30 7.382
# intercept across items also possible by removing ~ 0 portion, just interpreted differently
lltm.int <- mirt(dat, itemtype = 'Rasch',
item.formula = ~ difficulty, itemdesign=itemdesign)
anova(lltm, lltm.int) # same
#> AIC SABIC HQ BIC logLik X2 df p
#> lltm 34877.79 34884.71 34885.25 34897.42 -17434.89
#> lltm.int 34877.79 34884.71 34885.25 34897.42 -17434.89 0 0 NaN
coef(lltm.int, simplify=TRUE)
#> $items
#> (Intercept) difficultyhard difficultymedium a1 d g u
#> Item_1 0.995 0.000 0.000 1 0 0 1
#> Item_2 0.995 0.000 0.000 1 0 0 1
#> Item_3 0.995 0.000 0.000 1 0 0 1
#> Item_4 0.995 0.000 0.000 1 0 0 1
#> Item_5 0.995 0.000 0.000 1 0 0 1
#> Item_6 0.995 0.000 0.000 1 0 0 1
#> Item_7 0.995 0.000 0.000 1 0 0 1
#> Item_8 0.995 0.000 0.000 1 0 0 1
#> Item_9 0.995 0.000 0.000 1 0 0 1
#> Item_10 0.995 0.000 0.000 1 0 0 1
#> Item_11 0.995 0.000 -0.996 1 0 0 1
#> Item_12 0.995 0.000 -0.996 1 0 0 1
#> Item_13 0.995 0.000 -0.996 1 0 0 1
#> Item_14 0.995 0.000 -0.996 1 0 0 1
#> Item_15 0.995 0.000 -0.996 1 0 0 1
#> Item_16 0.995 0.000 -0.996 1 0 0 1
#> Item_17 0.995 0.000 -0.996 1 0 0 1
#> Item_18 0.995 0.000 -0.996 1 0 0 1
#> Item_19 0.995 0.000 -0.996 1 0 0 1
#> Item_20 0.995 0.000 -0.996 1 0 0 1
#> Item_21 0.995 -2.005 0.000 1 0 0 1
#> Item_22 0.995 -2.005 0.000 1 0 0 1
#> Item_23 0.995 -2.005 0.000 1 0 0 1
#> Item_24 0.995 -2.005 0.000 1 0 0 1
#> Item_25 0.995 -2.005 0.000 1 0 0 1
#> Item_26 0.995 -2.005 0.000 1 0 0 1
#> Item_27 0.995 -2.005 0.000 1 0 0 1
#> Item_28 0.995 -2.005 0.000 1 0 0 1
#> Item_29 0.995 -2.005 0.000 1 0 0 1
#> Item_30 0.995 -2.005 0.000 1 0 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1.105
#>
# using unconditional modeling for first four items
itemdesign.sub <- itemdesign[5:nrow(itemdesign), , drop=FALSE]
itemdesign.sub # note that rownames are required in this case
#> difficulty
#> Item_5 easy
#> Item_6 easy
#> Item_7 easy
#> Item_8 easy
#> Item_9 easy
#> Item_10 easy
#> Item_11 medium
#> Item_12 medium
#> Item_13 medium
#> Item_14 medium
#> Item_15 medium
#> Item_16 medium
#> Item_17 medium
#> Item_18 medium
#> Item_19 medium
#> Item_20 medium
#> Item_21 hard
#> Item_22 hard
#> Item_23 hard
#> Item_24 hard
#> Item_25 hard
#> Item_26 hard
#> Item_27 hard
#> Item_28 hard
#> Item_29 hard
#> Item_30 hard
lltm.4 <- mirt(dat, itemtype = 'Rasch',
item.formula = ~ 0 + difficulty, itemdesign=itemdesign.sub)
coef(lltm.4, simplify=TRUE) # first four items are the standard Rasch
#> $items
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> Item_1 0.000 0.00 0.000 1 1.040 0 1
#> Item_2 0.000 0.00 0.000 1 0.972 0 1
#> Item_3 0.000 0.00 0.000 1 1.051 0 1
#> Item_4 0.000 0.00 0.000 1 1.057 0 1
#> Item_5 0.972 0.00 0.000 1 0.000 0 1
#> Item_6 0.972 0.00 0.000 1 0.000 0 1
#> Item_7 0.972 0.00 0.000 1 0.000 0 1
#> Item_8 0.972 0.00 0.000 1 0.000 0 1
#> Item_9 0.972 0.00 0.000 1 0.000 0 1
#> Item_10 0.972 0.00 0.000 1 0.000 0 1
#> Item_11 0.000 0.00 -0.001 1 0.000 0 1
#> Item_12 0.000 0.00 -0.001 1 0.000 0 1
#> Item_13 0.000 0.00 -0.001 1 0.000 0 1
#> Item_14 0.000 0.00 -0.001 1 0.000 0 1
#> Item_15 0.000 0.00 -0.001 1 0.000 0 1
#> Item_16 0.000 0.00 -0.001 1 0.000 0 1
#> Item_17 0.000 0.00 -0.001 1 0.000 0 1
#> Item_18 0.000 0.00 -0.001 1 0.000 0 1
#> Item_19 0.000 0.00 -0.001 1 0.000 0 1
#> Item_20 0.000 0.00 -0.001 1 0.000 0 1
#> Item_21 0.000 -1.01 0.000 1 0.000 0 1
#> Item_22 0.000 -1.01 0.000 1 0.000 0 1
#> Item_23 0.000 -1.01 0.000 1 0.000 0 1
#> Item_24 0.000 -1.01 0.000 1 0.000 0 1
#> Item_25 0.000 -1.01 0.000 1 0.000 0 1
#> Item_26 0.000 -1.01 0.000 1 0.000 0 1
#> Item_27 0.000 -1.01 0.000 1 0.000 0 1
#> Item_28 0.000 -1.01 0.000 1 0.000 0 1
#> Item_29 0.000 -1.01 0.000 1 0.000 0 1
#> Item_30 0.000 -1.01 0.000 1 0.000 0 1
#>
#> $means
#> F1
#> 0
#>
#> $cov
#> F1
#> F1 1.106
#>
anova(lltm, lltm.4) # similar fit, hence more constrained model preferred
#> AIC SABIC HQ BIC logLik X2 df p
#> lltm 34877.79 34884.71 34885.25 34897.42 -17434.89
#> lltm.4 34883.53 34897.38 34898.45 34922.79 -17433.76 2.26 4 0.688
# LLTM with mixedmirt() (more flexible in general, but slower)
LLTM <- mixedmirt(dat, model=1, fixed = ~ 0 + difficulty,
itemdesign=itemdesign, SE=FALSE)
summary(LLTM)
#>
#> Call:
#> mixedmirt(data = dat, model = 1, fixed = ~0 + difficulty, itemdesign = itemdesign,
#> SE = FALSE)
#>
#> --------------
#> FIXED EFFECTS:
#> Estimate Std.Error z.value
#> difficultyeasy 0.994 NA NA
#> difficultyhard -1.009 NA NA
#> difficultymedium -0.001 NA NA
#>
#> --------------
#> RANDOM EFFECT COVARIANCE(S):
#> Correlations on upper diagonal
#>
#> $Theta
#> F1
#> F1 1.1
#>
coef(LLTM)
#> $Item_1
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_2
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_3
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_4
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_5
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_6
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_7
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_8
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_9
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_10
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_11
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_12
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_13
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_14
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_15
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_16
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_17
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_18
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_19
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_20
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_21
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_22
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_23
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_24
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_25
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_26
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_27
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_28
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_29
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $Item_30
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 0.994 -1.009 -0.001 1 0 0 1
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1.096
#>
# LLTM with random error estimate (not supported with mirt() )
LLTM.e <- mixedmirt(dat, model=1, fixed = ~ 0 + difficulty,
random = ~ 1|items, itemdesign=itemdesign, SE=FALSE)
coef(LLTM.e)
#> $Item_1
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_2
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_3
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_4
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_5
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_6
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_7
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_8
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_9
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_10
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_11
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_12
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_13
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_14
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_15
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_16
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_17
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_18
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_19
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_20
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_21
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_22
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_23
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_24
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_25
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_26
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_27
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_28
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_29
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $Item_30
#> difficultyeasy difficultyhard difficultymedium a1 d g u
#> par 1.054 -0.993 0.027 1 0 0 1
#>
#> $GroupPars
#> MEAN_1 COV_11
#> par 0 1.113
#>
#> $items
#> COV_items_items
#> par 0.005
#>
###################
# General MLTM example (Embretson, 1984)
set.seed(42)
as <- matrix(rep(1,60), ncol=2)
as[11:18,1] <- as[1:9,2] <- 0
d1 <- rep(c(3,1),each = 6) # first easy, then medium, last difficult for first trait
d2 <- rep(c(0,1,2),times = 4) # difficult to easy
d <- rnorm(18)
ds <- rbind(cbind(d1=NA, d2=d), cbind(d1, d2))
(pars <- data.frame(a=as, d=ds))
#> a.1 a.2 d.d1 d.d2
#> 1 1 0 NA 1.37095845
#> 2 1 0 NA -0.56469817
#> 3 1 0 NA 0.36312841
#> 4 1 0 NA 0.63286260
#> 5 1 0 NA 0.40426832
#> 6 1 0 NA -0.10612452
#> 7 1 0 NA 1.51152200
#> 8 1 0 NA -0.09465904
#> 9 1 0 NA 2.01842371
#> 10 1 1 NA -0.06271410
#> 11 0 1 NA 1.30486965
#> 12 0 1 NA 2.28664539
#> 13 0 1 NA -1.38886070
#> 14 0 1 NA -0.27878877
#> 15 0 1 NA -0.13332134
#> 16 0 1 NA 0.63595040
#> 17 0 1 NA -0.28425292
#> 18 0 1 NA -2.65645542
#> 19 1 1 3 0.00000000
#> 20 1 1 3 1.00000000
#> 21 1 1 3 2.00000000
#> 22 1 1 3 0.00000000
#> 23 1 1 3 1.00000000
#> 24 1 1 3 2.00000000
#> 25 1 1 1 0.00000000
#> 26 1 1 1 1.00000000
#> 27 1 1 1 2.00000000
#> 28 1 1 1 0.00000000
#> 29 1 1 1 1.00000000
#> 30 1 1 1 2.00000000
dat <- simdata(as, ds, 2500,
itemtype = c(rep('dich', 18), rep('partcomp', 12)))
itemstats(dat)
#> $overall
#> N mean_total.score sd_total.score ave.r sd.r alpha SEM.alpha
#> 2500 16.494 4.83 0.088 0.059 0.747 2.428
#>
#> $itemstats
#> N mean sd total.r total.r_if_rm alpha_if_rm
#> Item_1 2500 0.752 0.432 0.265 0.180 0.745
#> Item_2 2500 0.384 0.486 0.328 0.234 0.742
#> Item_3 2500 0.563 0.496 0.319 0.222 0.743
#> Item_4 2500 0.635 0.481 0.318 0.224 0.743
#> Item_5 2500 0.582 0.493 0.320 0.224 0.743
#> Item_6 2500 0.478 0.500 0.329 0.233 0.742
#> Item_7 2500 0.767 0.423 0.274 0.191 0.744
#> Item_8 2500 0.469 0.499 0.315 0.218 0.743
#> Item_9 2500 0.849 0.358 0.233 0.161 0.745
#> Item_10 2500 0.471 0.499 0.557 0.480 0.727
#> Item_11 2500 0.736 0.441 0.352 0.268 0.740
#> Item_12 2500 0.882 0.323 0.246 0.182 0.745
#> Item_13 2500 0.232 0.422 0.302 0.220 0.743
#> Item_14 2500 0.460 0.499 0.319 0.222 0.743
#> Item_15 2500 0.480 0.500 0.387 0.294 0.739
#> Item_16 2500 0.627 0.484 0.352 0.260 0.741
#> Item_17 2500 0.441 0.497 0.318 0.222 0.743
#> Item_18 2500 0.097 0.296 0.209 0.149 0.746
#> Item_19 2500 0.466 0.499 0.381 0.287 0.739
#> Item_20 2500 0.643 0.479 0.360 0.269 0.740
#> Item_21 2500 0.788 0.409 0.335 0.257 0.741
#> Item_22 2500 0.456 0.498 0.406 0.315 0.737
#> Item_23 2500 0.646 0.478 0.403 0.315 0.737
#> Item_24 2500 0.769 0.422 0.364 0.284 0.740
#> Item_25 2500 0.349 0.477 0.408 0.321 0.737
#> Item_26 2500 0.492 0.500 0.414 0.323 0.737
#> Item_27 2500 0.586 0.493 0.381 0.289 0.739
#> Item_28 2500 0.330 0.470 0.388 0.300 0.738
#> Item_29 2500 0.477 0.500 0.361 0.266 0.740
#> Item_30 2500 0.587 0.492 0.371 0.278 0.740
#>
#> $proportions
#> 0 1
#> Item_1 0.248 0.752
#> Item_2 0.616 0.384
#> Item_3 0.437 0.563
#> Item_4 0.365 0.635
#> Item_5 0.418 0.582
#> Item_6 0.522 0.478
#> Item_7 0.233 0.767
#> Item_8 0.531 0.469
#> Item_9 0.151 0.849
#> Item_10 0.529 0.471
#> Item_11 0.264 0.736
#> Item_12 0.118 0.882
#> Item_13 0.768 0.232
#> Item_14 0.540 0.460
#> Item_15 0.520 0.480
#> Item_16 0.373 0.627
#> Item_17 0.559 0.441
#> Item_18 0.903 0.097
#> Item_19 0.534 0.466
#> Item_20 0.357 0.643
#> Item_21 0.212 0.788
#> Item_22 0.544 0.456
#> Item_23 0.354 0.646
#> Item_24 0.231 0.769
#> Item_25 0.651 0.349
#> Item_26 0.508 0.492
#> Item_27 0.414 0.586
#> Item_28 0.670 0.330
#> Item_29 0.523 0.477
#> Item_30 0.413 0.587
#>
# unconditional model
syntax <- "theta1 = 1-9, 19-30
theta2 = 10-30
COV = theta1*theta2"
itemtype <- c(rep('Rasch', 18), rep('PC1PL', 12))
mod <- mirt(dat, syntax, itemtype=itemtype)
coef(mod, simplify=TRUE)
#> $items
#> a1 a2 d g u d1 d2
#> Item_1 1 0 1.313 0 1 NA NA
#> Item_2 1 0 -0.563 0 1 NA NA
#> Item_3 1 0 0.303 0 1 NA NA
#> Item_4 1 0 0.660 0 1 NA NA
#> Item_5 1 0 0.393 0 1 NA NA
#> Item_6 1 0 -0.105 0 1 NA NA
#> Item_7 1 0 1.404 0 1 NA NA
#> Item_8 1 0 -0.147 0 1 NA NA
#> Item_9 1 0 2.013 0 1 NA NA
#> Item_10 0 1 -0.141 0 1 NA NA
#> Item_11 0 1 1.227 0 1 NA NA
#> Item_12 0 1 2.350 0 1 NA NA
#> Item_13 0 1 -1.429 0 1 NA NA
#> Item_14 0 1 -0.193 0 1 NA NA
#> Item_15 0 1 -0.098 0 1 NA NA
#> Item_16 0 1 0.623 0 1 NA NA
#> Item_17 0 1 -0.286 0 1 NA NA
#> Item_18 0 1 -2.592 0 1 NA NA
#> Item_19 1 1 NA 0 1 2.869 0.013
#> Item_20 1 1 NA 0 1 3.716 0.832
#> Item_21 1 1 NA 0 1 3.238 1.900
#> Item_22 1 1 NA 0 1 4.408 -0.175
#> Item_23 1 1 NA 0 1 3.538 0.866
#> Item_24 1 1 NA 0 1 2.850 1.890
#> Item_25 1 1 NA 0 1 1.197 -0.137
#> Item_26 1 1 NA 0 1 1.038 0.975
#> Item_27 1 1 NA 0 1 1.063 1.818
#> Item_28 1 1 NA 0 1 0.970 -0.138
#> Item_29 1 1 NA 0 1 0.902 1.010
#> Item_30 1 1 NA 0 1 1.015 1.914
#>
#> $means
#> theta1 theta2
#> 0 0
#>
#> $cov
#> theta1 theta2
#> theta1 0.917 0.081
#> theta2 0.081 0.984
#>
data.frame(est=coef(mod, simplify=TRUE)$items, pop=data.frame(a=as, d=ds))
#> est.a1 est.a2 est.d est.g est.u est.d1 est.d2 pop.a.1
#> Item_1 1 0 1.31304391 0 1 NA NA 1
#> Item_2 1 0 -0.56333612 0 1 NA NA 1
#> Item_3 1 0 0.30308480 0 1 NA NA 1
#> Item_4 1 0 0.66014200 0 1 NA NA 1
#> Item_5 1 0 0.39264419 0 1 NA NA 1
#> Item_6 1 0 -0.10532027 0 1 NA NA 1
#> Item_7 1 0 1.40425986 0 1 NA NA 1
#> Item_8 1 0 -0.14745351 0 1 NA NA 1
#> Item_9 1 0 2.01307023 0 1 NA NA 1
#> Item_10 0 1 -0.14050780 0 1 NA NA 1
#> Item_11 0 1 1.22727239 0 1 NA NA 0
#> Item_12 0 1 2.35002537 0 1 NA NA 0
#> Item_13 0 1 -1.42945629 0 1 NA NA 0
#> Item_14 0 1 -0.19283960 0 1 NA NA 0
#> Item_15 0 1 -0.09795273 0 1 NA NA 0
#> Item_16 0 1 0.62283078 0 1 NA NA 0
#> Item_17 0 1 -0.28629164 0 1 NA NA 0
#> Item_18 0 1 -2.59215041 0 1 NA NA 0
#> Item_19 1 1 NA 0 1 2.8693781 0.01320265 1
#> Item_20 1 1 NA 0 1 3.7155502 0.83156683 1
#> Item_21 1 1 NA 0 1 3.2381301 1.90023689 1
#> Item_22 1 1 NA 0 1 4.4079442 -0.17451472 1
#> Item_23 1 1 NA 0 1 3.5380699 0.86643925 1
#> Item_24 1 1 NA 0 1 2.8503541 1.88964128 1
#> Item_25 1 1 NA 0 1 1.1970301 -0.13667664 1
#> Item_26 1 1 NA 0 1 1.0376816 0.97507994 1
#> Item_27 1 1 NA 0 1 1.0632825 1.81842973 1
#> Item_28 1 1 NA 0 1 0.9702647 -0.13759053 1
#> Item_29 1 1 NA 0 1 0.9016247 1.00974832 1
#> Item_30 1 1 NA 0 1 1.0148298 1.91403020 1
#> pop.a.2 pop.d.d1 pop.d.d2
#> Item_1 0 NA 1.37095845
#> Item_2 0 NA -0.56469817
#> Item_3 0 NA 0.36312841
#> Item_4 0 NA 0.63286260
#> Item_5 0 NA 0.40426832
#> Item_6 0 NA -0.10612452
#> Item_7 0 NA 1.51152200
#> Item_8 0 NA -0.09465904
#> Item_9 0 NA 2.01842371
#> Item_10 1 NA -0.06271410
#> Item_11 1 NA 1.30486965
#> Item_12 1 NA 2.28664539
#> Item_13 1 NA -1.38886070
#> Item_14 1 NA -0.27878877
#> Item_15 1 NA -0.13332134
#> Item_16 1 NA 0.63595040
#> Item_17 1 NA -0.28425292
#> Item_18 1 NA -2.65645542
#> Item_19 1 3 0.00000000
#> Item_20 1 3 1.00000000
#> Item_21 1 3 2.00000000
#> Item_22 1 3 0.00000000
#> Item_23 1 3 1.00000000
#> Item_24 1 3 2.00000000
#> Item_25 1 1 0.00000000
#> Item_26 1 1 1.00000000
#> Item_27 1 1 2.00000000
#> Item_28 1 1 0.00000000
#> Item_29 1 1 1.00000000
#> Item_30 1 1 2.00000000
itemplot(mod, 1)
 itemplot(mod, 30)
itemplot(mod, 30)
 # MLTM design only for PC1PL items
itemdesign <- data.frame(t1_difficulty= factor(d1, labels=c('medium', 'easy')),
t2_difficulty=factor(d2, labels=c('hard', 'medium', 'easy')))
rownames(itemdesign) <- colnames(dat)[19:30]
itemdesign
#> t1_difficulty t2_difficulty
#> Item_19 easy hard
#> Item_20 easy medium
#> Item_21 easy easy
#> Item_22 easy hard
#> Item_23 easy medium
#> Item_24 easy easy
#> Item_25 medium hard
#> Item_26 medium medium
#> Item_27 medium easy
#> Item_28 medium hard
#> Item_29 medium medium
#> Item_30 medium easy
# fit MLTM design, leaving first 18 items as 'Rasch' type
mltm <- mirt(dat, syntax, itemtype=itemtype, itemdesign=itemdesign,
item.formula = list(theta1 ~ 0 + t1_difficulty,
theta2 ~ 0 + t2_difficulty), SE=TRUE)
coef(mltm, simplify=TRUE)
#> $items
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> Item_1 0.00 0.000
#> Item_2 0.00 0.000
#> Item_3 0.00 0.000
#> Item_4 0.00 0.000
#> Item_5 0.00 0.000
#> Item_6 0.00 0.000
#> Item_7 0.00 0.000
#> Item_8 0.00 0.000
#> Item_9 0.00 0.000
#> Item_10 0.00 0.000
#> Item_11 0.00 0.000
#> Item_12 0.00 0.000
#> Item_13 0.00 0.000
#> Item_14 0.00 0.000
#> Item_15 0.00 0.000
#> Item_16 0.00 0.000
#> Item_17 0.00 0.000
#> Item_18 0.00 0.000
#> Item_19 3.19 0.000
#> Item_20 3.19 0.000
#> Item_21 3.19 0.000
#> Item_22 3.19 0.000
#> Item_23 3.19 0.000
#> Item_24 3.19 0.000
#> Item_25 0.00 1.031
#> Item_26 0.00 1.031
#> Item_27 0.00 1.031
#> Item_28 0.00 1.031
#> Item_29 0.00 1.031
#> Item_30 0.00 1.031
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> Item_1 0.000 0.000
#> Item_2 0.000 0.000
#> Item_3 0.000 0.000
#> Item_4 0.000 0.000
#> Item_5 0.000 0.000
#> Item_6 0.000 0.000
#> Item_7 0.000 0.000
#> Item_8 0.000 0.000
#> Item_9 0.000 0.000
#> Item_10 0.000 0.000
#> Item_11 0.000 0.000
#> Item_12 0.000 0.000
#> Item_13 0.000 0.000
#> Item_14 0.000 0.000
#> Item_15 0.000 0.000
#> Item_16 0.000 0.000
#> Item_17 0.000 0.000
#> Item_18 0.000 0.000
#> Item_19 0.000 -0.078
#> Item_20 0.000 0.000
#> Item_21 1.857 0.000
#> Item_22 0.000 -0.078
#> Item_23 0.000 0.000
#> Item_24 1.857 0.000
#> Item_25 0.000 -0.078
#> Item_26 0.000 0.000
#> Item_27 1.857 0.000
#> Item_28 0.000 -0.078
#> Item_29 0.000 0.000
#> Item_30 1.857 0.000
#> theta2.t2_difficultymedium a1 a2 d g u d1 d2
#> Item_1 0.000 1 0 1.314 0 1 NA NA
#> Item_2 0.000 1 0 -0.563 0 1 NA NA
#> Item_3 0.000 1 0 0.303 0 1 NA NA
#> Item_4 0.000 1 0 0.661 0 1 NA NA
#> Item_5 0.000 1 0 0.393 0 1 NA NA
#> Item_6 0.000 1 0 -0.105 0 1 NA NA
#> Item_7 0.000 1 0 1.405 0 1 NA NA
#> Item_8 0.000 1 0 -0.147 0 1 NA NA
#> Item_9 0.000 1 0 2.014 0 1 NA NA
#> Item_10 0.000 0 1 -0.140 0 1 NA NA
#> Item_11 0.000 0 1 1.228 0 1 NA NA
#> Item_12 0.000 0 1 2.351 0 1 NA NA
#> Item_13 0.000 0 1 -1.430 0 1 NA NA
#> Item_14 0.000 0 1 -0.193 0 1 NA NA
#> Item_15 0.000 0 1 -0.098 0 1 NA NA
#> Item_16 0.000 0 1 0.623 0 1 NA NA
#> Item_17 0.000 0 1 -0.286 0 1 NA NA
#> Item_18 0.000 0 1 -2.594 0 1 NA NA
#> Item_19 0.000 1 1 NA 0 1 0 0
#> Item_20 0.924 1 1 NA 0 1 0 0
#> Item_21 0.000 1 1 NA 0 1 0 0
#> Item_22 0.000 1 1 NA 0 1 0 0
#> Item_23 0.924 1 1 NA 0 1 0 0
#> Item_24 0.000 1 1 NA 0 1 0 0
#> Item_25 0.000 1 1 NA 0 1 0 0
#> Item_26 0.924 1 1 NA 0 1 0 0
#> Item_27 0.000 1 1 NA 0 1 0 0
#> Item_28 0.000 1 1 NA 0 1 0 0
#> Item_29 0.924 1 1 NA 0 1 0 0
#> Item_30 0.000 1 1 NA 0 1 0 0
#>
#> $means
#> theta1 theta2
#> 0 0
#>
#> $cov
#> theta1 theta2
#> theta1 0.919 0.074
#> theta2 0.074 0.988
#>
coef(mltm, printSE=TRUE)
#> $Item_1
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 1.314 -999 999
#> SE NA NA NA 0.054 NA NA
#>
#> $Item_2
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 -0.563 -999 999
#> SE NA NA NA 0.049 NA NA
#>
#> $Item_3
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 0.303 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_4
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 0.661 -999 999
#> SE NA NA NA 0.049 NA NA
#>
#> $Item_5
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 0.393 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_6
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 -0.105 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_7
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 1.405 -999 999
#> SE NA NA NA 0.055 NA NA
#>
#> $Item_8
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 -0.147 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_9
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 2.014 -999 999
#> SE NA NA NA 0.063 NA NA
#>
#> $Item_10
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 -0.140 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_11
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 1.228 -999 999
#> SE NA NA NA 0.053 NA NA
#>
#> $Item_12
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 2.351 -999 999
#> SE NA NA NA 0.069 NA NA
#>
#> $Item_13
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 -1.430 -999 999
#> SE NA NA NA 0.055 NA NA
#>
#> $Item_14
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 -0.193 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_15
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 -0.098 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_16
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 0.623 -999 999
#> SE NA NA NA 0.050 NA NA
#>
#> $Item_17
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 -0.286 -999 999
#> SE NA NA NA 0.049 NA NA
#>
#> $Item_18
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 -2.594 -999 999
#> SE NA NA NA 0.074 NA NA
#>
#> $Item_19
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_20
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_21
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_22
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_23
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_24
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_25
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_26
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_27
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_28
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_29
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_30
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $GroupPars
#> MEAN_1 MEAN_2 COV_11 COV_21 COV_22
#> par 0 0 0.919 0.074 0.988
#> SE NA NA 0.047 0.029 0.045
#>
anova(mltm, mod) # similar fit; hence more constrained version preferred
#> AIC SABIC HQ BIC logLik X2 df p
#> mltm 87789.31 87858.12 87844.28 87940.73 -43868.65
#> mod 87810.34 87929.44 87905.48 88072.42 -43860.17 16.972 19 0.592
M2(mltm) # goodness of fit
#> M2 df p RMSEA RMSEA_5 RMSEA_95 SRMSR
#> stats 724.3172 439 2.220446e-16 0.01612682 0.01400711 0.01819185 0.03054497
#> TLI CFI
#> stats 0.9760504 0.9758302
head(personfit(mltm))
#> outfit z.outfit infit z.infit Zh
#> 1 0.4099099 -2.3020946 0.5059333 -2.9261987 2.2862271
#> 2 1.9123381 2.2520122 1.2180485 1.0684326 -1.5047068
#> 3 0.6286134 -0.8426796 0.7783420 -0.9888075 1.0049593
#> 4 0.7758581 -0.9554195 0.8563429 -0.8899482 0.9411026
#> 5 0.7022092 -0.8066743 0.8190887 -0.9254924 0.9442140
#> 6 0.4515079 -1.3679129 0.5692678 -1.6827417 1.4501640
residuals(mltm)
#> LD matrix (lower triangle) and standardized residual correlations (upper triangle)
#>
#> Upper triangle summary:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> -0.064 -0.024 -0.007 0.000 0.019 0.174
#>
#> Item_1 Item_2 Item_3 Item_4 Item_5 Item_6 Item_7 Item_8 Item_9 Item_10
#> Item_1 -0.010 -0.027 -0.040 -0.031 0.029 0.000 0.003 -0.012 0.098
#> Item_2 0.229 0.008 0.013 0.041 0.049 0.015 0.003 -0.004 0.142
#> Item_3 1.788 0.156 -0.025 -0.007 -0.012 0.012 -0.014 -0.015 0.174
#> Item_4 3.964 0.437 1.577 -0.006 0.014 -0.014 0.008 0.018 0.134
#> Item_5 2.393 4.302 0.134 0.085 0.021 0.010 -0.015 -0.005 0.154
#> Item_6 2.036 5.900 0.344 0.505 1.137 0.005 -0.012 -0.003 0.127
#> Item_7 0.000 0.581 0.363 0.498 0.261 0.064 0.005 0.006 0.134
#> Item_8 0.029 0.019 0.490 0.155 0.560 0.341 0.075 -0.011 0.166
#> Item_9 0.389 0.035 0.534 0.827 0.072 0.029 0.097 0.280 0.093
#> Item_10 23.809 50.189 75.667 44.656 59.645 40.070 45.056 68.776 21.841
#> Item_11 0.009 0.716 0.194 0.626 0.034 0.175 0.028 0.385 0.126 1.843
#> Item_12 0.753 0.236 3.918 0.095 1.109 0.582 0.818 1.181 5.494 0.011
#> Item_13 1.267 4.570 0.152 0.017 0.396 2.507 3.411 0.105 2.038 3.111
#> Item_14 7.361 0.214 0.172 0.934 1.965 4.761 4.570 0.319 3.784 1.714
#> Item_15 0.081 0.605 1.939 0.315 0.397 0.037 0.590 0.408 0.605 0.871
#> Item_16 1.749 0.256 2.779 0.965 1.745 0.134 2.493 0.001 3.477 0.281
#> Item_17 3.492 0.001 0.804 0.708 0.094 2.145 3.168 6.440 0.076 6.330
#> Item_18 1.296 0.205 0.068 0.911 0.003 0.029 0.301 0.309 0.158 0.447
#> Item_19 1.950 1.095 0.940 1.227 3.901 2.358 0.879 2.427 1.078 0.912
#> Item_20 0.821 1.556 0.836 0.291 0.071 0.862 1.370 0.069 6.617 0.072
#> Item_21 3.887 1.725 3.272 1.120 1.616 0.749 1.266 0.857 0.744 4.508
#> Item_22 2.670 0.247 0.016 4.552 0.345 0.736 0.650 0.010 0.030 1.904
#> Item_23 1.723 2.043 0.011 0.415 0.958 0.032 0.670 0.042 0.005 3.678
#> Item_24 6.039 2.418 3.100 6.560 2.357 5.733 2.198 2.200 4.635 7.501
#> Item_25 0.562 0.795 0.373 4.838 1.043 3.118 0.468 1.310 0.631 11.477
#> Item_26 4.256 1.169 0.889 0.700 1.184 0.633 3.494 1.488 3.177 20.873
#> Item_27 0.025 0.170 0.067 0.374 2.965 0.050 0.179 0.187 2.212 30.192
#> Item_28 2.586 7.102 3.183 2.042 2.136 2.200 2.730 3.809 2.120 13.578
#> Item_29 1.392 0.557 1.223 0.458 0.710 1.588 2.200 0.723 3.080 11.310
#> Item_30 0.831 1.556 1.214 0.302 0.109 0.449 0.573 0.340 0.424 20.892
#> Item_11 Item_12 Item_13 Item_14 Item_15 Item_16 Item_17 Item_18 Item_19
#> Item_1 0.002 -0.017 -0.023 -0.054 -0.006 -0.026 -0.037 -0.023 -0.028
#> Item_2 -0.017 -0.010 -0.043 -0.009 -0.016 -0.010 0.000 -0.009 0.021
#> Item_3 0.009 -0.040 0.008 -0.008 0.028 -0.033 -0.018 -0.005 -0.019
#> Item_4 -0.016 -0.006 -0.003 -0.019 -0.011 -0.020 -0.017 0.019 0.022
#> Item_5 -0.004 -0.021 -0.013 -0.028 -0.013 -0.026 0.006 -0.001 0.040
#> Item_6 0.008 -0.015 -0.032 -0.044 0.004 0.007 -0.029 -0.003 0.031
#> Item_7 0.003 0.018 -0.037 -0.043 -0.015 -0.032 -0.036 0.011 0.019
#> Item_8 0.012 -0.022 0.006 -0.011 0.013 0.001 -0.051 -0.011 0.031
#> Item_9 0.007 -0.047 -0.029 -0.039 -0.016 -0.037 0.006 0.008 0.021
#> Item_10 0.027 0.002 0.035 -0.026 0.019 0.011 -0.050 0.013 -0.019
#> Item_11 -0.022 0.022 -0.006 0.009 -0.009 -0.027 0.006 -0.019
#> Item_12 1.214 -0.008 -0.027 0.011 -0.003 -0.014 -0.028 -0.020
#> Item_13 1.222 0.141 -0.013 0.035 0.017 -0.008 -0.027 -0.023
#> Item_14 0.096 1.802 0.404 -0.014 0.018 -0.013 -0.038 -0.042
#> Item_15 0.208 0.293 3.129 0.460 0.021 -0.011 -0.026 0.029
#> Item_16 0.208 0.018 0.759 0.815 1.060 -0.007 -0.003 -0.019
#> Item_17 1.773 0.461 0.180 0.392 0.290 0.140 0.005 -0.023
#> Item_18 0.100 1.944 1.860 3.653 1.691 0.020 0.064 -0.033
#> Item_19 0.913 1.015 1.284 4.468 2.033 0.859 1.304 2.695
#> Item_20 1.446 0.039 0.045 2.772 4.411 0.072 0.042 3.259 0.949
#> Item_21 0.747 0.875 1.773 1.730 0.759 1.420 0.979 1.137 5.069
#> Item_22 0.717 0.201 0.020 0.388 5.866 0.030 0.071 1.091 1.009
#> Item_23 8.564 1.754 4.656 0.443 1.035 0.005 0.173 1.152 0.997
#> Item_24 3.006 2.617 2.265 2.175 2.826 2.329 2.261 4.236 6.280
#> Item_25 0.480 0.827 0.946 0.373 0.576 1.593 2.431 1.596 1.146
#> Item_26 1.356 0.825 1.879 2.200 0.954 1.011 5.500 4.288 1.332
#> Item_27 0.144 1.132 0.112 0.783 0.837 1.936 4.920 3.868 1.314
#> Item_28 2.097 4.981 2.166 2.329 2.583 3.338 2.228 2.049 3.566
#> Item_29 0.736 0.533 1.869 2.544 2.516 1.394 10.093 0.484 5.562
#> Item_30 0.221 0.086 5.871 2.007 0.460 0.201 5.445 2.127 0.862
#> Item_20 Item_21 Item_22 Item_23 Item_24 Item_25 Item_26 Item_27 Item_28
#> Item_1 -0.018 0.039 -0.033 -0.026 0.049 0.015 0.041 0.003 -0.032
#> Item_2 -0.025 -0.026 0.010 0.029 0.031 0.018 0.022 -0.008 0.053
#> Item_3 -0.018 -0.036 0.003 0.002 0.035 0.012 0.019 0.005 -0.036
#> Item_4 -0.011 0.021 0.043 0.013 0.051 -0.044 0.017 0.012 -0.029
#> Item_5 -0.005 -0.025 0.012 -0.020 0.031 -0.020 0.022 -0.034 0.029
#> Item_6 0.019 -0.017 -0.017 0.004 0.048 0.035 -0.016 -0.004 0.030
#> Item_7 -0.023 0.023 -0.016 -0.016 0.030 0.014 -0.037 -0.008 0.033
#> Item_8 0.005 -0.019 0.002 0.004 0.030 -0.023 -0.024 0.009 -0.039
#> Item_9 -0.051 -0.017 -0.003 -0.001 0.043 -0.016 -0.036 0.030 0.029
#> Item_10 -0.005 0.042 0.028 0.038 0.055 0.068 0.091 0.110 0.074
#> Item_11 0.024 -0.017 -0.017 0.059 0.035 -0.014 0.023 0.008 0.029
#> Item_12 -0.004 -0.019 0.009 0.026 -0.032 0.018 0.018 0.021 -0.045
#> Item_13 -0.004 -0.027 -0.003 0.043 -0.030 -0.019 -0.027 0.007 -0.029
#> Item_14 -0.033 -0.026 -0.012 -0.013 0.029 -0.012 -0.030 -0.018 -0.031
#> Item_15 0.042 -0.017 0.048 0.020 -0.034 0.015 -0.020 0.018 -0.032
#> Item_16 0.005 -0.024 0.003 0.001 0.031 0.025 0.020 -0.028 -0.037
#> Item_17 -0.004 0.020 0.005 -0.008 -0.030 -0.031 -0.047 -0.044 -0.030
#> Item_18 -0.036 0.021 0.021 -0.021 0.041 -0.025 -0.041 -0.039 -0.029
#> Item_19 0.019 -0.045 0.020 0.020 -0.050 0.021 -0.023 -0.023 -0.038
#> Item_20 0.021 0.029 0.011 -0.045 -0.015 -0.019 -0.026 -0.036
#> Item_21 1.097 -0.018 0.022 0.041 0.031 -0.023 0.027 0.041
#> Item_22 2.114 0.778 0.023 0.046 0.035 0.016 0.005 -0.033
#> Item_23 0.304 1.176 1.318 0.036 -0.019 0.022 -0.003 0.037
#> Item_24 5.068 4.269 5.374 3.166 0.034 0.050 -0.030 -0.047
#> Item_25 0.569 2.467 3.060 0.871 2.822 0.019 0.020 -0.039
#> Item_26 0.944 1.268 0.663 1.248 6.316 0.862 0.032 0.036
#> Item_27 1.693 1.795 0.068 0.021 2.264 0.969 2.522 -0.033
#> Item_28 3.193 4.110 2.716 3.385 5.434 3.775 3.228 2.749
#> Item_29 0.841 1.320 2.280 2.795 4.367 1.522 2.260 5.717 4.057
#> Item_30 6.126 0.904 0.633 3.421 3.815 0.664 1.371 0.140 3.142
#> Item_29 Item_30
#> Item_1 -0.024 -0.018
#> Item_2 -0.015 0.025
#> Item_3 0.022 0.022
#> Item_4 0.014 -0.011
#> Item_5 0.017 0.007
#> Item_6 -0.025 -0.013
#> Item_7 -0.030 -0.015
#> Item_8 -0.017 -0.012
#> Item_9 -0.035 -0.013
#> Item_10 0.067 0.091
#> Item_11 -0.017 -0.009
#> Item_12 -0.015 -0.006
#> Item_13 -0.027 -0.048
#> Item_14 -0.032 -0.028
#> Item_15 -0.032 0.014
#> Item_16 -0.024 -0.009
#> Item_17 -0.064 -0.047
#> Item_18 -0.014 -0.029
#> Item_19 -0.047 -0.019
#> Item_20 -0.018 -0.050
#> Item_21 -0.023 -0.019
#> Item_22 -0.030 0.016
#> Item_23 -0.033 0.037
#> Item_24 -0.042 -0.039
#> Item_25 -0.025 0.016
#> Item_26 -0.030 0.023
#> Item_27 -0.048 0.007
#> Item_28 -0.040 -0.035
#> Item_29 -0.029
#> Item_30 2.120
# EAP estimates
fscores(mltm) |> head()
#> theta1 theta2
#> [1,] -2.00196417 -0.4814745
#> [2,] 1.13845080 0.3697976
#> [3,] 0.14931598 1.7928620
#> [4,] -1.30231550 -0.2349520
#> [5,] -0.09143038 1.4551914
#> [6,] 1.47204804 1.1222929
# }
# MLTM design only for PC1PL items
itemdesign <- data.frame(t1_difficulty= factor(d1, labels=c('medium', 'easy')),
t2_difficulty=factor(d2, labels=c('hard', 'medium', 'easy')))
rownames(itemdesign) <- colnames(dat)[19:30]
itemdesign
#> t1_difficulty t2_difficulty
#> Item_19 easy hard
#> Item_20 easy medium
#> Item_21 easy easy
#> Item_22 easy hard
#> Item_23 easy medium
#> Item_24 easy easy
#> Item_25 medium hard
#> Item_26 medium medium
#> Item_27 medium easy
#> Item_28 medium hard
#> Item_29 medium medium
#> Item_30 medium easy
# fit MLTM design, leaving first 18 items as 'Rasch' type
mltm <- mirt(dat, syntax, itemtype=itemtype, itemdesign=itemdesign,
item.formula = list(theta1 ~ 0 + t1_difficulty,
theta2 ~ 0 + t2_difficulty), SE=TRUE)
coef(mltm, simplify=TRUE)
#> $items
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> Item_1 0.00 0.000
#> Item_2 0.00 0.000
#> Item_3 0.00 0.000
#> Item_4 0.00 0.000
#> Item_5 0.00 0.000
#> Item_6 0.00 0.000
#> Item_7 0.00 0.000
#> Item_8 0.00 0.000
#> Item_9 0.00 0.000
#> Item_10 0.00 0.000
#> Item_11 0.00 0.000
#> Item_12 0.00 0.000
#> Item_13 0.00 0.000
#> Item_14 0.00 0.000
#> Item_15 0.00 0.000
#> Item_16 0.00 0.000
#> Item_17 0.00 0.000
#> Item_18 0.00 0.000
#> Item_19 3.19 0.000
#> Item_20 3.19 0.000
#> Item_21 3.19 0.000
#> Item_22 3.19 0.000
#> Item_23 3.19 0.000
#> Item_24 3.19 0.000
#> Item_25 0.00 1.031
#> Item_26 0.00 1.031
#> Item_27 0.00 1.031
#> Item_28 0.00 1.031
#> Item_29 0.00 1.031
#> Item_30 0.00 1.031
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> Item_1 0.000 0.000
#> Item_2 0.000 0.000
#> Item_3 0.000 0.000
#> Item_4 0.000 0.000
#> Item_5 0.000 0.000
#> Item_6 0.000 0.000
#> Item_7 0.000 0.000
#> Item_8 0.000 0.000
#> Item_9 0.000 0.000
#> Item_10 0.000 0.000
#> Item_11 0.000 0.000
#> Item_12 0.000 0.000
#> Item_13 0.000 0.000
#> Item_14 0.000 0.000
#> Item_15 0.000 0.000
#> Item_16 0.000 0.000
#> Item_17 0.000 0.000
#> Item_18 0.000 0.000
#> Item_19 0.000 -0.078
#> Item_20 0.000 0.000
#> Item_21 1.857 0.000
#> Item_22 0.000 -0.078
#> Item_23 0.000 0.000
#> Item_24 1.857 0.000
#> Item_25 0.000 -0.078
#> Item_26 0.000 0.000
#> Item_27 1.857 0.000
#> Item_28 0.000 -0.078
#> Item_29 0.000 0.000
#> Item_30 1.857 0.000
#> theta2.t2_difficultymedium a1 a2 d g u d1 d2
#> Item_1 0.000 1 0 1.314 0 1 NA NA
#> Item_2 0.000 1 0 -0.563 0 1 NA NA
#> Item_3 0.000 1 0 0.303 0 1 NA NA
#> Item_4 0.000 1 0 0.661 0 1 NA NA
#> Item_5 0.000 1 0 0.393 0 1 NA NA
#> Item_6 0.000 1 0 -0.105 0 1 NA NA
#> Item_7 0.000 1 0 1.405 0 1 NA NA
#> Item_8 0.000 1 0 -0.147 0 1 NA NA
#> Item_9 0.000 1 0 2.014 0 1 NA NA
#> Item_10 0.000 0 1 -0.140 0 1 NA NA
#> Item_11 0.000 0 1 1.228 0 1 NA NA
#> Item_12 0.000 0 1 2.351 0 1 NA NA
#> Item_13 0.000 0 1 -1.430 0 1 NA NA
#> Item_14 0.000 0 1 -0.193 0 1 NA NA
#> Item_15 0.000 0 1 -0.098 0 1 NA NA
#> Item_16 0.000 0 1 0.623 0 1 NA NA
#> Item_17 0.000 0 1 -0.286 0 1 NA NA
#> Item_18 0.000 0 1 -2.594 0 1 NA NA
#> Item_19 0.000 1 1 NA 0 1 0 0
#> Item_20 0.924 1 1 NA 0 1 0 0
#> Item_21 0.000 1 1 NA 0 1 0 0
#> Item_22 0.000 1 1 NA 0 1 0 0
#> Item_23 0.924 1 1 NA 0 1 0 0
#> Item_24 0.000 1 1 NA 0 1 0 0
#> Item_25 0.000 1 1 NA 0 1 0 0
#> Item_26 0.924 1 1 NA 0 1 0 0
#> Item_27 0.000 1 1 NA 0 1 0 0
#> Item_28 0.000 1 1 NA 0 1 0 0
#> Item_29 0.924 1 1 NA 0 1 0 0
#> Item_30 0.000 1 1 NA 0 1 0 0
#>
#> $means
#> theta1 theta2
#> 0 0
#>
#> $cov
#> theta1 theta2
#> theta1 0.919 0.074
#> theta2 0.074 0.988
#>
coef(mltm, printSE=TRUE)
#> $Item_1
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 1.314 -999 999
#> SE NA NA NA 0.054 NA NA
#>
#> $Item_2
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 -0.563 -999 999
#> SE NA NA NA 0.049 NA NA
#>
#> $Item_3
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 0.303 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_4
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 0.661 -999 999
#> SE NA NA NA 0.049 NA NA
#>
#> $Item_5
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 0.393 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_6
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 -0.105 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_7
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 1.405 -999 999
#> SE NA NA NA 0.055 NA NA
#>
#> $Item_8
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 -0.147 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_9
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 1 0 2.014 -999 999
#> SE NA NA NA 0.063 NA NA
#>
#> $Item_10
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 -0.140 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_11
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 1.228 -999 999
#> SE NA NA NA 0.053 NA NA
#>
#> $Item_12
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 2.351 -999 999
#> SE NA NA NA 0.069 NA NA
#>
#> $Item_13
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 -1.430 -999 999
#> SE NA NA NA 0.055 NA NA
#>
#> $Item_14
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 -0.193 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_15
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 -0.098 -999 999
#> SE NA NA NA 0.048 NA NA
#>
#> $Item_16
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 0.623 -999 999
#> SE NA NA NA 0.050 NA NA
#>
#> $Item_17
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 -0.286 -999 999
#> SE NA NA NA 0.049 NA NA
#>
#> $Item_18
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 0 0
#> SE NA NA
#> theta2.t2_difficultymedium a1 a2 d logit(g) logit(u)
#> par 0 0 1 -2.594 -999 999
#> SE NA NA NA 0.074 NA NA
#>
#> $Item_19
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_20
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_21
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_22
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_23
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_24
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_25
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_26
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_27
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_28
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_29
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $Item_30
#> theta1.t1_difficultyeasy theta1.t1_difficultymedium
#> par 3.190 1.031
#> SE 0.145 0.048
#> theta2.t2_difficultyeasy theta2.t2_difficultyhard
#> par 1.857 -0.078
#> SE 0.065 0.037
#> theta2.t2_difficultymedium a1 a2 d1 d2 logit(g) logit(u)
#> par 0.924 1 1 0 0 -999 999
#> SE 0.046 NA NA NA NA NA NA
#>
#> $GroupPars
#> MEAN_1 MEAN_2 COV_11 COV_21 COV_22
#> par 0 0 0.919 0.074 0.988
#> SE NA NA 0.047 0.029 0.045
#>
anova(mltm, mod) # similar fit; hence more constrained version preferred
#> AIC SABIC HQ BIC logLik X2 df p
#> mltm 87789.31 87858.12 87844.28 87940.73 -43868.65
#> mod 87810.34 87929.44 87905.48 88072.42 -43860.17 16.972 19 0.592
M2(mltm) # goodness of fit
#> M2 df p RMSEA RMSEA_5 RMSEA_95 SRMSR
#> stats 724.3172 439 2.220446e-16 0.01612682 0.01400711 0.01819185 0.03054497
#> TLI CFI
#> stats 0.9760504 0.9758302
head(personfit(mltm))
#> outfit z.outfit infit z.infit Zh
#> 1 0.4099099 -2.3020946 0.5059333 -2.9261987 2.2862271
#> 2 1.9123381 2.2520122 1.2180485 1.0684326 -1.5047068
#> 3 0.6286134 -0.8426796 0.7783420 -0.9888075 1.0049593
#> 4 0.7758581 -0.9554195 0.8563429 -0.8899482 0.9411026
#> 5 0.7022092 -0.8066743 0.8190887 -0.9254924 0.9442140
#> 6 0.4515079 -1.3679129 0.5692678 -1.6827417 1.4501640
residuals(mltm)
#> LD matrix (lower triangle) and standardized residual correlations (upper triangle)
#>
#> Upper triangle summary:
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> -0.064 -0.024 -0.007 0.000 0.019 0.174
#>
#> Item_1 Item_2 Item_3 Item_4 Item_5 Item_6 Item_7 Item_8 Item_9 Item_10
#> Item_1 -0.010 -0.027 -0.040 -0.031 0.029 0.000 0.003 -0.012 0.098
#> Item_2 0.229 0.008 0.013 0.041 0.049 0.015 0.003 -0.004 0.142
#> Item_3 1.788 0.156 -0.025 -0.007 -0.012 0.012 -0.014 -0.015 0.174
#> Item_4 3.964 0.437 1.577 -0.006 0.014 -0.014 0.008 0.018 0.134
#> Item_5 2.393 4.302 0.134 0.085 0.021 0.010 -0.015 -0.005 0.154
#> Item_6 2.036 5.900 0.344 0.505 1.137 0.005 -0.012 -0.003 0.127
#> Item_7 0.000 0.581 0.363 0.498 0.261 0.064 0.005 0.006 0.134
#> Item_8 0.029 0.019 0.490 0.155 0.560 0.341 0.075 -0.011 0.166
#> Item_9 0.389 0.035 0.534 0.827 0.072 0.029 0.097 0.280 0.093
#> Item_10 23.809 50.189 75.667 44.656 59.645 40.070 45.056 68.776 21.841
#> Item_11 0.009 0.716 0.194 0.626 0.034 0.175 0.028 0.385 0.126 1.843
#> Item_12 0.753 0.236 3.918 0.095 1.109 0.582 0.818 1.181 5.494 0.011
#> Item_13 1.267 4.570 0.152 0.017 0.396 2.507 3.411 0.105 2.038 3.111
#> Item_14 7.361 0.214 0.172 0.934 1.965 4.761 4.570 0.319 3.784 1.714
#> Item_15 0.081 0.605 1.939 0.315 0.397 0.037 0.590 0.408 0.605 0.871
#> Item_16 1.749 0.256 2.779 0.965 1.745 0.134 2.493 0.001 3.477 0.281
#> Item_17 3.492 0.001 0.804 0.708 0.094 2.145 3.168 6.440 0.076 6.330
#> Item_18 1.296 0.205 0.068 0.911 0.003 0.029 0.301 0.309 0.158 0.447
#> Item_19 1.950 1.095 0.940 1.227 3.901 2.358 0.879 2.427 1.078 0.912
#> Item_20 0.821 1.556 0.836 0.291 0.071 0.862 1.370 0.069 6.617 0.072
#> Item_21 3.887 1.725 3.272 1.120 1.616 0.749 1.266 0.857 0.744 4.508
#> Item_22 2.670 0.247 0.016 4.552 0.345 0.736 0.650 0.010 0.030 1.904
#> Item_23 1.723 2.043 0.011 0.415 0.958 0.032 0.670 0.042 0.005 3.678
#> Item_24 6.039 2.418 3.100 6.560 2.357 5.733 2.198 2.200 4.635 7.501
#> Item_25 0.562 0.795 0.373 4.838 1.043 3.118 0.468 1.310 0.631 11.477
#> Item_26 4.256 1.169 0.889 0.700 1.184 0.633 3.494 1.488 3.177 20.873
#> Item_27 0.025 0.170 0.067 0.374 2.965 0.050 0.179 0.187 2.212 30.192
#> Item_28 2.586 7.102 3.183 2.042 2.136 2.200 2.730 3.809 2.120 13.578
#> Item_29 1.392 0.557 1.223 0.458 0.710 1.588 2.200 0.723 3.080 11.310
#> Item_30 0.831 1.556 1.214 0.302 0.109 0.449 0.573 0.340 0.424 20.892
#> Item_11 Item_12 Item_13 Item_14 Item_15 Item_16 Item_17 Item_18 Item_19
#> Item_1 0.002 -0.017 -0.023 -0.054 -0.006 -0.026 -0.037 -0.023 -0.028
#> Item_2 -0.017 -0.010 -0.043 -0.009 -0.016 -0.010 0.000 -0.009 0.021
#> Item_3 0.009 -0.040 0.008 -0.008 0.028 -0.033 -0.018 -0.005 -0.019
#> Item_4 -0.016 -0.006 -0.003 -0.019 -0.011 -0.020 -0.017 0.019 0.022
#> Item_5 -0.004 -0.021 -0.013 -0.028 -0.013 -0.026 0.006 -0.001 0.040
#> Item_6 0.008 -0.015 -0.032 -0.044 0.004 0.007 -0.029 -0.003 0.031
#> Item_7 0.003 0.018 -0.037 -0.043 -0.015 -0.032 -0.036 0.011 0.019
#> Item_8 0.012 -0.022 0.006 -0.011 0.013 0.001 -0.051 -0.011 0.031
#> Item_9 0.007 -0.047 -0.029 -0.039 -0.016 -0.037 0.006 0.008 0.021
#> Item_10 0.027 0.002 0.035 -0.026 0.019 0.011 -0.050 0.013 -0.019
#> Item_11 -0.022 0.022 -0.006 0.009 -0.009 -0.027 0.006 -0.019
#> Item_12 1.214 -0.008 -0.027 0.011 -0.003 -0.014 -0.028 -0.020
#> Item_13 1.222 0.141 -0.013 0.035 0.017 -0.008 -0.027 -0.023
#> Item_14 0.096 1.802 0.404 -0.014 0.018 -0.013 -0.038 -0.042
#> Item_15 0.208 0.293 3.129 0.460 0.021 -0.011 -0.026 0.029
#> Item_16 0.208 0.018 0.759 0.815 1.060 -0.007 -0.003 -0.019
#> Item_17 1.773 0.461 0.180 0.392 0.290 0.140 0.005 -0.023
#> Item_18 0.100 1.944 1.860 3.653 1.691 0.020 0.064 -0.033
#> Item_19 0.913 1.015 1.284 4.468 2.033 0.859 1.304 2.695
#> Item_20 1.446 0.039 0.045 2.772 4.411 0.072 0.042 3.259 0.949
#> Item_21 0.747 0.875 1.773 1.730 0.759 1.420 0.979 1.137 5.069
#> Item_22 0.717 0.201 0.020 0.388 5.866 0.030 0.071 1.091 1.009
#> Item_23 8.564 1.754 4.656 0.443 1.035 0.005 0.173 1.152 0.997
#> Item_24 3.006 2.617 2.265 2.175 2.826 2.329 2.261 4.236 6.280
#> Item_25 0.480 0.827 0.946 0.373 0.576 1.593 2.431 1.596 1.146
#> Item_26 1.356 0.825 1.879 2.200 0.954 1.011 5.500 4.288 1.332
#> Item_27 0.144 1.132 0.112 0.783 0.837 1.936 4.920 3.868 1.314
#> Item_28 2.097 4.981 2.166 2.329 2.583 3.338 2.228 2.049 3.566
#> Item_29 0.736 0.533 1.869 2.544 2.516 1.394 10.093 0.484 5.562
#> Item_30 0.221 0.086 5.871 2.007 0.460 0.201 5.445 2.127 0.862
#> Item_20 Item_21 Item_22 Item_23 Item_24 Item_25 Item_26 Item_27 Item_28
#> Item_1 -0.018 0.039 -0.033 -0.026 0.049 0.015 0.041 0.003 -0.032
#> Item_2 -0.025 -0.026 0.010 0.029 0.031 0.018 0.022 -0.008 0.053
#> Item_3 -0.018 -0.036 0.003 0.002 0.035 0.012 0.019 0.005 -0.036
#> Item_4 -0.011 0.021 0.043 0.013 0.051 -0.044 0.017 0.012 -0.029
#> Item_5 -0.005 -0.025 0.012 -0.020 0.031 -0.020 0.022 -0.034 0.029
#> Item_6 0.019 -0.017 -0.017 0.004 0.048 0.035 -0.016 -0.004 0.030
#> Item_7 -0.023 0.023 -0.016 -0.016 0.030 0.014 -0.037 -0.008 0.033
#> Item_8 0.005 -0.019 0.002 0.004 0.030 -0.023 -0.024 0.009 -0.039
#> Item_9 -0.051 -0.017 -0.003 -0.001 0.043 -0.016 -0.036 0.030 0.029
#> Item_10 -0.005 0.042 0.028 0.038 0.055 0.068 0.091 0.110 0.074
#> Item_11 0.024 -0.017 -0.017 0.059 0.035 -0.014 0.023 0.008 0.029
#> Item_12 -0.004 -0.019 0.009 0.026 -0.032 0.018 0.018 0.021 -0.045
#> Item_13 -0.004 -0.027 -0.003 0.043 -0.030 -0.019 -0.027 0.007 -0.029
#> Item_14 -0.033 -0.026 -0.012 -0.013 0.029 -0.012 -0.030 -0.018 -0.031
#> Item_15 0.042 -0.017 0.048 0.020 -0.034 0.015 -0.020 0.018 -0.032
#> Item_16 0.005 -0.024 0.003 0.001 0.031 0.025 0.020 -0.028 -0.037
#> Item_17 -0.004 0.020 0.005 -0.008 -0.030 -0.031 -0.047 -0.044 -0.030
#> Item_18 -0.036 0.021 0.021 -0.021 0.041 -0.025 -0.041 -0.039 -0.029
#> Item_19 0.019 -0.045 0.020 0.020 -0.050 0.021 -0.023 -0.023 -0.038
#> Item_20 0.021 0.029 0.011 -0.045 -0.015 -0.019 -0.026 -0.036
#> Item_21 1.097 -0.018 0.022 0.041 0.031 -0.023 0.027 0.041
#> Item_22 2.114 0.778 0.023 0.046 0.035 0.016 0.005 -0.033
#> Item_23 0.304 1.176 1.318 0.036 -0.019 0.022 -0.003 0.037
#> Item_24 5.068 4.269 5.374 3.166 0.034 0.050 -0.030 -0.047
#> Item_25 0.569 2.467 3.060 0.871 2.822 0.019 0.020 -0.039
#> Item_26 0.944 1.268 0.663 1.248 6.316 0.862 0.032 0.036
#> Item_27 1.693 1.795 0.068 0.021 2.264 0.969 2.522 -0.033
#> Item_28 3.193 4.110 2.716 3.385 5.434 3.775 3.228 2.749
#> Item_29 0.841 1.320 2.280 2.795 4.367 1.522 2.260 5.717 4.057
#> Item_30 6.126 0.904 0.633 3.421 3.815 0.664 1.371 0.140 3.142
#> Item_29 Item_30
#> Item_1 -0.024 -0.018
#> Item_2 -0.015 0.025
#> Item_3 0.022 0.022
#> Item_4 0.014 -0.011
#> Item_5 0.017 0.007
#> Item_6 -0.025 -0.013
#> Item_7 -0.030 -0.015
#> Item_8 -0.017 -0.012
#> Item_9 -0.035 -0.013
#> Item_10 0.067 0.091
#> Item_11 -0.017 -0.009
#> Item_12 -0.015 -0.006
#> Item_13 -0.027 -0.048
#> Item_14 -0.032 -0.028
#> Item_15 -0.032 0.014
#> Item_16 -0.024 -0.009
#> Item_17 -0.064 -0.047
#> Item_18 -0.014 -0.029
#> Item_19 -0.047 -0.019
#> Item_20 -0.018 -0.050
#> Item_21 -0.023 -0.019
#> Item_22 -0.030 0.016
#> Item_23 -0.033 0.037
#> Item_24 -0.042 -0.039
#> Item_25 -0.025 0.016
#> Item_26 -0.030 0.023
#> Item_27 -0.048 0.007
#> Item_28 -0.040 -0.035
#> Item_29 -0.029
#> Item_30 2.120
# EAP estimates
fscores(mltm) |> head()
#> theta1 theta2
#> [1,] -2.00196417 -0.4814745
#> [2,] 1.13845080 0.3697976
#> [3,] 0.14931598 1.7928620
#> [4,] -1.30231550 -0.2349520
#> [5,] -0.09143038 1.4551914
#> [6,] 1.47204804 1.1222929
# }